asp网站后台下载百度引流推广怎么做
C++ 可以使用 gdb 调试,shell 可以使用 "-x" 跟踪调试参数,
Python 可以使用:pdb(Python 内置)、ipdb、pdbpp、pudb、rpdb、ripdb
- pdb:Python 内置的调试工具。
- ipdb、pdbpp:增强的调试器,将 ipython 引入 pdb 调试。提供语法高亮,更好的用户体验。
- pudb:只支持 Linux 与 macOS 平台。支持 远程调试
- rpdb、ripdb 都支持 远程调试
- Pycharm:其使用内置的pydev调试功能。
- vscode:其使用 ptvsd。
- ipdb、pdbpp 不支持远程调试,
- rpdb、pudb(只支持Linux) 都支持远程调试
- ripdb 只支持 Linux,是将 ipdb 和 rpdb 的功能组合在一个包中,
linux 下推荐 pudb;
window 下推荐 ipdb,其次 pdbpp;
调试的方法多种多样,不同的调试方法适合不同的场景和人群。
- 如果你是刚接触编程的小萌新,对很多工具的使用还不是很熟练,那么 print 和 log 大法好
- 如果你在本地(Win或者Mac)电脑上开发,那么 IDE 的图形化界面调试无疑是最适合的;
- 如果你在服务器上排查BUG,那么使用 PDB 进行无图形界面的调试应该是首选;
- 如果你要在本地进行开发,但是项目的进行需要依赖复杂的服务器环境,那么可以了解下 PyCharm 的远程调试
- 为什么需要远程调试:有时候程序是以后台形式执行,此时没有输出交互,比如 web 开发中的 django、flash 程序是由 uwsgi 管理执行,标准输出已重定向,通常只能通过日志输出信息。这时就需要远程调试。
gdb 调试命令的使用及总结:https://blog.csdn.net/freeking101/article/details/54406982
安装:pip install -i https://pypi.douban.com/simple ipdb pdbpp pudb rpdb ripdb web-pdb
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com ipdb pdbpp pudb rpdb ripdb web-pdb
由于pip 默认使用Python的官方源 pypi.python.org/pypi,导致经常使用pip装包时速度过慢或者无法安装(请求超时)等问题,所以国内用户建议使用 pip 国内源。目前常用的 pip 国内源有:
豆瓣:http://pypi.douban.com/simple/
清华:http://pypi.tuna.tsinghua.edu.cn/simple
http 源执行 pip 时需要加上 --trusted-host pypi.douban.com
https 不需要加提示
- Python3 默认已经安装 pip,如果没有可以下载 get-pip.py 文件执行安装:
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.py -i http://pypi.douban.com --trusted-host pypi.douban.com
1、Python 自带的 pdb 调试
官方文档:https://docs.python.org/zh-cn/3/library/pdb.html

run* 函数 和 set_trace() 都是别名,用于实例化 Pdb类 和调用同名方法。如果要使用其他功能,则必须自己实例化 Pdb类,然后执行:
import pdb;
pdb.Pdb(skip=['django.*']).set_trace() # 等价于 pdb.set_trace()
方法1:python xxx.py
典型用法是导入pdb,调用set_trace() 函数:import pdb; pdb.set_trace()
3.7+ 后新增内置函数 breakpoint() 不用显示导入pdb,即可调用 pdb.set_trace()
breakpoint():https://docs.python.org/zh-cn/3/library/functions.html#breakpoint
示例:
import requestsdef main():req = requests.get("https://httpbin.org/")if req.status_code == 200:breakpoint()req_text = req.textprint(req_text)else:print(req.status_code)passif __name__ == '__main__':main()
直接执行:python zzz.py

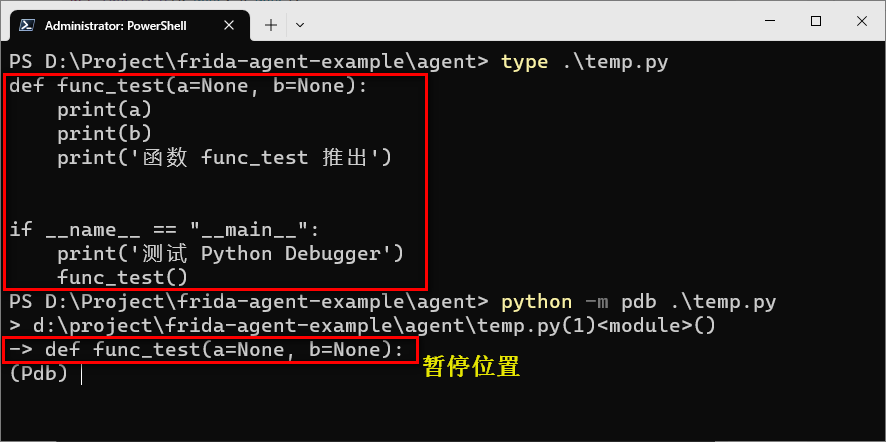
方法 2:python -m pdb xxx.py
不需要导入 pdb,命令行直接执行即可。执行成功后,在第一行暂停并等待调试。
执行命令:python -m pdb xxx.py 或者 python -m ipdb xxx.py
示例:temp.py
def func_test(a=None, b=None):print(a)print(b)print('函数 func_test 推出')if __name__ == "__main__":print('测试 Python Debugger')func_test()
这样程序会自动停在第一行,等待你进行调试。我们可以使用调试命令进行调试,和使用 IED 调试类似。
方法 3:交互式调试:ipython
在 python 交互环境调试。
>>> import pdb
>>> import testPdb
>>> pdb.run('testPdb.test()')
pdb 速查表
- 直接输入Enter,会执行上一条命令;
- 输入PDB 不认识的命令,PDB 会把他当做 Python语句 在当前环境下执行
pdb 调试命令:https://docs.python.org/zh-cn/3/library/pdb.html#debugger-commands

h(elp)
b(reak) [([filename:]lineno | function) [, condition]]
cl(ear) [filename:lineno | bpnumber ...]
disable bpnumber [bpnumber ...]
enable bpnumber [bpnumber ...]
ignore bpnumber [count]
condition bpnumber [condition]
commands [bpnumber] 为编号是 bpnumber 的断点指定一系列命令
s(tep)
n(ext)
unt(il) [lineno] 如果带有 lineno,则继续执行直至行号大于或等于 lineno
r(eturn) 继续运行,直到当前函数返回。
c(ont(inue)) 继续运行,仅在遇到断点时停止。
j(ump) lineno 设置即将运行的下一行,往回跳转,再次运行代码
l(ist) [first[, last]] 列出当前文件的源代码。
ll | longlist 列出当前函数或帧的所有源代码。相关行的标记与 list 相同。
a(rgs) 打印当前函数的参数及其当前的值。
p expression 打印 值。
pp expression 与 p 命令类似,但使用 pprint 模块美观地打印。
whatis expression 打印 expression 的类型。
source expression 尝试获取 expression 的源代码并显示它。
display [expression] 如果 expression 的值发生变化则显示它的值。
undisplay [expression]
interact 启动一个交互式解释器(使用 code 模块),
它的全局命名空间将包含当前作用域中的所有(全局和局部)名称。
! statement 在当前栈帧的上下文中执行 (单行的) statement
run [args ...]
restart [args ...] restart 是 run 的一个别名。如果提供args将被用作新的sys.argv。
q(uit) 退出调试器。 被执行的程序将被中止。
retval 打印当前函数最后一次返回的返回值。
2、Python 调试工具
pdbpp (pdb++) 标准库pdb的拓展
pdb++ 不是有效的包名,所以改成了 pdbpp :https://github.com/pdbpp/pdbpp
pdbpp 是 pdb 标准库的拓展,完全兼容pdb,代码都不需要修改。因为 pdbpp 会自动调用 pdb.py,所以在导入 import pdb 后,pdbpp 会自动可用
安装: pip install pdbpp
在代码中使用时,添加下面代码:
import pdb
pdb.set_trace() # pdb.pdb.set_trace() 是使用 旧版本的 pdb ( 即系统自带 )命令行使用时,不需要添加上面代码,直接执行:python -m pdb xxx.py
命令行调试:python -m pdb xxx.py

如果报错:AttributeError: module ‘collections‘ has no attribute ‘Callable‘
解决方法:进入 python 安装目录 如我的在C盘下修改 py3k_compat.py 这个文件C:\python311\lib\site-packages\pyreadline\py3k_compat.py,在第8行把 return isinstance(x, collections.Callable) 改为 return isinstance(x, collections.abc.Callable) 即可正常使用
参考:https://github.com/hylang/hy/issues/2114
ipdb 是 pdb 的增强版
ipdb:https://pypi.org/project/ipdb/
ipdb 是 pdb 的增强版,提供了补全、语法高亮等功能,适合没有图形界面的终端调试。
相对于 python ,ipython 有漂亮的颜色,和<tab>补全提示,以及 bash 混用;
相对于 python 内置的 pdb,ipdb 的优势也正在于此,其实就是对 ipython 的调用:
安装 ipdb:pip install ipdb
相关方法

在代码中使用时,添加下面代码:
import ipdb
ipdb.set_trace()命令行使用时,不需要添加上面代码,直接执行:python -m ipdb xxx.py
查看 帮助
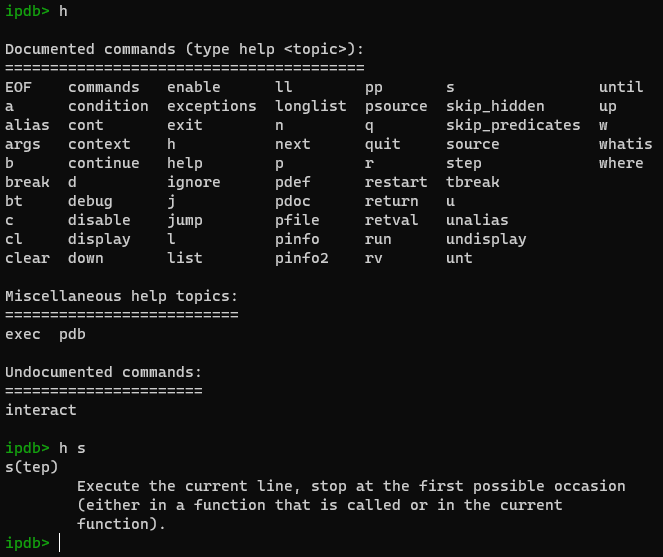
常用命令
enter重复执行上一条命令c继续执行,直到遇到一个断点才停止。a(rgs)打印当前函数的参数l(ist)列出当前将要运行的代码块s(tep) 单步进入,如果当前语句有一个函数调用,则进入函数体中n(ext) 单步跳过,如果当前语句有一个函数调用,则不会进入函数体中r(eturn)继续执行,直到函数体返回j(ump)让程序跳转到指定的行数!<python 命令>p(rint)打印某个变量。最有用的命令之一h(elp)(帮助)q(uit)(帮助)
pudb (只支持Linux) 可视化调试
官方文档
适用于 Python 的全屏控制台调试器:https://github.com/inducer/pudb
官方文档:https://documen.tician.de/pudb/
目录
- 开始调试
- 从单独的终端进行调试
- 记录内部错误
- 远程 调试
- "反向" 远程调试 (pudb 连接到套接字,而不是侦听套接字)
- 调试 多进程
- pytest 的用法
- 启动调试器而不中断
- 处理 断点
- Programming PuDB
- 控制值的显示方式
- 配置 PuDB
- 覆盖默认的键绑定
- Shells
- 内部 shell
- 外部 shells
- 自定义 shells
- 安装
安装:pip install pudb
from pudb import set_trace
set_trace()
执行:python -m pudb xxx.py 执行成功后,界面如下

只要屏幕上的光标不在 "命令行区域",快捷键都可以使用。
移动上下左右的箭头键,可以选中OK

常用的调试命令如下:
- Ctrl+p:打开工具设置界面,可以设置行号等。
- n:next,也就是执行一步
- s:step into,进入函数内部
- c:continue,继续执行,直到遇见下一个断点
- f:执行完当前函数,然后断下。
- b:break point,在光标所在行添加或消除断点
- t:to cursor,运行到光标位置
- ! (或者 Ctrl+x ):打开 python 命令行,可以执行 Python 代码
- ?:shift+? 打开帮助窗口,查看快捷键
- o:查看 输出窗口 / 控制台
- m:module,打开模块
- q:quit,退出 PUDB
- /:搜索
- ,/. 搜索下一个/上一个
其它快捷键

示例:通过 telnet 本地调试、多进程
多进程代码调试利器pudb:https://zhuanlan.zhihu.com/p/107044373
以 multiprocessing 多进程代码示例调试过程:
import os
from multiprocessing import Process
from pudb.remote import set_tracedef info(title):print(title)set_trace()print('module name:', __name__)print('parent process:', os.getppid())print('process id:', os.getpid())def func(name):info('function f')print('hello', name)if __name__ == '__main__':info('main line')p = Process(target=func, args=('bob',))p.start()p.join()
调试子进程:当程序运行至子进程启动处,弹出如下提示
pudb:6899: Please telnet into 127.0.0.1 6899
pudb:6899: Waiting for client...
开启新终端,运行 telnet 命令,会在新终端出现调试界面,就可以进入子进程进行调试。
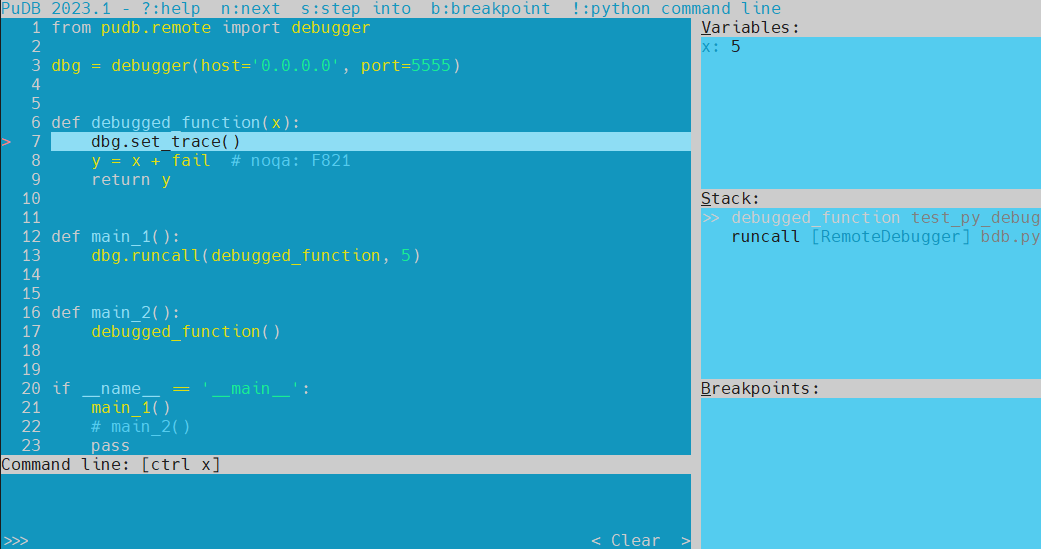
示例:通过 telent 远程调试
示例脚本:
from pudb.remote import debuggerdbg = debugger(host='0.0.0.0', port=5555)def debugged_function(x):dbg.set_trace()y = x + fail # noqa: F821return ydef main_1():dbg.runcall(debugged_function, 5)def main_2():debugged_function()if __name__ == '__main__':main_1()main_2()pass在 主机A(192.168.42.3) 直接直接执行:python xxx.py,

在 主机B 执行:telnet 192.168.42.3 5555,执行成功后直接进入一个新的 pudb 调试界面
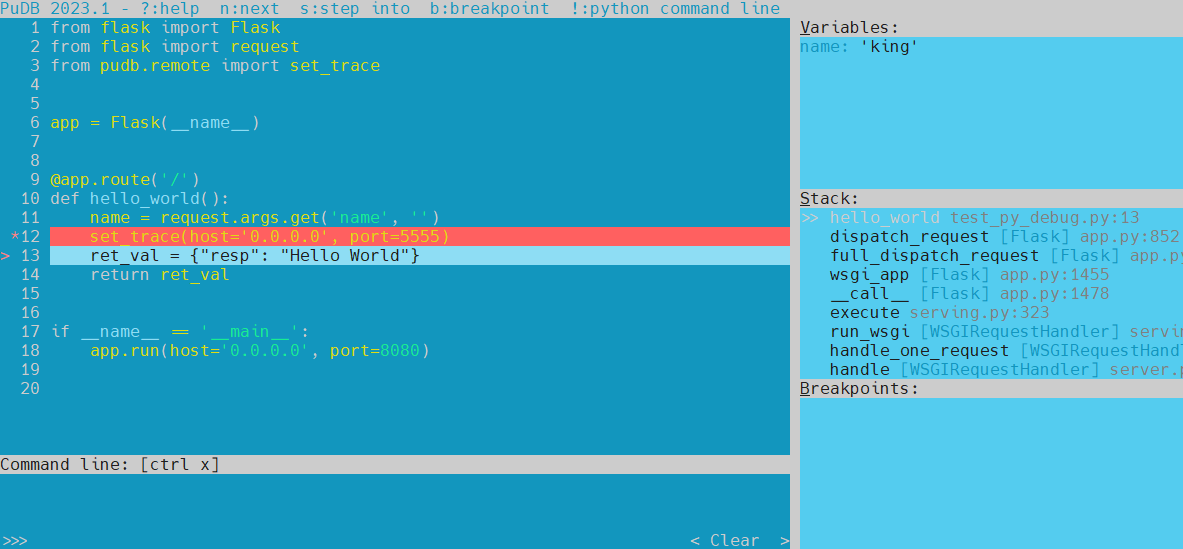
示例:远程 调试 flask
示例代码:
from flask import Flask
from flask import request
from pudb.remote import set_traceapp = Flask(__name__)@app.route('/')
def hello_world():name = request.args.get('name', '')set_trace(host='0.0.0.0', port=5555)ret_val = {"resp": "Hello World"}return ret_valif __name__ == '__main__':app.run(host='0.0.0.0', port=8080)执行脚本:python test_py_debug.py

执行 telnet 连接调试:telnet 192.168.42.3 5555
rpdb:让 pdb 远程调试
rpdb 会开启一个 socket 连接,用于远程调试,默认端口是 4444,当程序断下后,会监听该端口,可远程连接进行调试:nc 127.0.0.1 12345
rpdb 扩展了 pdb,让 pdb 支持远程调试功能。使用了 rpdb 的 python 脚本在远程启动,本地通过 telnet 方式连接上rpdb提供的调试端口,接下来的操作和本地完全一致。
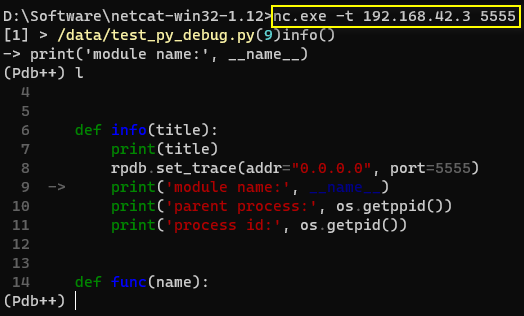
test_py_debug.py 内容如下
import os
from multiprocessing import Process
import rpdbdef info(title):print(title)rpdb.set_trace(addr="0.0.0.0", port=5555)print('module name:', __name__)print('parent process:', os.getppid())print('process id:', os.getpid())def func(name):info('function f')print('hello', name)if __name__ == '__main__':info('main line')p = Process(target=func, args=('bob',))p.start()p.join()
远程服务器上执行:python test_py_debug.py

使用 nc 连接
其他机器上执行 ( 这里通过nc进行远程连接调试 ),后续步骤和 pdb 几乎一样
使用 python -m telnetlib 连接

模块中 __main__.py 是一个特殊的文件,用来标记模块是一个可执行模块。既可以通过 "python -m 模块名" 来执行 __main__.py 文件。
ripdb (只支持Linux)
:https://pypi.org/project/ripdb/
ripdb 是 IPython 调试器的包装器,它将 ipdb 和 rpdb 的功能组合在一个包中,既有远程调试功能,又有漂亮的代码颜色。安装:pip install ripdb
import ripdb
ripdb.set_trace(addr="0.0.0.0", port=12345)
使用 telnet、netcat 或 socat 连接到调试器。
如果要启用 <Tab>自动补全功能,则需要在连接之前禁用多个终端功能:
SAVED_STTY=`stty -g`; stty -icanon -opost -echo -echoe -echok -echoctl -echoke; nc 127.0.0.1 12345; stty $SAVED_STTY
web-pdb
:https://pypi.org/search/?q=pdb
安装:pip install web-pdb
用法:import web_pdb; web_pdb.set_trace()
Web-PDB 是 Python 内置 PDB 调试器的 Web 界面。它允许在 Web 浏览器中远程调试 Python 脚本。
- 基于 Bootstrap 的响应式设计。
- 使用 Prism 突出显示 Python 语法(“Okaida”主题)。
- 支持所有 PDB 功能。
- 标准输入和输出可以重定向到 Web 控制台,以便与 Python 脚本进行远程交互。
- 当前文件框跟踪正在执行的文件中的当前位置。红线编号表示断点(如果有)。
- “全局变量”和“局部变量”框显示当前作用域中的局部变量和全局变量。以双下划线
__开头和结尾的特殊变量被排除在外(您始终可以使用 PDB 命令查看它们)。 - 命令历史记录,最多存储 10 个 (通过箭头向上/向下键访问)

注意:强烈建议仅在一个浏览器会话中使用 Web-PDB Web-UI。当多个浏览器窗口访问 Web UI 时,它可能会在一个或多个浏览器会话中显示不正确的数据。
Web-PDB 与 Python 3.7 中添加的新 breakpoint() 函数兼容。设置环境变量 PYTHONBREAKPOINT="web_pdb.set_trace" 以使用 breakpoint() 启动 Web-PDB。
此外,Web-PDB 还提供 catch_post_mortem 上下文管理器,可以捕获在其范围内引发的未经处理的异常,并自动启动 PDB 事后调试会话。例如:
import web_pdbwith web_pdb.catch_post_mortem():# Some error-prone codeassert foo == bar, 'Oops!'有关 Web-PDB API 的更多详细信息, ./web_pdb/__init__.py 请阅读文件中的文档字符串。
- Web-PDB 提供
inspect或i原始 PDB 中不存在的命令。此命令输出对象成员列表及其值。语法:inspect <object_name>或i <object_name>. - 多线程时,Web-PDB 维护一个仅跟踪一个线程的调试器实例。不应从不同的线程调用
set_trace(),以避免出现争用条件。每个线程都需要一次单独调试一个。 - 多进程时,每个进程都可以有自己的调试器实例,前提是为每个进程调用
set_trace不同的端口值。这样,您可以在单独的浏览器选项卡/窗口中调试每个进程。set_trace(port=端口号)
wdb ( 通过 浏览器 调试 )
wdb - Web Debugger:https://github.com/Kozea/wdb
安装:
pip install wdb.server
pip install wdb
使用 wdb 来调试 python 程序:https://wwj718.github.io/post/编程/debug-with-wdb/
wdb 利用 web 技术,提供直观而友好的UI,不需要记住一堆的命令,就能在错误的上下文中轻松跳转,直至找出问题所在。这种友好的体验和漂亮的UI 和 jupyter(借助 web 技术来帮助 python 开发的神器) 很像:采用 client-server 架构,使用 websocekt 来进行实时通信。
wdb 特点:
- 左边是堆栈,可以随时点击进入。
- 菜单按钮是调试相关按钮
- 强大的 tab 补全
- 对于 Django、Tornado、CherryPy 也可以添加调试
- 支持 远程调试
示例:
from flask import Flask
from flask import requestapp = Flask(__name__)@app.route('/')
def hello_world():name = request.args.get('name', '')import wdb; wdb.set_trace()ret_val = {"resp": name}return ret_valif __name__ == '__main__':app.run(host='0.0.0.0', port=5555)windows 下安装成功后可以直接执行 wdb.exe 启动服务。启动失败时进入 wdb.server.py 所在目录 (\python3.10\Scripts\wdb.server.py )
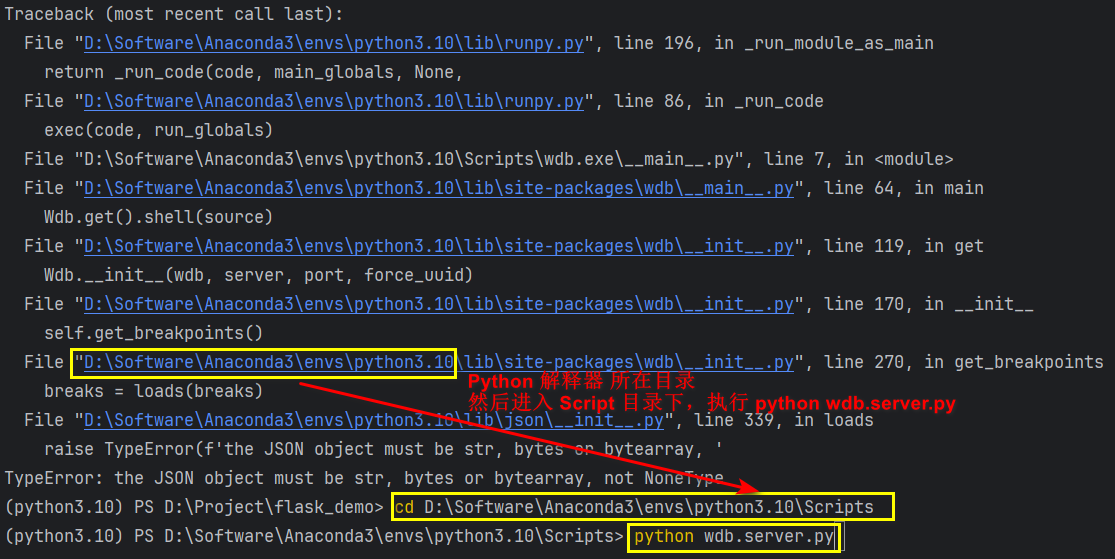
启动服务:python wdb.server.py
在 Python 3.10 及更高版本中,collections 模块被重构,MutableMapping 被移动到了 collections.abc 下,修改 tornado\httputil.py 中 collections.MutableMapping 为 collections.abc.MutableMapping 即可
再次启动服务:python wdb.server.py
在 python3.8+ 版本环境运行下面代码会出现 NotImplementedError 错误,因为Python3.8更改了Windows上的默认事件循环类,该类不支持add_reader和friends。此类问题已经提交到
GitHub上:https://www.cnblogs.com/0110x/p/12516888.html
解决办法就是 Tornado 的 asyncio.py 文件头部添加下面代码:
import asyncio
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
再次启动服务:python wdb.server.py
可以看到执行成功



执行 py 脚本:

浏览器访问,即可自动打开 wdb 的 web 界面

web.server.py
可直接运行
import os
import socket
from logging import DEBUG, INFO, WARNING, getLoggerfrom tornado.ioloop import IOLoop
from tornado.netutil import add_accept_handler, bind_sockets
from tornado.options import options
from tornado_systemd import SYSTEMD_SOCKET_FD, SystemdHTTPServer
from wdb_server import server
from wdb_server.streams import handle_connectionlog = getLogger('wdb_server')
if options.debug:log.setLevel(INFO)if options.more:log.setLevel(DEBUG)
else:log.setLevel(WARNING)if os.getenv('LISTEN_PID'):log.info('Getting socket from systemd')sck = socket.fromfd(SYSTEMD_SOCKET_FD + 1, # Second socket in .socket filesocket.AF_INET6 if socket.has_ipv6 else socket.AF_INET,socket.SOCK_STREAM,)sck.setblocking(0)sck.listen(128)sockets = [sck]
else:log.info('Binding sockets')sockets = bind_sockets(options.socket_port)log.info('Accepting')
for sck in sockets:add_accept_handler(sck, handle_connection)log.info('Listening')
http_server = SystemdHTTPServer(server)
http_server.listen(options.server_port)log.info('Starting loop')
IOLoop.current().start()
wdb.server.py --help
WDB_SOCKET_SERVER # 远程wdb服务主机IP
WDB_SOCKET_PORT # 远程wdb服务主机端口
WDB_WEB_SERVER # 本地wdb服务主机web IP
WDB_WEB_PORT # 本地wdb服务主机web 端口
WDB_NO_BROWSER_AUTO_OPEN # 禁用自动打开浏览器
远程调试
远程调试不需要默认打开本地浏览器,通过 WDB_NO_BROWSER_AUTO_OPEN=True 来控制。
WDB_NO_BROWSER_AUTO_OPEN=True python xxx.py
WDB_NO_BROWSER_AUTO_OPEN=True python -m wdb xxx.py
运行如图:

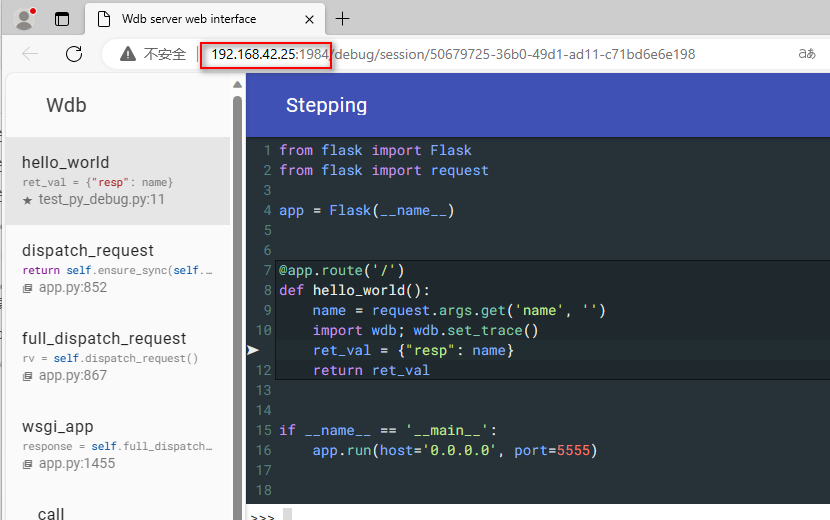
通过打印 log 可知需要浏览器访问 http://[wdb.server]/debug/session/28dca05c-0eac-abcd-8fb0-5546a22e774f,把 [wdb.server] 替换成实际的 IP地址:端口(默认1984),我这里 [wdb.server] 地址是 192.168.42.5,替换后访问 http://192.168.42.5:1984/debug/session/14b586d3-274c-4d3e-a6a7-95dba019999b
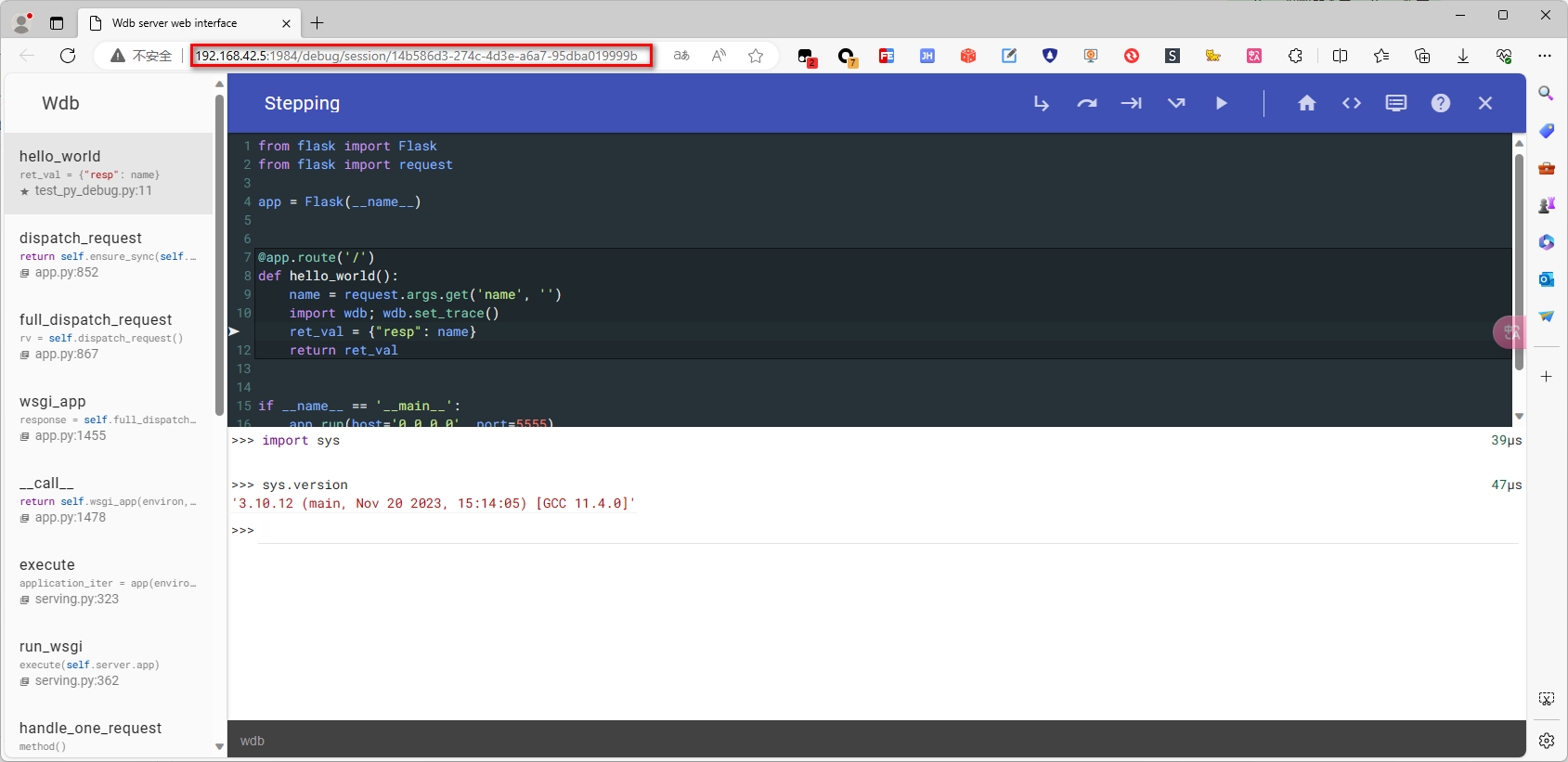
总体步骤:
"wdb 服务" 和 "调试的脚本" 在同一台电脑上
- A 电脑上 "启动 wdb 服务" 并 "启动调试脚本":
启动 wdb 服务:
python wdb.server.py
启动调试脚本:
WDB_NO_BROWSER_AUTO_OPEN=True python xxx.py
WDB_NO_BROWSER_AUTO_OPEN=True python -m wdb xxx.py- B 电脑上浏览器访问 A 电脑上 给出的 URL。
"wdb 服务" 和 "调试的脚本" 不再一台电脑上
- A 电脑 启动 wdb.server 服务:python wdb.server.py
- B 电脑 启动调试脚本,并指定 wdb 服务:WDB_NO_BROWSER_AUTO_OPEN=True WDB_SOCKET_SERVER=192.168.42.25 WDB_SOCKET_PORT=19840 python xxx.py
- C 电脑浏览器访问 B上面的URl,并把 [wdb.server] 替换成 A 的地址即可


PySnooper
安装:pip install pysnooper
PySnooper 把函数运行的过程全部记录了下来,包括:
-
代码的片段、行号等信息,以及每一行代码是何时调用的?
-
函数内局部变量的值如何变化的?何时新增了变量,何时修改了变量。
-
函数的返回值是什么?
-
运行函数消耗了多少时间?
而作为开发者,要得到这些如此详细的调试信息,你需要做的非常简单,只要给你想要调试的函数上带上一顶帽子(装饰器) – @pysnooper.snoop() 即可。
import pysnooper@pysnooper.snoop()
def demo_func():profile = {}profile["name"] = "测试"profile["age"] = 27profile["gender"] = "male"return profiledef main():profile = demo_func()main()
重定向到日志文件
@pysnooper.snoop(output='/var/log/debug.log')
def demo_func():
...
跟踪非局部变量值
out = {"foo": "bar"} # PySnooper 会在
out["foo"]值有变化时,也将其打印出来@pysnooper.snoop(watch=('out["foo"]'))
def demo_func():
...
和 watch 相对的,pysnooper.snoop() 还可以接收一个函数 watch_explode,表示除了这几个参数外的其他所有全局变量都监控。
@pysnooper.snoop(watch_explode=('foo', 'bar'))
def demo_func():
...
设置跟踪函数的深度
PySnooper 是不会跟踪进去函数调用。想继续跟踪该函数中调用的其他函数,可以通过指定 depth 参数来设置跟踪深度(不指定的话默认为 1)。
@pysnooper.snoop(depth=2)
def demo_func():
...
设置调试日志的前缀
@pysnooper.snoop(output="/var/log/debug.log", prefix="demo_func: ")
def demo_func():
...
设置最大的输出长度
默认情况下,PySnooper 输出的变量和异常信息,如果超过 100 个字符,被会截断为 100 个字符。当然你也可以通过指定参数 进行修改,也可以使用max_variable_length=None 使它从不截断它们。
@pysnooper.snoop(max_variable_length=200)
def demo_func():
...
多线程调试模式
设置参数 thread_info=True,它就会在日志中打印出是在哪个线程对变量进行的修改。
@pysnooper.snoop(thread_info=True)
def demo_func():
...
自定义对象的格式输出
pysnooper.snoop() 函数有一个参数是 custom_repr,它接收一个元组对象。在这个元组里,你可以指定特定类型的对象以特定格式进行输出。
假如要跟踪 person 这个 Person 类型的对象,由于它不是常规的 Python 基础类型,PySnooper 是无法正常输出它的信息的。
因此我在 pysnooper.snoop() 函数中设置了 custom_repr 参数,该参数的第一个元素为 Person,第二个元素为 print_persion_obj 函数。
PySnooper 在打印对象的调试信息时,会逐个判断它是否是 Person 类型的对象,若是,就将该对象传入 print_persion_obj 函数中,由该函数来决定如何显示这个对象的信息。
import pysnooperclass Person: passdef print_person_obj(obj):return f"<Person {obj.name} {obj.age} {obj.gender}>"@pysnooper.snoop(custom_repr=(Person, print_person_obj))
def demo_func():person = Person()person.name = "写代码的明哥"person.age = 27person.gender = "male"return persondef main():profile = demo_func()main()
如果自定义格式输出的有很多个类型,那么 custom_repr 参数的值可以这么写
@pysnooper.snoop(custom_repr=((Person, print_person_obj), (numpy.ndarray, print_ndarray)))
def demo_func():
...
提醒一下,元组的第一个元素可以是类型(如类名Person 或者其他基础类型 list等),也可以是一个判断对象类型的函数。
也就是说,下面三种写法是等价的。
# 【第一种写法】
@pysnooper.snoop(custom_repr=(Person, print_persion_obj))
def demo_func():
...
# 【第二种写法】
def is_persion_obj(obj):
return isinstance(obj, Person)@pysnooper.snoop(custom_repr=(is_persion_obj, print_persion_obj))
def demo_func():
...
# 【第三种写法】
@pysnooper.snoop(custom_repr=(lambda obj: isinstance(obj, Person), print_persion_obj))
def demo_func():
...
4、程序的抽样分析器 - Py-Spy
github:https://github.com/benfred/py-spy
Py-Spy 是 Python 程序的抽样分析器,支持可视化查看Python程序在哪些地方花了更多时间,而无需重新启动程序或以任何方式修改代码。还能够生成程序运行时间火焰图,实时显示函数花费的时间等,是分析和优化Python代码的神兵利器。
py-spy 是用 Rust 编写,开销非常低,速度很快,并且与分析的 Python 程序运行在相同的进程中。这意味着 py-spy 可以安全地用于生产 Python 代码。py-spy 可在 Linux、OSX、Windows 和 FreeBSD 上运行,并支持分析所有最新版本的 CPython 解释器
安装:pip install py-spy
使 用
先运行一个程序并获取程序执行后的 pid,然后使用 py-spy 传入相应的 pid,即可一步步分析程序性能,分析存储的火焰图效果,解析代码耗时行为。进而最终进行性能优化。
py-spy --pid 12345 或者 py-spy -- python myprogram.py
默认的可视化是python程序的类似top命令输出的实时视图:

py-spy 有三个子命令:record、top、dump
- record:将采样的记录保存到文件中。可以生成火焰图。

示例:py-spy record -o profile.svg --pid 12345
示例:py-spy record -o profile.svg -- python myprogram.py
执行成功后,会生成一个SVG文件,可以直接使用浏览器打开
- top:实时查看每个函数运行时间并统计,类似 top 命令。
- dump:显示每个python线程的当前调用堆栈
常见问题
为什么我们需要另一个Python分析器?
该项目旨在让您分析和调试任何正在运行的Python程序,即使该程序正在为生产流量提供服务。
虽然还有许多其他python分析项目,但几乎所有项目都需要以某种方式修改被分析的程序。 通常,分析代码在目标python进程内部运行,这将减慢并改变程序的运行方式。 这意味着使用这些分析器来调试生产服务中的问题通常不安全,因为它们通常会对性能产生显着影响。 唯一一个完全在单独进程中运行的Python探查器是pyflame,它通过使用ptrace系统调用来描述远程python进程。 虽然pyflame是一个很棒的项目,但它还不支持Python 3.7,并且不适用于OSX或Windows。
py-spy如何运作?
Py-spy通过使用Linux上的process_vm_readv系统调用,OSX上的vm_read调用或Windows上的ReadProcessMemory调用直接读取python程序的内存。
通过查看全局PyInterpreterState变量来获取Python程序的调用堆栈,以获取在解释器中运行的所有Python线程,然后迭代每个线程中的每个PyFrameObject以获取调用堆栈。 由于Python ABI在不同版本之间发生变化,我们使用rusts的bindgen为我们关心的每个Python interperator类生成不同的rust结构,并使用这些生成的结构来计算Python程序中的内存布局。
由于地址空间布局随机化,获取Python解释器的内存地址可能有点棘手。 如果目标python解释器带有符号,则通过取消引用interp_head或_PyRuntime变量(取决于Python版本),很容易找出解释器的内存地址。 但是,许多Python版本附带了剥离的二进制文件,或者在Windows上没有相应的PDB符号文件。 在这些情况下,我们通过BSS部分扫描看起来像是指向有效PyInterpreterState的地址,并检查该地址的布局是否符合我们的预期。
py-spy配置文件原生扩展?
由于我们通过查看PyInterpreterState来获取python程序的调用堆栈,我们还没有获得有关非python线程的信息,也无法分析像Cython或C ++等语言编写的本机扩展。 本机代码将显示为在调用本机函数的Python行中花费时间,而不是现在它自己的条目。
应该可以使用libunwind之类的东西来分析Python Extensions中的原生代码。 如果这是你感兴趣的事情,请提出这个问题。
你什么时候需要以sudo身份运行?
Py-spy通过从不同的python进程读取内存来工作,出于安全原因,这可能不允许,具体取决于您的操作系统和系统设置。 在许多情况下,以root用户(使用sudo或类似用户)运行可以解决这些安全限制。 OSX总是需要以root身份运行,但在Linux上它取决于你如何启动py-spy和系统安全设置。
在Linux上,默认配置是在附加到非子进程时需要root权限。 对于py-spy,这意味着您可以通过使用py-spy来创建进程(py-spy -- python myprogram.py)从而不需要root权限来分析,但通过指定PID附加到现有进程通常需要root(sudo py-spy -pid 123456)。 您可以通过设置ptrace_scope sysctl变量来消除linux对此的限制。