用cms做单页网站怎么做大作设计网站
【大模型】开源且可商用的大模型通义千问-7B(Qwen-7B)来了
- 新闻
- 通义千问 - 7B 介绍
- 评测表现
- 快速使用
- 环境要求
- 安装相关的依赖库
- 推荐安装flash-attention来提高你的运行效率以及降低显存占用
- 使用 Transformers 运行模型
- 使用 ModelScope 运行模型
- 量化
- 长文本理解
- 参考
新闻
2023年8月3日 在魔搭社区(ModelScope)和Hugging Face同步推出Qwen-7B和Qwen-7B-Chat模型。
通义千问 - 7B 介绍
通义千问-7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。Qwen-7B系列模型的特点包括:
- 大规模高质量预训练数据:我们使用了超过2.2万亿token的自建大规模预训练数据集进行语言模型的预训练。数据集包括文本和代码等多种数据类型,覆盖通用领域和专业领域。
- 优秀的模型性能:相比同规模的开源模型,Qwen-7B在多个评测数据集上具有显著优势,甚至超出12-13B等更大规模的模型。评测评估的能力范围包括自然语言理解与生成、数学运算解题、代码生成等。
- 更好地支持多语言:基于更大词表的分词器在分词上更高效,同时它对其他语言表现更加友好。用户可以在Qwen-7B的基础上更方便地训练特定语言的7B语言模型。
- 8K的上下文长度:Qwen-7B及Qwen-7B-Chat均能支持8K的上下文长度, 允许用户输入更长的prompt。
- 支持插件调用:Qwen-7B-Chat针对插件调用相关的对齐数据做了特定优化,当前模型能有效调用插件以及升级为Agent。
- GitHub 地址
https://github.com/QwenLM/Qwen-7B - huggingface 地址
https://huggingface.co/Qwen/Qwen-7B-Chat
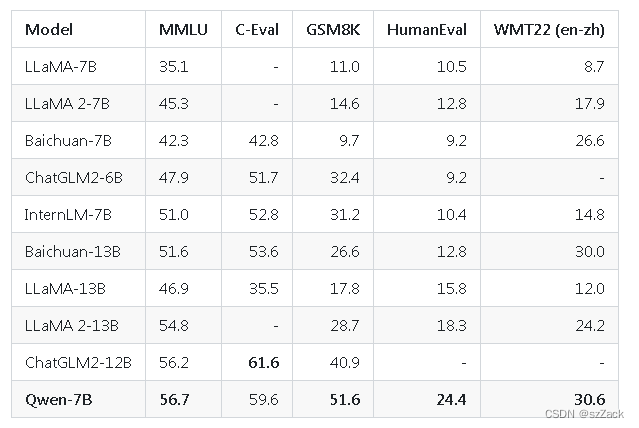
评测表现
Qwen-7B在多个全面评估自然语言理解与生成、数学运算解题、代码生成等能力的评测数据集上,包括MMLU、C-Eval、GSM8K、HumanEval、WMT22等,均超出了同规模大语言模型的表现,甚至超出了如12-13B参数等更大规模的语言模型。
快速使用
环境要求
pytorch>=1.12transformers==4.31.0
安装相关的依赖库
pip install transformers==4.31.0 accelerate tiktoken einops
推荐安装flash-attention来提高你的运行效率以及降低显存占用
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
pip install csrc/layer_norm
pip install csrc/rotary
使用 Transformers 运行模型
先判断当前机器是否支持BF16,命令如下所示:
import torch
torch.cuda.is_bf16_supported()
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
再进行测试:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig# 请注意:我们的分词器做了对特殊token攻击的特殊处理。因此,你不能输入诸如<|endoftext|>这样的token,会出现报错。
# 如需移除此策略,你可以加入这个参数`allowed_special`,可以接收"all"这个字符串或者一个特殊tokens的`set`。
# 举例: tokens = tokenizer(text, allowed_special="all")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# 默认使用fp32精度
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参# 第一轮对话 1st dialogue turn
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。# 第二轮对话 2nd dialogue turn
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。# 第三轮对话 3rd dialogue turn
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
使用 ModelScope 运行模型
魔搭(ModelScope)是开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品。使用ModelScope同样非常简单,代码如下所示:
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope import snapshot_downloadmodel_id = 'QWen/qwen-7b-chat'
revision = 'v1.0.0'model_dir = snapshot_download(model_id, revision)pipe = pipeline(
task=Tasks.chat, model=model_dir, device_map='auto')
history = Nonetext = '浙江的省会在哪里?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
text = '它有什么好玩的地方呢?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
量化
还支持量化,详情查看:【https://github.com/QwenLM/Qwen-7B/blob/main/README_CN.md】
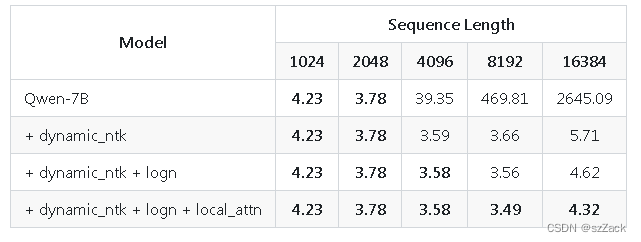
长文本理解
我们引入了NTK插值、窗口注意力、LogN注意力缩放等技术来提升模型的上下文长度并突破训练序列长度的限制。我们的模型已经突破8K的序列长度。通过arXiv数据集上的语言模型实验,我们发现Qwen-7B能够在长序列的设置下取得不错的表现。
参考
- https://github.com/QwenLM/Qwen-7B
- https://huggingface.co/Qwen/Qwen-7B-Chat