网站模版下载跨境电商培训
文章目录
- 摘要
- Abstract
- 1. 引言
- 2. 框架
- 2.1 网络结构
- 2.2 损失函数
- 2.3 训练细节
- 3. 创新点和不足
- 3.1 创新点
- 3.2 不足
- 参考
- 总结
摘要
与Faster R-CNN相比,SSD是一个真正的单阶段多目标检测模型,同时也是一个全卷积网络,不仅检测准确率高,而且检测速度快。SSD显著的优点是使用卷积从不同尺寸的特征图上预测不同尺度、横纵比锚点区域的类别概率分布和偏移量,如此SSD能利用低层特征图较小的感受野和高层特征图较大的感受野来分别检测小物体和大物体。此外,SSD也消除了对候选区域的缩放。尽管SSD有这些优点,但是它也有一个显著的问题——相较于大物体,小物体的检测正确率低。SSD提出了一个解决办法,把图片缩放成 512 × 512 512\times512 512×512再进行检测,如此能提升小物体的检测准确率,但是仍有改进的空间。
Abstract
Compared to Faster R-CNN, SSD is a true single-stage multi-object detection model and also a fully convolutional network, which not only achieves high detection accuracy but also fast detection speed. A significant advantage of SSD is its use of convolution to predict the class probability distribution and offset of anchor boxes with different scales and aspect ratios from feature maps of different sizes. This allows SSD to detect small objects using the smaller receptive fields of lower-level feature maps and large objects using the larger receptive fields of higher-level feature maps. Moreover, SSD eliminates the need for scaling candidate regions. Despite these advantages, SSD has a significant issue—its detection accuracy for small objects is lower than for large objects. SSD proposed a solution by resizing images to 512 × 512 512 \times 512 512×512 for detection, which improves the detection accuracy for small objects, but there is still room for improvement.
1. 引言
以前,先进的目标检测系统都是下面方法的变种:假设边界框、重采样每个框中的像素或特征和应用高质量的分类器。自从选择性搜索和Faster R-CNN在目标检测数据集上取得领先的效果以来,这个管道一直盛行于目标检测。尽管检测正确率很高,但是这些方法的计算量对于嵌入式系统来说还是太大了。即使在高端硬件上,这些方法对于实时检测来说还是太慢了。为了解决上述的问题,研究人员提出了第一个基于单个神经网络模型的物体检测器——SSD。它不需要对边界框内的像素或特征进行重采样,而且达到了和以前方法一样的检测准确率。
2. 框架
2.1 网络结构
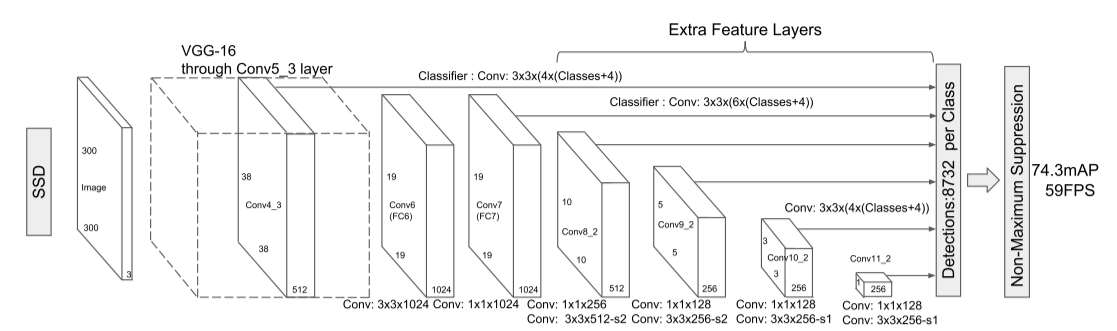
下图是SSD300的结构。
| 编号 | 类型 | 输入尺寸(H,W,C) | 卷积核/池化核 | 输出尺寸(H,W,C) | 激活函数 |
|---|---|---|---|---|---|
| 输入层 | - | 300 × 300 × 3 300\times300\times3 300×300×3 | - | 300 × 300 × 3 300\times300\times3 300×300×3 | - |
| C1 | 卷积层 | 300 × 300 × 3 300\times300\times3 300×300×3 | 64个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 300 × 300 × 64 300\times300\times64 300×300×64 | ReLU |
| C2 | 卷积层 | 300 × 300 × 64 300\times300\times64 300×300×64 | 64个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 300 × 300 × 64 300\times300\times64 300×300×64 | ReLU |
| S3 | 池化层 | 300 × 300 × 64 300\times300\times64 300×300×64 | 2 × 2 2\times2 2×2最大池化核,步长为2 | 150 × 150 × 64 150\times150\times64 150×150×64 | - |
| C4 | 卷积层 | 150 × 150 × 64 150\times150\times64 150×150×64 | 128个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 150 × 150 × 128 150\times150\times128 150×150×128 | ReLU |
| C5 | 卷积层 | 150 × 150 × 128 150\times150\times128 150×150×128 | 128个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 150 × 150 × 128 150\times150\times128 150×150×128 | ReLU |
| S6 | 池化层 | 150 × 150 × 128 150\times150\times128 150×150×128 | 2 × 2 2\times2 2×2最大池化核,步长为2 | 75 × 75 × 128 75\times75\times128 75×75×128 | - |
| C7 | 卷积层 | 75 × 75 × 128 75\times75\times128 75×75×128 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 75 × 75 × 256 75\times75\times256 75×75×256 | ReLU |
| C8 | 卷积层 | 75 × 75 × 256 75\times75\times256 75×75×256 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 75 × 75 × 256 75\times75\times256 75×75×256 | ReLU |
| C9 | 卷积层 | 75 × 75 × 256 75\times75\times256 75×75×256 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 75 × 75 × 256 75\times75\times256 75×75×256 | ReLU |
| S10 | 池化层 | 75 × 75 × 256 75\times75\times256 75×75×256 | 2 × 2 2\times2 2×2最大池化核,步长为2,设置向上取整 | 38 × 38 × 256 38\times38\times256 38×38×256 | - |
| C11 | 卷积层 | 38 × 38 × 256 38\times38\times256 38×38×256 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 38 × 38 × 512 38\times38\times512 38×38×512 | ReLU |
| C12 | 卷积层 | 38 × 38 × 512 38\times38\times512 38×38×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 38 × 38 × 512 38\times38\times512 38×38×512 | ReLU |
| C13 | 卷积层 | 38 × 38 × 512 38\times38\times512 38×38×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 38 × 38 × 512 38\times38\times512 38×38×512 | ReLU |
| S14 | 池化层 | 38 × 38 × 512 38\times38\times512 38×38×512 | 2 × 2 2\times2 2×2最大池化核,步长为2 | 19 × 19 × 512 19\times19\times512 19×19×512 | - |
| C15 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | ReLU |
| C16 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | ReLU |
| C17 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | ReLU |
| S18 | 池化层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 3 × 3 3\times3 3×3最大池化,步长为1,填充为1 | 19 × 19 × 512 19\times19\times512 19×19×512 | - |
| C19 | 卷积层 | 19 × 19 × 512 19\times19\times512 19×19×512 | 1024个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | ReLU |
| C20 | 卷积层 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | 1024个 1 × 1 1\times1 1×1卷积核,步长为1 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | ReLU |
| C21 | 卷积层 | 19 × 19 × 1024 19\times19\times1024 19×19×1024 | 256个 1 × 1 1\times1 1×1卷积核,步长为1 | 19 × 19 × 256 19\times19\times256 19×19×256 | ReLU |
| C22 | 卷积层 | 19 × 19 × 256 19\times19\times256 19×19×256 | 512个 3 × 3 3\times3 3×3卷积核,步长为2,填充为1 | 10 × 10 × 512 10\times10\times512 10×10×512 | ReLU |
| C23 | 卷积层 | 10 × 10 × 512 10\times10\times512 10×10×512 | 128个 1 × 1 1\times1 1×1卷积核,步长为1 | 10 × 10 × 128 10\times10\times128 10×10×128 | ReLU |
| C24 | 卷积层 | 10 × 10 × 128 10\times10\times128 10×10×128 | 256个 3 × 3 3\times3 3×3卷积核,步长为2,填充为1 | 5 × 5 × 256 5\times5\times256 5×5×256 | ReLU |
| C25 | 卷积层 | 5 × 5 × 256 5\times5\times256 5×5×256 | 128个 1 × 1 1\times1 1×1卷积核,步长为1 | 5 × 5 × 128 5\times5\times128 5×5×128 | ReLU |
| C26 | 卷积层 | 5 × 5 × 128 5\times5\times128 5×5×128 | 256个 3 × 3 3\times3 3×3卷积核,步长为1 | 3 × 3 × 256 3\times3\times256 3×3×256 | ReLU |
| C27 | 卷积层 | 3 × 3 × 256 3\times3\times256 3×3×256 | 128个 1 × 1 1\times1 1×1卷积核,步长为1 | 3 × 3 × 128 3\times3\times128 3×3×128 | ReLU |
| C28 | 卷积层 | 3 × 3 × 128 3\times3\times128 3×3×128 | 256个 3 × 3 3\times3 3×3卷积核,步长为1 | 1 × 1 × 256 1\times1\times256 1×1×256 | ReLU |
SSD在C13、C20、C22、C24、C26、C28应用卷积层来获取锚点区域的类别概率分布和偏移量。C20、C22、C24、C26、C28比C13多经历了两次池化,从而导致C13特征图中元素值的范围与其他层不同,因此C13在用卷积层计算类别概率分布和偏移量之前需要进行 L 2 L_2 L2正则化:在每个颜色通道上计算 L 2 L_2 L2范数,然后每个颜色通道上的元素除以该通道上的 L 2 L^2 L2范数,最后乘以一个初始值为20、可学习的缩放系数。
假设数据集中目标类别的个数为 c c c,C13在上述的 L 2 L_2 L2正则化后再应用一个卷积核大小为 3 × 3 3\times3 3×3、过滤器个数为 4 × ( c + 4 ) 4\times(c+4) 4×(c+4)的卷积层来获取概率分布和偏移量;C20、C22和C24分别应用一个卷积核大小为 3 × 3 3\times3 3×3、过滤器个数为 6 × ( c + 4 ) 6\times(c+4) 6×(c+4)的卷积层来获取概率分布和偏移量;C26应用一个卷积核大小为 3 × 3 3\times3 3×3、过滤器个数为 4 × ( c + 4 ) 4\times(c+4) 4×(c+4)的卷积层来获取概率分布和偏移量;C28应用一个卷积核大小为 1 × 1 1\times1 1×1、过滤器个数为 4 × ( c + 4 ) 4\times(c+4) 4×(c+4)的卷积层来获取概率分布和偏移量。
SSD中用来计算概率分布和偏移量的特征图拥有不同的尺寸,因此SSD设计了锚点区域的尺度,使其与特征图的实际尺寸无关。假设用来计算概率分布和偏移量的特征图有 m = 6 m=6 m=6个,每个特征图上锚点区域的尺度计算公式为:
s k = s m i n + s m a x − s m i n m − 1 ( k − 1 ) , k ∈ [ 1 , m ] . s_k=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1), k\in [1, m]. sk=smin+m−1smax−smin(k−1),k∈[1,m].
其中 s m i n = 0.2 s_{min}=0.2 smin=0.2, s m a x = 0.9 s_{max}=0.9 smax=0.9。SSD使用了5种不同的横纵比 a r ∈ { 1 , 2 , 3 , 1 2 , 1 3 } a_r\in\{1, 2, 3, \frac{1}{2}, \frac{1}{3}\} ar∈{1,2,3,21,31},锚点区域的宽度和高度的计算公式为:
w k a = s k a r , h k a = s k a r . w_k^a=s_k\sqrt{a_r}, h_k^a=\frac{s_k}{\sqrt{a_r}}. wka=skar,hka=arsk.
此外,当横纵比为1时,额外增加了一种尺度 s k ′ = s k s k + 1 s_k'=\sqrt{s_ks_{k+1}} sk′=sksk+1。锚点区域的中心位置的公式为:
x = i + 0.5 ∣ f k ∣ , y = j + 0.5 ∣ f k ∣ . x=\frac{i+0.5}{|f_k|}, y=\frac{j+0.5}{|f_k|}. x=∣fk∣i+0.5,y=∣fk∣j+0.5.
其中 ∣ f k ∣ |f_k| ∣fk∣是第 k k k个特征图的边长, i , j ∈ [ 0 , ∣ f k ∣ ] i,j\in[0, |f_k|] i,j∈[0,∣fk∣]。
2.2 损失函数
锚点区域的四元组为锚点区域中心坐标、宽和高。如果锚点区域与真实区域的IOU大于0.5,则锚点区域为该真实区域的正例,否则为负例。假设 x i j p = { 1 , 0 } x_{ij}^p=\{1, 0\} xijp={1,0}为第 i i i个锚点区域与第 j j j个类别为 p p p的真实区域的匹配程度,则SSD的损失函数为:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) . L(x, c, l, g)=\frac{1}{N}(L_{conf}(x, c)+\alpha L_{loc}(x, l, g)). L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g)).
其中 N N N是匹配的锚点区域的个数(如果 N = 0 N=0 N=0,则损失为0)。
定位损失为 L l o c ( x , l , g ) = ∑ i ∈ P o s N ∑ m ∈ { c x , c y , w , h } x i j k s m o o t h L 1 ( l i m − g ^ j m ) L_{loc}(x, l, g)=\displaystyle\sum_{i\in Pos}^N \sum_{m\in\{cx, cy, w, h\}}x_{ij}^k smooth_{L_1}(l_i^m-\hat{g}_j^m) Lloc(x,l,g)=i∈Pos∑Nm∈{cx,cy,w,h}∑xijksmoothL1(lim−g^jm),其中 g ^ j c x = g j c x − d i c x d i w \hat{g}_j^{cx}=\displaystyle\frac{g_j^{cx}-d_i^{cx}}{d_i^w} g^jcx=diwgjcx−dicx, g ^ j c y = g j c y − d i c y d i h \hat{g}_j^{cy}=\displaystyle\frac{g_j^{cy}-d_i^{cy}}{d_i^h} g^jcy=dihgjcy−dicy, g ^ j w = l o g ( g j w d i w ) \hat{g}_j^w=log(\displaystyle\frac{g_j^w}{d_i^w}) g^jw=log(diwgjw), g ^ j h = l o g ( g j h d i h ) \hat{g}_j^h=log(\displaystyle\frac{g_j^h}{d_i^h}) g^jh=log(dihgjh)。置信损失为 L c o n f ( x , c ) = − ∑ i ∈ P o s N x i j p l o g ( c ^ i p ) − ∑ i ∈ N e g l o g ( c ^ i 0 ) L_{conf}(x, c)=\displaystyle-\sum_{i\in Pos}^N x_{ij}^plog(\hat{c}_i^p)-\sum_{i\in Neg}log(\hat{c}_i^0) Lconf(x,c)=−i∈Pos∑Nxijplog(c^ip)−i∈Neg∑log(c^i0),其中 c ^ i p = e c i p ∑ p e c i p \hat{c}_i^p=\displaystyle\frac{e^{c_i^p}}{\displaystyle\sum_{p}e^{c_i^p}} c^ip=p∑ecipecip。
2.3 训练细节
在训练过程中,先根据上面提及的置信损失对所有类别是背景的锚点区域进行从高到低的排序,然后从中挑选损失最高的锚点区域,使得负例与正例的样本个数之比为 3 : 1 3:1 3:1。每次训练一轮后重复执行上述操作。
数据增强的操作:1. 使用完整的训练图片;2. 使用与所有物体的最小IOU为0.1、0.3、0.5、0.7或0.9的区域;3. 随机使用一个区域。上面提到的第2种和第3种区域的尺度为原训练图像的0.1倍到1倍,并且横纵比为 1 : 2 1:2 1:2和 2 : 1 2:1 2:1。所有采样后的图片都被重新缩放到固定尺寸,接着以0.5的概率进行水平翻转,最后在图像的对比度、亮度、颜色进行处理。
3. 创新点和不足
3.1 创新点
与基于R-CNN的目标检测模型相比,SSD是一个单阶段检测所有物体类别的模型,也消除了对候选区域的缩放。SSD最显著的优点是使用卷积从不同尺寸的特征图上预测不同尺度、横纵比锚点区域的类别概率分布和偏移量,如此SSD能利用低层特征图较小的感受野和高层特征图较大的感受野来分别检测小物体和大物体。此外,SSD也是一个全卷积网络,能在运行速度快的同时保证极高的检测准确率。
3.2 不足
SSD在检测小物体时的准确率小于检测大物体时的准确率。尽管SSD提出了一个解决办法——把图片的输入尺寸缩放成 512 × 512 512\times512 512×512,但是在小物体检测上仍然具有改进的空间。
参考
Wei Liu, Dragomir Anguelov, Dumitru Erhan, and et al. SSD: Single Shot MultiBox Detector.
总结
SSD以VGG16的卷积部分为基础网络,修改了VGG16卷积部分中最后一层池化层,并在后面添加了几层卷积层,最后在不同特征图上进行卷积来获取锚点区域的类别概率分布和偏移量。SD最显著的优点是使用卷积从不同尺寸的特征图上预测不同尺度、横纵比锚点区域的类别概率分布和偏移量,如此SSD能利用低层特征图较小的感受野和高层特征图较大的感受野来分别检测小物体和大物体。此外,SSD也是一个全卷积网络,能在运行速度快的同时保证极高的检测准确率。