网站模板的好处迅雷磁力链bt磁力天堂下载
目录
一、本文介绍
二、原理介绍
三、核心代码
四、手把手教你添加C3k2WTConv
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
五、正式训练
5.1 yaml文件1
5.2 训练代码
5.3 训练过程截图
六、本文总结
一、本文介绍
本文给大家带来的改进机制是一种新的 卷积层 , 称为WTConv(小波卷积层) ,它利用 小波变换 (WT)来解决卷积神经网络(CNN)在实现大感受野时遇到的过度参数化问题。WTConv的主要目的是通过对输入数据的不同频率带进行处理,使CNN能够更有效地捕捉局部和全局特征,WTConv成功解决了CNN在感受野扩展中的参数膨胀问题,提供了一种更为高效、鲁棒且易于集成的卷积层解决方案,我将其用于二次创新YOLOv11中的C3k2机制可以减少百分之十的参数量和计算量,达到一个可观的轻量化作用 (这种小波Conv对于目前的创新角度来说是非常流行的) 。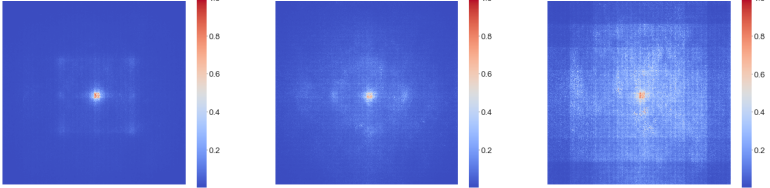
系列专栏 :
YOLOv11改进(更换卷积、添加注意力、更换主干网络、图像去噪、去雾、增强等)涨点系列------发论文必备![]() https://blog.csdn.net/m0_58941767/category_12987736.html?spm=1001.2014.3001.5482
https://blog.csdn.net/m0_58941767/category_12987736.html?spm=1001.2014.3001.5482
二、原理介绍

官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转

这篇名为《用于大感受野的小波卷积》的文章提出了一种新的卷积层,称为WTConv(小波卷积层),它利用小波变换(WT)来解决 卷积神经网络 (CNN)在实现大感受野时遇到的过度参数化问题。WTConv的主要目的是通过对输入数据的不同频率带进行处理,使CNN能够更有效地捕捉局部和全局特征,而传统的CNN主要只能处理局部特征。
以下是文章的主要内容总结:
1. 问题背景:传统的CNN受限于卷积核的大小,难以有效捕捉全局上下文信息。尽管近年来通过增大卷积核(如视觉Transformer)的尝试有所进展,但这通常会导致参数数量激增,模型性能饱和。
2. 提出的解决方案(WTConv):WTConv利用小波变换,通过多频率响应扩展卷积感受野,并在不同频率范围内执行小核卷积操作。通过小波分解,模型可以在更大范围内捕捉低频信息,同时避免模型的过度参数化。
3. 主要优势:
- 参数增长缓慢:与传统方法相比,WTConv的参数数量仅随感受野大小对数级别增长,而不是平方增长。
- 感受野扩大:WTConv通过层级小波分解,能够在不增加大量参数的情况下显著扩大CNN的感受野。
- 形状偏差提升:WTConv层对图像中的低频信息更敏感,从而增强了CNN对形状而非纹理的响应能力。
总的来说,WTConv成功解决了CNN在感受野扩展中的参数膨胀问题,提供了一种更为高效、鲁棒且易于集成的卷积层解决方案。
三、核心代码
import torch.nn as nn
from functools import partial
import pywt
import pywt.data
import torch
import torch.nn.functional as F__all__ = ['C3k2_WTConv']def create_wavelet_filter(wave, in_size, out_size, type=torch.float):w = pywt.Wavelet(wave)dec_hi = torch.tensor(w.dec_hi[::-1], dtype=type)dec_lo = torch.tensor(w.dec_lo[::-1], dtype=type)dec_filters = torch.stack([dec_lo.unsqueeze(0) * dec_lo.unsqueeze(1),dec_lo.unsqueeze(0) * dec_hi.unsqueeze(1),dec_hi.unsqueeze(0) * dec_lo.unsqueeze(1),dec_hi.unsqueeze(0) * dec_hi.unsqueeze(1)], dim=0)dec_filters = dec_filters[:, None].repeat(in_size, 1, 1, 1)rec_hi = torch.tensor(w.rec_hi[::-1], dtype=type).flip(dims=[0])rec_lo = torch.tensor(w.rec_lo[::-1], dtype=type).flip(dims=[0])rec_filters = torch.stack([rec_lo.unsqueeze(0) * rec_lo.unsqueeze(1),rec_lo.unsqueeze(0) * rec_hi.unsqueeze(1),rec_hi.unsqueeze(0) * rec_lo.unsqueeze(1),rec_hi.unsqueeze(0) * rec_hi.unsqueeze(1)], dim=0)rec_filters = rec_filters[:, None].repeat(out_size, 1, 1, 1)return dec_filters, rec_filtersdef wavelet_transform(x, filters):b, c, h, w = x.shapepad = (filters.shape[2] // 2 - 1, filters.shape[3] // 2 - 1)x = F.conv2d(x, filters, stride=2, groups=c, padding=pad)x = x.reshape(b, c, 4, h // 2, w // 2)return xdef inverse_wavelet_transform(x, filters):b, c, _, h_half, w_half = x.shapepad = (filters.shape[2] // 2 - 1, filters.shape[3] // 2 - 1)x = x.reshape(b, c * 4, h_half, w_half)x = F.conv_transpose2d(x, filters, stride=2, groups=c, padding=pad)return xclass WTConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=5, stride=1, bias=True, wt_levels=1, wt_type='db1'):super(WTConv2d, self).__init__()assert in_channels == out_channelsself.in_channels = in_channelsself.wt_levels = wt_levelsself.stride = strideself.dilation = 1self.wt_filter, self.iwt_filter = create_wavelet_filter(wt_type, in_channels, in_channels, torch.float)self.wt_filter = nn.Parameter(self.wt_filter, requires_grad=False)self.iwt_filter = nn.Parameter(self.iwt_filter, requires_grad=False)self.wt_function = partial(wavelet_transform, filters=self.wt_filter)self.iwt_function = partial(inverse_wavelet_transform, filters=self.iwt_filter)self.base_conv = nn.Conv2d(in_channels, in_channels, kernel_size, padding='same', stride=1, dilation=1,groups=in_channels, bias=bias)self.base_scale = _ScaleModule([1, in_channels, 1, 1])self.wavelet_convs = nn.ModuleList([nn.Conv2d(in_channels * 4, in_channels * 4, kernel_size, padding='same', stride=1, dilation=1,groups=in_channels * 4, bias=False) for _ in range(self.wt_levels)])self.wavelet_scale = nn.ModuleList([_ScaleModule([1, in_channels * 4, 1, 1], init_scale=0.1) for _ in range(self.wt_levels)])if self.stride > 1:self.stride_filter = nn.Parameter(torch.ones(in_channels, 1, 1, 1), requires_grad=False)self.do_stride = lambda x_in: F.conv2d(x_in, self.stride_filter, bias=None, stride=self.stride,groups=in_channels)else:self.do_stride = Nonedef forward(self, x):x_ll_in_levels = []x_h_in_levels = []shapes_in_levels = []curr_x_ll = xfor i in range(self.wt_levels):curr_shape = curr_x_ll.shapeshapes_in_levels.append(curr_shape)if (curr_shape[2] % 2 > 0) or (curr_shape[3] % 2 > 0):curr_pads = (0, curr_shape[3] % 2, 0, curr_shape[2] % 2)curr_x_ll = F.pad(curr_x_ll, curr_pads)curr_x = self.wt_function(curr_x_ll)curr_x_ll = curr_x[:, :, 0, :, :]shape_x = curr_x.shapecurr_x_tag = curr_x.reshape(shape_x[0], shape_x[1] * 4, shape_x[3], shape_x[4])curr_x_tag = self.wavelet_scale[i](self.wavelet_convs[i](curr_x_tag))curr_x_tag = curr_x_tag.reshape(shape_x)x_ll_in_levels.append(curr_x_tag[:, :, 0, :, :])x_h_in_levels.append(curr_x_tag[:, :, 1:4, :, :])next_x_ll = 0for i in range(self.wt_levels - 1, -1, -1):curr_x_ll = x_ll_in_levels.pop()curr_x_h = x_h_in_levels.pop()curr_shape = shapes_in_levels.pop()curr_x_ll = curr_x_ll + next_x_llcurr_x = torch.cat([curr_x_ll.unsqueeze(2), curr_x_h], dim=2)next_x_ll = self.iwt_function(curr_x)next_x_ll = next_x_ll[:, :, :curr_shape[2], :curr_shape[3]]x_tag = next_x_llassert len(x_ll_in_levels) == 0x = self.base_scale(self.base_conv(x))x = x + x_tagif self.do_stride is not None:x = self.do_stride(x)return xclass _ScaleModule(nn.Module):def __init__(self, dims, init_scale=1.0, init_bias=0):super(_ScaleModule, self).__init__()self.dims = dimsself.weight = nn.Parameter(torch.ones(*dims) * init_scale)self.bias = Nonedef forward(self, x):return torch.mul(self.weight, x)class Bottleneck(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):"""Applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))def autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class Bottleneck_WTConv(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)if c_ == c2:self.cv2 = WTConv2d(c_, c2, 5, 1)else:self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C2f(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))class C3(nn.Module):"""CSP Bottleneck with 3 convolutions."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))def forward(self, x):"""Forward pass through the CSP bottleneck with 2 convolutions."""return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))class C3k(C3):"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):"""Initializes the C3k module with specified channels, number of layers, and configurations."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channels# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))self.m = nn.Sequential(*(Bottleneck_WTConv(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))class C3k2_WTConv(C2f):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""super().__init__(c1, c2, n, shortcut, g, e)self.m = nn.ModuleList(C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck_WTConv(self.c, self.c, shortcut, g) for _ in range(n))if __name__ == "__main__":# Generating Sample imageimage_size = (1, 64, 240, 240)image = torch.rand(*image_size)# Modelmobilenet_v1 = C3k2_WTConv(64, 64)out = mobilenet_v1(image)print(out.size())四、手把手教你添加C3k2WTConv
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn文件夹下建立一个目录名字呢就是'Addmodules'文件夹,然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py' ,然后在其内部导入我们的检测头如下图所示。
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块 !
4.4 修改四
按照我的添加在parse_model里添加即可。
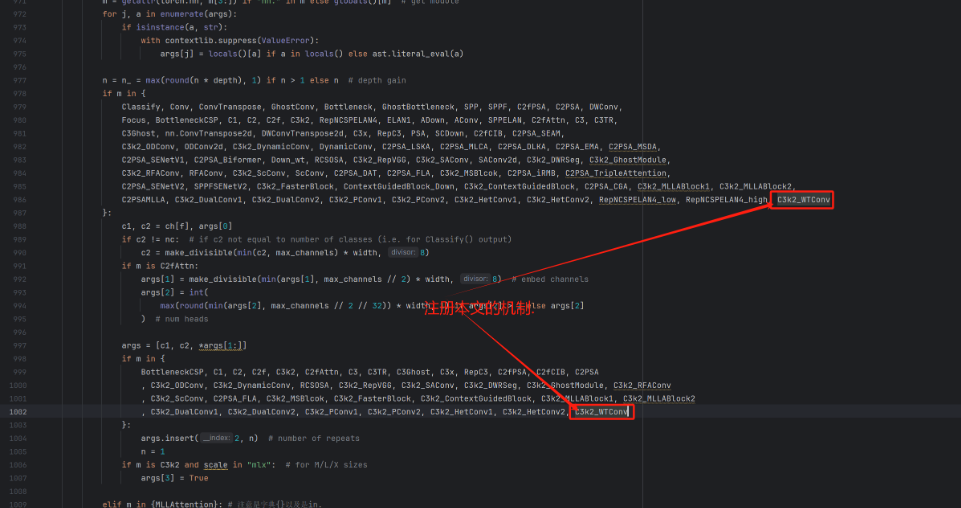
到此就修改完成了,大家可以复制下面的yaml文件运行。
五、正式训练
5.1 yaml文件1
训练信息:YOLO11-C3k2-WTConv summary: 344 layers, 2,480,347 parameters, 2,470,091 gradients, 6.3 GFLOPs
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2_WTConv, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2_WTConv, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2_WTConv, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2_WTConv, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2_WTConv, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2_WTConv, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2_WTConv, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2_WTConv, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)5.2 训练代码
大家可以创建一个py文件将我给的代码复制粘贴进去,配置好自己的文件路径即可运行。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('模型配置文件')# 如何切换模型版本, 上面的ymal文件可以改为 yolov8s.yaml就是使用的v8s,# 类似某个改进的yaml文件名称为yolov8-XXX.yaml那么如果想使用其它版本就把上面的名称改为yolov8l-XXX.yaml即可(改的是上面YOLO中间的名字不是配置文件的)!# model.load('yolov8n.pt') # 是否加载预训练权重,科研不建议大家加载否则很难提升精度model.train(data=r"C:\Users\Administrator\PycharmProjects\yolov5-master\yolov5-master\Construction Site Safety.v30-raw-images_latestversion.yolov8\data.yaml",# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, posecache=False,imgsz=640,epochs=150,single_cls=False, # 是否是单类别检测batch=16,close_mosaic=0,workers=0,device='0',optimizer='SGD', # using SGD# resume='runs/train/exp21/weights/last.pt', # 如过想续训就设置last.pt的地址amp=True, # 如果出现训练损失为Nan可以关闭ampproject='runs/train',name='exp',)5.3 训练过程截图
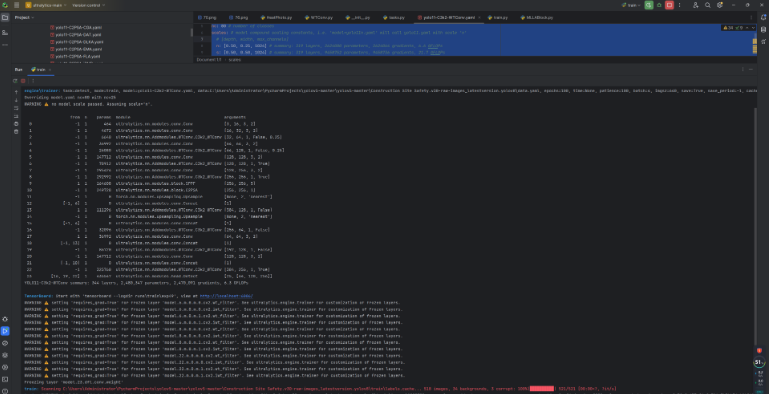
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv11改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~