dw做网站怎么加视频网站的推广方法有哪些
文章目录
- 一、什么是爬虫?
- 二、爬虫的分类
- 三、网址的构成
- 四、爬虫的基本步骤
- 五、动态页面和静态页面
- 六、伪装请求头
- 七、requests库介绍
- 1. 概念:
- 2. 安装方式(使用镜像源):
- 3. 基本使用:
- 4. response对象对应的方法:
一、什么是爬虫?
通俗讲:爬虫就是解放人的双手,去互联网获取数据,保存数据到本地或者数据库,保存格式如常见的txt、excel、csv、pdf、zip、jpg、mp3、mp4等等。
本质:爬虫本质是模拟浏览器,向服务器发送网络请求,接受服务器放回的数据,保存数据。
二、爬虫的分类
- 通用爬虫:比如百度、Google、搜狗等搜索引擎。
- 聚焦爬虫:根据指定的目标网址,获取精准的价值数据,并保存数据。
三、网址的构成
爬虫既然是模拟浏览器对网址发起请求,那先给大家介绍一下网址的构成。
以该网址为例:https://www.baidu.com/s?ie=UTF-8&wd=python
- 协议部分:https为协议部分,全称为超文本传输安全协议,与之对应的还有http协议。两者区别是http是明文传输、https是密文传输,后者安全性更高。
- 域名部分:域名又称为主机名,通过域名就可以找到对应的这台服务器或者主机。域名本质是IP地址,比如访问www.baidu.com,其实访问的是某个IP地址。只是IP地址是一串数字,不便记忆,所以通过特殊的方式将IP地址转换为域名。
- 路径部分:我们访问某个服务器的信息,比如百度的服务器,其实就是拿到服务器上面某个文件夹里面的数据。类似于我们电脑一样,服务器上面也有众多文件夹,每个文件夹里面还有下级目录,一层嵌套一层,这就称为路径部分。路径在网址中是以“/”分隔开的,以上述网址为例:路径就是/s。如果有多级目录,就是多个/分隔。
- 参数部分:参数就是我们访问网站的时候传递的关键字,比如我们要访问百度服务器中图片里面的风景图片,那请求的时候就要带上参数。参数和路径之间用“?”隔开,如果传递多个参数,每个参数之间用“&”地址符连接。如上网址中,ie=UTF-8和wd=python就是传递的两个参数,中间用“&”连接。
四、爬虫的基本步骤
- 准备网址:https://www.baidu.com/s?ie=UTF-8&wd=python。
- 请求网址:获取网站数据。
- 解析数据:解析价值数据。
- 保存数据:数据保存。
五、动态页面和静态页面
做爬虫项目时,首先要做的就是查看当前网站是静态页面还是动态页面,因为静态页面的数据是在当前页面的源码里面,而动态页面数据不在当前源码,一般是在另外的JS文件中存放。那如何区分网页是动态还是静态页面呢?
- 打开浏览器。
- 访问网址。
- 网页空白处右键点击,查看页面源代码。
- 在网页源代码中搜索网页所展示的部分,如果源码中都有,则为静态页面,否则是动态页面。
六、伪装请求头
多数网站对于爬虫技术是有限制的,并不希望爬虫去访问他的数据,一则是爬虫访问速率太快,容易造成网站负载超荷;二是爬虫并不是真实用户,对于网站经营数据的分析和决策会造成干扰;因而网站会出台各种手段限制爬虫,而如果要使用爬虫技术,则就要突破这些限制,也就是反爬。常用反爬措施有:
- 浏览器标识:我们访问任何网站,一般都是通过电脑或者手机,使用浏览器来访问,这样对方服务器就可以看到我们的设备型号以及浏览器型号,比如通过Windows系统的电脑上的谷歌浏览器去访问某服务器,对方就可以检测到我们的设备操作系统类型及浏览器版本类型等参数,确定了是真实浏览器发送的请求才会给到数据。而爬虫直接访问的话,对方会检测到,所以我们要将自己伪装成浏览器发起请求,也就是将用户代理(user-agent)的值改为浏览器型号。
- 反爬字段:上面我们说过,爬虫是模拟浏览器直接请求网址的,也就是给到他指定的网址,就可以对该网址发起请求。比如我们访问淘宝之后搜索某商品,然后点开其中一个商品,需要抓取这个商品相关的信息。那就将该商品页面网址复制下来,然后用爬虫请求。但是这样是拿不到数据的,很简单,因为正常人去看到这个商品页面,肯定是首先打开淘宝,搜索商品之后,继而点击该商品才可以看到。而爬虫直接就访问了该网址,很明显是反常的。所以网站有专门的反爬字段来检测,这个字段是referer,也就是来源的意思,访问的网址页面是来源于哪里,比如该商品页面是来源于淘宝,那就一定要携带referer字段,值为淘宝网址。如果不携带该字段,则拿不到数据。
- cookies:cookies就是用户登录后,服务器返回给用户的标识信息,在一定时间内,用户再次访问该网站,不需要登录就可以看到登录后的数据。比如我们访问淘宝,要查看购物车中商品信息,则需要输入用户名和密码登录,登录后则可看到购物车数据。登录之后,一段时间内不要再次登录,也可以随时看到购物车信息,因为我们之后的每次访问都是携带了第一次登录后,服务器返回给我们的cookies身份标识,故而不用每次都输入用户名密码登录。做爬虫项目时,我们也会经常遇到需要登录的网站,登录一次之后拿到cookies值,将该cookies保存下来,之后每次访问时候携带上即可。
注意:任何爬虫项目都不得对网站运营造成影响,否则等同于服务器攻击。所以在写爬虫项目时,一定要对爬虫抓取频率和抓取数量加以限制。
七、requests库介绍
1. 概念:
requests是非常强大的爬虫请求库,可以解决日常90%的爬虫需求
2. 安装方式(使用镜像源):
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
3. 基本使用:
- 导包:import requests
- 使用:response = requests.get(url, 反爬请求头)
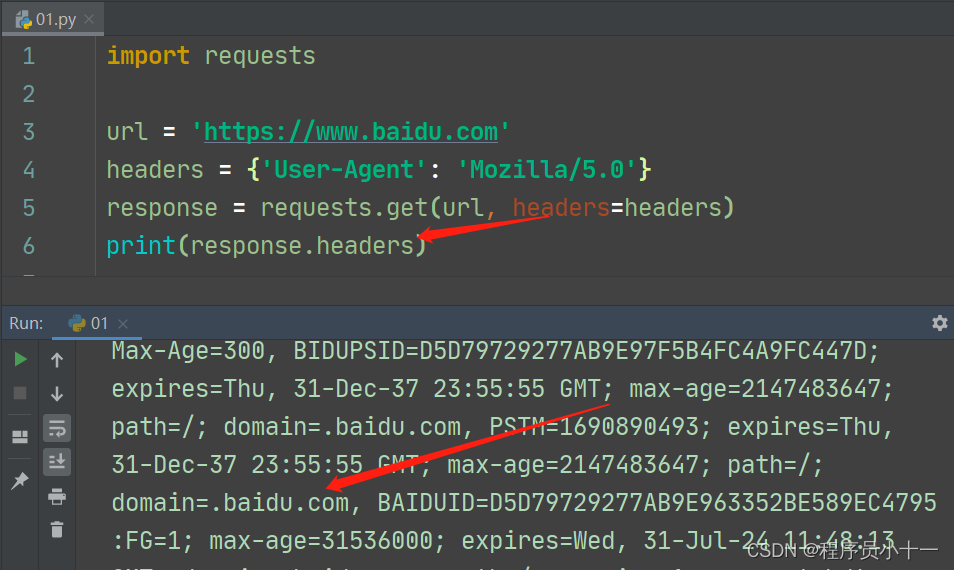
注意:请求拿到的response是一个对象,不是网站原始数据,response对象有众多属性和方法。
代码示例如下图所示:

4. response对象对应的方法:
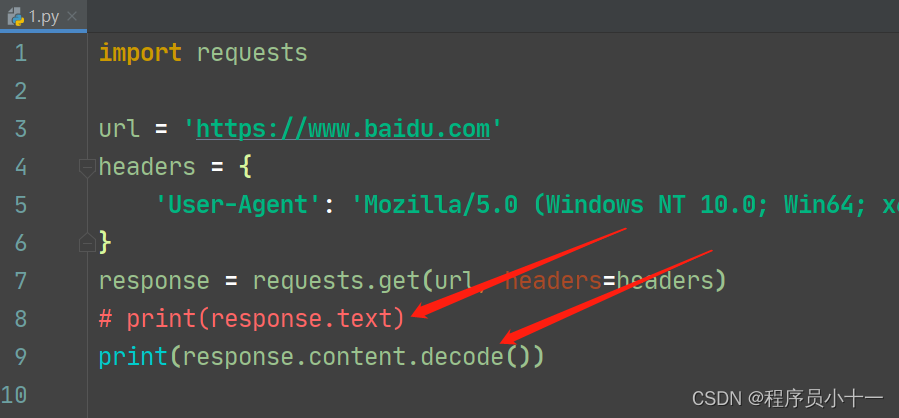
- 获取网页源代码,有两种方法:A、text B、content.decode()
代码示例如下图所示:
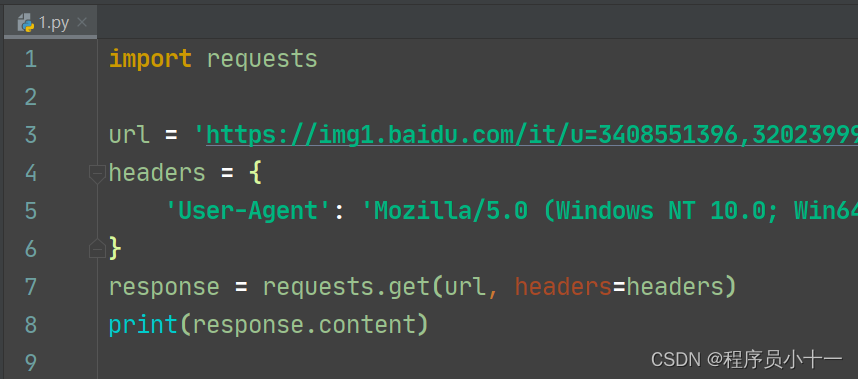
- 获取二进制数据【音乐、视频、图片】:response.content
代码示例如下图所示:
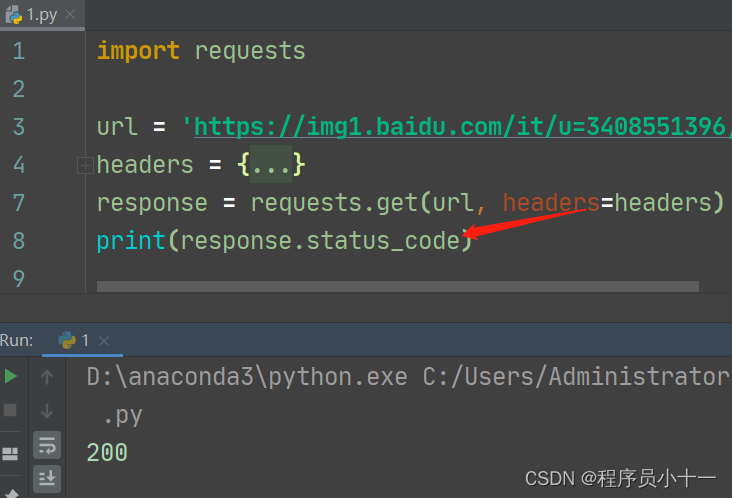
- 获取响应状态码【基本不用】:response.status_code,状态码是200表示请求成功
代码示例如下图所示:
- 获取json数据【常用】:response.json(),网站数据很多都是json数据,拿到数据需要将json转化为字典
- 获取请求头headers:response.request.headers,可以查看我们发送给网站的请求头信息
代码示例如下图所示:

- 获取响应头headers:response.headers,可以看到网站返回的响应头信息
代码示例如下图所示: