廊坊高端网站制作高端网站设计定制
一、说明
欢迎来到“文本到上下文”博客的第 6 个系列。到目前为止,我们已经探索了自然语言处理的基础知识、应用和挑战。我们深入研究了标记化、文本清理、停用词、词干提取、词形还原、词性标记和命名实体识别。我们的探索包括文本表示技术,如词袋、TF-IDF 和词嵌入的介绍。然后,我们将 NLP 与机器学习联系起来,涵盖监督和无监督学习、情感分析以及分类和回归的基础知识。最近,我们涉足深度学习,讨论了神经网络、RNN 和 LSTM。现在,我们将更深入地研究深度学习领域的单词嵌入。
以下是第 6 篇博文中的预期内容:
- Word2Vec:深入研究 Word2Vec 的世界,探索其架构、工作原理以及它如何彻底改变对文本中语义关系的理解。我们将研究它的两种主要训练算法:连续词袋 (CBOW) 和 Skip-gram,以了解它们在捕获上下文词义中的作用。
- GloVe(单词表示的全局向量):解开 GloVe 模型的复杂性。我们将通过利用全局词-词共现统计来探索它与 Word2Vec 的不同之处,提供一种独特的方法,根据词库中的集体上下文嵌入词。
- 快速文本:研究 FastText 的功能,重点关注其处理词汇外单词的创新方法。了解 FastText 如何将单词分解为更小的单元 (n-gram) 以及此方法如何增强单词的表示,尤其是在具有丰富形态的语言中。
- 正确的嵌入模型:深入了解为您的 NLP 项目选择嵌入模型时要考虑的关键因素。我们将讨论每个模型的细微差别,帮助您确定哪一个模型在语言丰富性、计算效率和应用范围方面最符合您的特定需求。
- 比较 Word Embeddings 代码示例:通过动手实践代码示例将理论付诸实践。本节将提供一个实际演示,比较 Word2Vec、GloVe 和 FastText 在常见 NLP 任务中的性能,让您切实了解它们在实际应用中的优势和劣势。
这篇博文不仅旨在向您介绍这些高级嵌入技术,还旨在为您提供在 NLP 项目中实施这些技术时做出明智决策的知识。
二、Word2Vec
Word2Vec 是一种流行的词嵌入技术,旨在将词表示为高维空间中的连续向量。它引入了两个模型:连续词袋 (CBOW) 和 Skip-gram,每个模型都有助于学习向量表示。
1. 模型架构:
- 连续词袋 (CBOW):在 CBOW 中,模型根据目标词的上下文预测目标词。上下文词用作输入,目标词是输出。该模型经过训练,以最小化预测目标词和实际目标词之间的差异。
- 跳过克: 相反,Skip-gram 模型预测给定目标词的上下文词。目标词用作输入,该模型旨在预测可能出现在其上下文中的词。与 CBOW 一样,目标是最小化预测词和实际上下文词之间的差异。
2. 神经网络训练:
CBOW 和 Skip-gram 模型都利用神经网络来学习向量表示。神经网络在大型文本语料库上进行训练,调整连接的权重以最小化预测误差。此过程将相似的单词在生成的向量空间中更紧密地放在一起。
3. 矢量表示:
训练后,Word2Vec 会在高维空间中为每个单词分配一个唯一的向量。这些向量捕获单词之间的语义关系。具有相似含义的单词或经常出现在类似上下文中的单词具有彼此接近的向量,表明它们的语义相似性。
4.优点和缺点:
优势:
-
有效地捕获语义关系。
-
适用于大型数据集。
-
提供有意义的单词表示形式。
缺点: -
可能会与生僻词作斗争。
-
忽略词序。
5. 玩具数据集代码示例:
提供的代码示例演示了如何使用 Gensim 库在玩具数据集上训练 Word2Vec 模型。展示了句子的标记化、模型训练和对单词嵌入的访问。
# Code Example with Toy Dataset
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize# Toy dataset
sentences = ["I love natural language processing.", "Word embeddings are powerful."]# Tokenize sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]# Train Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, workers=4)# Access embeddings
word_embeddings = model.wv
print(word_embeddings['natural'])
总之,Word2Vec 的机制涉及训练神经网络模型(CBOW 和 Skip-gram)来学习有效捕获单词之间语义关系的向量表示。生成的向量在向量空间中提供了有意义且有效的词表示。
三、GloVe(用于单词表示的全局向量)
全局词表示向量 (GloVe) 是一种强大的词嵌入技术,它通过考虑词在语料库中的共现概率来捕获词之间的语义关系。GloVe有效性的关键在于词语矩阵的构建和后续的因式分解过程。
1. 词语矩阵形成:
GloVe机制的第一步是创建一个词-上下文矩阵。该矩阵旨在表示给定单词在整个语料库中出现在另一个单词附近的可能性。矩阵中的每个单元格都包含单词在特定上下文窗口中一起出现的频率的共现计数。
让我们考虑一个简化的例子。假设我们的语料库中有以下句子:
- “词嵌入捕捉语义含义。”
- “GloVe是一个有影响力的词嵌入模型。”
单词上下文矩阵可能如下所示:
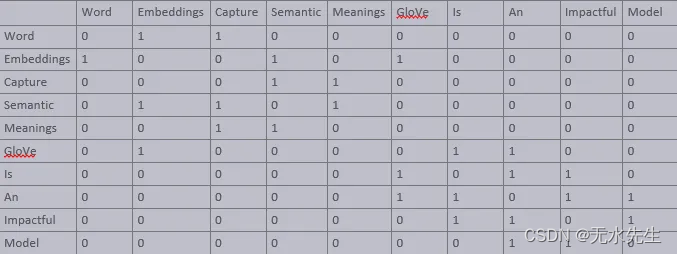
在这里,每一行和每一列对应于语料库中的一个唯一单词,单元格中的值表示这些单词在特定上下文窗口中一起出现的频率。
2. 词向量的因式分解:
有了词语上下文矩阵后,GloVe 转向矩阵分解。这里的目标是将这个高维矩阵分解为两个较小的矩阵——一个代表单词,另一个代表上下文。让我们将它们表示为 W 表示单词,将 C 表示为上下文。理想的情况是当 W 和 CT 的点积(C 的转置)近似于原始矩阵时:
X≈W⋅CT扫描
通过迭代优化,GloVe 调整 W 和 C,以最小化 X 和 W⋅CT 之间的差异。此过程为每个单词生成精细的向量表示,捕获其共现模式的细微差别。
3. 矢量表示:
经过训练后,GloVe为每个单词提供了一个密集的向量,不仅可以捕获本地上下文,还可以捕获全局单词使用模式。这些向量对语义和句法信息进行编码,根据单词在语料库中的整体用法揭示单词之间的相似性和差异性。
4. 优点和缺点:
优势:
-
高效捕获语料库的全局统计数据。
-
善于表示语义和句法关系。
-
有效捕捉词语类比。
缺点: -
需要更多内存来存储共现矩阵。
-
对非常小的语料库效果较差。
5. 玩具数据集代码示例:
以下代码片段演示了在玩具数据集上使用 GloVe Python 包的 GloVe 模型的基本用法。该示例涵盖了共现矩阵的创建、GloVe 模型的训练以及词嵌入的检索。
from glove import Corpus, Glove
from nltk.tokenize import word_tokenize# Toy dataset
sentences = ["Word embeddings capture semantic meanings.","GloVe is an impactful word embedding model."]# Tokenize sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]# Creating a corpus object
corpus = Corpus() # Training the corpus to generate the co-occurrence matrix
corpus.fit(tokenized_sentences, window=10)# Training the GloVe model
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)
glove.add_dictionary(corpus.dictionary)# Retrieve and display word embeddings
word = "glove"
embedding = glove.word_vectors[glove.dictionary[word]]
print(f"Embedding for '{word}': {embedding}")
总之,GloVe的词嵌入方法侧重于在语料库中捕获全局词共现模式,提供丰富而有意义的向量表示。这种方法有效地编码了语义和句法关系,根据其广泛的使用模式提供了对词义的全面视图。上面的代码示例说明了如何在基本数据集上实现 GloVe 嵌入。
四、快速文本
FastText 是由 Facebook AI Research (FAIR) 开发的一种高级单词嵌入技术,它扩展了 Word2Vec 模型。与 Word2Vec 不同,FastText 不仅考虑整个单词,还包含子单词信息——单词的一部分,如 n-gram。这种方法可以处理形态丰富的语言,并更有效地捕获有关单词结构的信息。
1. 子词信息:
FastText 将每个单词表示为除了整个单词本身之外的字符 n-gram 包。这意味着“apple”一词由单词本身及其组成 n 元语法(如“ap”、“pp”、“pl”、“le”等)表示。这种方法有助于捕捉较短单词的含义,并更好地理解后缀和前缀。
2. 模型训练:
与 Word2Vec 类似,FastText 可以使用 CBOW 或 Skip-gram 体系结构。但是,它在训练期间包含子词信息。FastText 中的神经网络经过训练,不仅基于目标单词,还基于这些 n-gram 来预测单词(在 CBOW 中)或上下文(在 Skip-gram 中)。
3. 处理生僻和未知词:
FastText 的一个显着优势是它能够为生僻词甚至在训练期间未看到的单词生成更好的单词表示。通过将单词分解为 n-gram,FastText 可以根据这些单词的子词单元为这些单词构造有意义的表示形式。
4. 优点和缺点:
优势:
-
更好地表示生僻词。
-
能够处理词汇表外的单词。
-
由于子词信息,单词表示更丰富。
缺点: -
由于 n-gram 信息而增加模型大小。
-
与 Word2Vec 相比,训练时间更长。
5. 玩具数据集代码示例:
以下代码演示了如何在玩具数据集上将 FastText 与 Gensim 库一起使用。它突出显示了模型训练和访问词嵌入。
from gensim.models import FastText
from nltk.tokenize import word_tokenize# Toy dataset
sentences = ["FastText embeddings handle subword information.","It is effective for various languages."]
# Tokenize sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]# Train FastText model
model = FastText(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, workers=4)# Access embeddings
word_embeddings = model.wv
print(word_embeddings['subword'])
总之,FastText 通过整合子词信息来丰富单词嵌入景观,使其在捕捉语言中的复杂细节和处理罕见或看不见的单词方面非常有效。
五、选择正确的嵌入模型
Word2Vec:当语义关系至关重要并且您拥有大型数据集时使用。
GloVe:适用于不同的数据集,并且捕获全球上下文很重要。
FastText:选择形态丰富的语言或处理词汇表外的单词至关重要。
六、比较 Word Embeddings 代码示例
# Import necessary libraries
from gensim.models import Word2Vec
from gensim.models import FastText
from glove import Corpus, Glove
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt# Toy dataset
toy_data = ["word embeddings are fascinating","word2vec captures semantic relationships","GloVe considers global context","FastText extends Word2Vec with subword information"
]# Function to train Word2Vec model
def train_word2vec(data):model = Word2Vec([sentence.split() for sentence in data], vector_size=100, window=5, min_count=1, workers=4)return model# Function to train GloVe model
def train_glove(data):corpus = Corpus()corpus.fit(data, window=5)glove = Glove(no_components=100, learning_rate=0.05)glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)return glove# Function to train FastText model
def train_fasttext(data):model = FastText(sentences=[sentence.split() for sentence in data], vector_size=100, window=5, min_count=1, workers=4)return model# Function to plot embeddings
def plot_embeddings(model, title):labels = model.wv.index_to_keyvectors = [model.wv[word] for word in labels]tsne_model = TSNE(perplexity=40, n_components=2, init='pca', n_iter=2500, random_state=23)new_values = tsne_model.fit_transform(vectors)x, y = [], []for value in new_values:x.append(value[0])y.append(value[1])plt.figure(figsize=(10, 8)) for i in range(len(x)):plt.scatter(x[i],y[i])plt.annotate(labels[i],xy=(x[i], y[i]),xytext=(5, 2),textcoords='offset points',ha='right',va='bottom')plt.title(title)plt.show()# Train models
word2vec_model = train_word2vec(toy_data)
glove_model = train_glove(toy_data)
fasttext_model = train_fasttext(toy_data)# Plot embeddings
plot_embeddings(word2vec_model, 'Word2Vec Embeddings')
plot_embeddings(glove_model, 'GloVe Embeddings')
plot_embeddings(fasttext_model, 'FastText Embeddings')
七、 结论
当我们结束对高级词嵌入的探索时,我们 NLP 之旅的下一站将是序列到序列模型、注意力机制和编码器-解码器架构。这些先进的技术在机器翻译和摘要等任务中发挥了重要作用,使模型能够专注于输入序列的特定部分。
请继续关注下一期,我们将揭开序列到序列模型的复杂性,揭示注意力机制和编码器-解码器架构的力量。