学校网站的目的seo 资料包怎么获得
本文是对4DLUT技术的代码解读,原文解读请看4DLUT文章讲解。
1、原文概要
4D LUT针对 3DLUT 在局部处理效果上的局限性,提出优化方案。其核心亮点在于:通过引入图像上下文编码器提取上下文信息,并将该信息作为额外通道与原图组成 4 通道输入,从而使 4DLUT 能够基于上下文感知实现图像增强。
4DLUT的整体流程如下所示,可以分为4步:
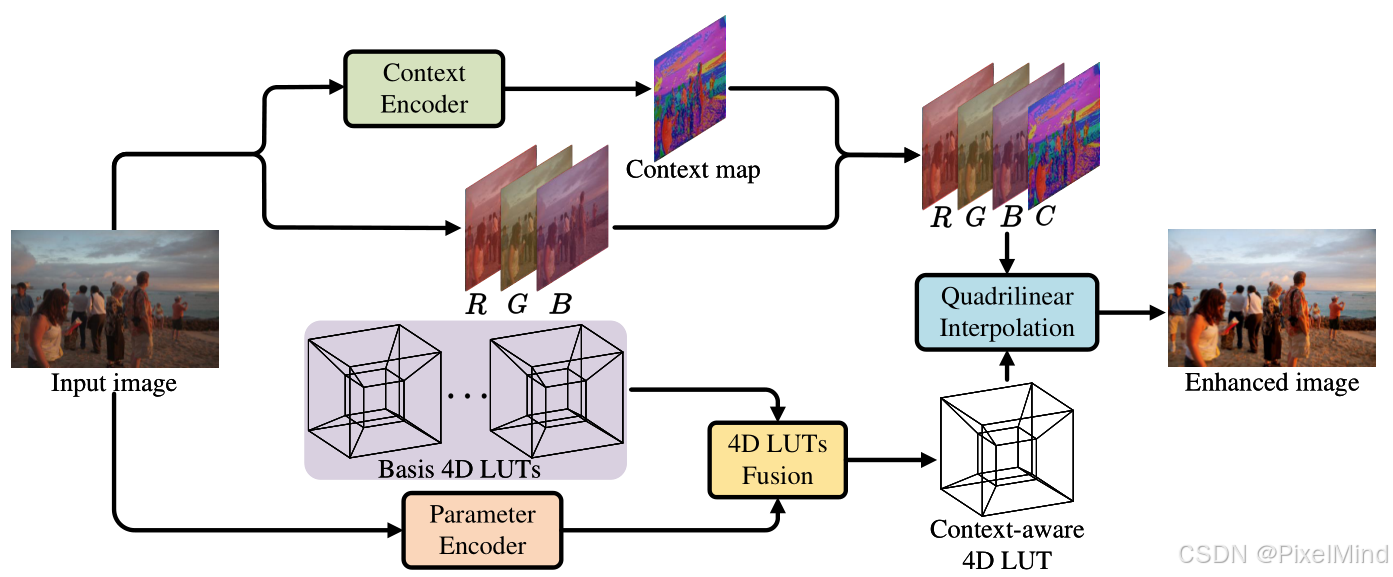
- 首先使用上下文编码器(Context Encoder)通过端到端学习从输入图像生成表示像素级类别的上下文映射。
- 同时,利用参数编码器(Parameter Encoder)生成图像自适应系数,用于融合可学习的预定义基础4DLUTs(Basis 4D LUTs)。
- 然后基于参数编码器的输出,使用4D LUTs融合模块(4D LUTS Fusion)将可学习的基础4DLUTs整合成最终具有更多增强功能的上下文感知4D LUT。
- 最后,利用组合context map的RGBC通道图像使用4DLUT进行插值得到增强的图像。
2、代码结构
代码整体结构如下:
quadrilinear_cpp是四次插值的cpp代码实现,datasets.py中放了数据集的处理,models_x.py放了模型和损失函数的实现,train.py放了整体训练的流程。
3 、核心代码模块
models_x.py 文件
这个文件包含了4DLUT中context encoder、param encoder、四次插值的实现和两个正则损失(平滑损失和单调损失)的计算。
1. Generator_for_info类
此为context encoder的实现。
class Generator_for_info(nn.Module):def __init__(self, in_channels=3):super(Generator_for_info, self).__init__()self.input_layer = nn.Sequential(nn.Conv2d(in_channels, 16, 3, stride=1, padding=1),nn.LeakyReLU(0.2),nn.InstanceNorm2d(16, affine=True),)self.mid_layer = nn.Sequential(*generator_block(16, 16, normalization=True),*generator_block(16, 16, normalization=True),*generator_block(16, 16, normalization=True),)self.output_layer = nn.Sequential(nn.Dropout(p=0.5),nn.Conv2d(16, 1, 3, stride=1, padding=1),nn.Sigmoid())def forward(self, img_input):x = self.input_layer(img_input)identity = xout = self.mid_layer(x)out += identityout = self.output_layer(out)return out
可以看到,输入经过一系列卷积和归一化模块,最终经过一个输出通道为1的卷积和一个sigmoid激活函数得到context map。
其中的discriminator_block实现如下:
def discriminator_block(in_filters, out_filters, normalization=False):"""Returns downsampling layers of each discriminator block"""layers = [nn.Conv2d(in_filters, out_filters, 3, stride=2, padding=1)]layers.append(nn.LeakyReLU(0.2))if normalization:layers.append(nn.InstanceNorm2d(out_filters, affine=True))#layers.append(nn.BatchNorm2d(out_filters))return layers
其实就是一个简单的卷积,搭配了一个激活函数,根据normalization选项的不同插入InstanceNorm。
2. Generator_for_bias
该类实现了4DLUT中的param encoder类:
class Generator_for_bias(nn.Module):def __init__(self, in_channels=3):super(Generator_for_bias, self).__init__()self.model = nn.Sequential(nn.Upsample(size=(256,256),mode='bilinear'),nn.Conv2d(3, 16, 3, stride=2, padding=1),nn.LeakyReLU(0.2),nn.InstanceNorm2d(16, affine=True),*discriminator_block(16, 32, normalization=True),*discriminator_block(32, 64, normalization=True),*discriminator_block(64, 128, normalization=True),*discriminator_block(128, 128),nn.Dropout(p=0.5),nn.Conv2d(128, 12, 8, padding=0),)def forward(self, img_input):return self.model(img_input)首先通过一个resize模块将输入降采样至256分辨率,随后经过一系列卷积块处理,最终通过一个kernel_size为8的12通道输出卷积层,生成12个用于后续LUT融合的参数。
3. Generator4DLUT_identity
该类实现4DLUT的初始化。
class Generator4DLUT_identity(nn.Module):def __init__(self, dim=17):super(Generator4DLUT_identity, self).__init__()if dim == 17:file = open("Identity4DLUT17.txt", 'r')elif dim == 33:file = open("Identity4DLUT33.txt", 'r')lines = file.readlines()buffer = np.zeros((3,2,dim,dim,dim), dtype=np.float32)for p in range(0,2):for i in range(0,dim):for j in range(0,dim):for k in range(0,dim):n = p * dim*dim*dim + i * dim*dim + j*dim + kx = lines[n].split()buffer[0,p,i,j,k] = float(x[0])buffer[1,p,i,j,k] = float(x[1])buffer[2,p,i,j,k] = float(x[2])self.LUT_en = nn.Parameter(torch.from_numpy(buffer).requires_grad_(True))self.QuadrilinearInterpolation_4D = QuadrilinearInterpolation_4D()def forward(self, x):_, output = self.QuadrilinearInterpolation_4D(self.LUT_en, x)return output这里的dim参数决定了LUT采样时的bins数量,dim值越大采样精度越高。博主存在一个疑问:context的维度参数p应当与dim保持一致,而非默认的2,否则context map只能获取两个离散值,后果是严重限制上下文信息的表达能力。实际操作中是将Identity4DLUT文本数据加载到buffer进行初始化,生成LUT_en用于后续的四维差值计算。
4. TV_4D
该类实现的是两个正则化的损失函数。
class TV_4D(nn.Module):def __init__(self, dim=17):super(TV_4D,self).__init__()self.weight_r = torch.ones(3,2,dim,dim,dim-1, dtype=torch.float)self.weight_r[:,:,:,:,(0,dim-2)] *= 2.0self.weight_g = torch.ones(3,2,dim,dim-1,dim, dtype=torch.float)self.weight_g[:,:,:,(0,dim-2),:] *= 2.0self.weight_b = torch.ones(3,2,dim-1,dim,dim, dtype=torch.float)self.weight_b[:,:,(0,dim-2),:,:] *= 2.0self.relu = torch.nn.ReLU()def forward(self, LUT):dif_context = LUT.LUT_en[:,:-1,:,:,:] - LUT.LUT_en[:,1:,:,:,:]dif_r = LUT.LUT_en[:,:,:,:,:-1] - LUT.LUT_en[:,:,:,:,1:]dif_g = LUT.LUT_en[:,:,:,:-1,:] - LUT.LUT_en[:,:,:,1:,:]dif_b = LUT.LUT_en[:,:,:-1,:,:] - LUT.LUT_en[:,:,1:,:,:]tv = torch.mean(torch.mul((dif_r ** 2),self.weight_r)) + torch.mean(torch.mul((dif_g ** 2),self.weight_g)) + torch.mean(torch.mul((dif_b ** 2),self.weight_b)) mn = torch.mean(self.relu(dif_r)) + torch.mean(self.relu(dif_g)) + torch.mean(self.relu(dif_b)) \+ torch.mean(self.relu(dif_context))return tv, mn这个没有特别需要讲解的,基本上是照着论文给出的公式将其翻译成代码,tv代表平滑性损失,mn代表单调性损失,因此这个类会同时输出两个损失,至于平滑损失中的w正则会在后续的训练中看到。
train.py 文件
存放着跟训练相关的代码。以一个epoch的一个batch的一次iteration为例:
for epoch in range(opt.epoch, opt.n_epochs):mse_avg = 0psnr_avg = 0Generator_bias.train()Generator_context.train()for i, batch in enumerate(dataloader):# Model inputsreal_A = Variable(batch["A_input"].type(Tensor))real_B = Variable(batch["A_exptC"].type(Tensor))# ------------------ # Train Generators# ------------------optimizer_G.zero_grad()fake_B, weights_norm = generator_train(real_A)# Pixel-wise lossmse = criterion_pixelwise(fake_B, real_B)tv_enhancement, mn_enhancement = TV4(LUT_enhancement)tv_cons = tv_enhancementmn_cons = mn_enhancement# loss = mseloss = mse + opt.lambda_smooth * (weights_norm + tv_cons) + opt.lambda_monotonicity * mn_conspsnr_avg += 10 * math.log10(1 / mse.item())mse_avg += mse.item()loss.backward()optimizer_G.step()
real_A 和real_B分别是增强前图像和增强后的HQ,generator_train是根据LUT生成图像的过程,实现如下所示:
def generator_train(img):context = Generator_context(img)pred = Generator_bias(img)context = context.new(context.size())context = Variable(context.fill_(0).type(Tensor))pred = pred.squeeze(2).squeeze(2)combine = torch.cat([context,img],1)gen_A0 = LUT_enhancement(combine)weights_norm = torch.mean(pred ** 2)combine_A = img.new(img.size())for b in range(img.size(0)):combine_A[b,0,:,:] = pred[b,0] * gen_A0[b,0,:,:] + pred[b,1] * gen_A0[b,1,:,:] + pred[b,2] * gen_A0[b,2,:,:] + pred[b,9]combine_A[b,1,:,:] = pred[b,3] * gen_A0[b,0,:,:] + pred[b,4] * gen_A0[b,1,:,:] + pred[b,5] * gen_A0[b,2,:,:] + pred[b,10]combine_A[b,2,:,:] = pred[b,6] * gen_A0[b,0,:,:] + pred[b,7] * gen_A0[b,1,:,:] + pred[b,8] * gen_A0[b,2,:,:] + pred[b,11]return combine_A, weights_norm
这里的Generator_context是前面刚讲到的context encoder网络结构,Generator_bias是前面讲到的param encoder的网络结构,
针对此处博主提出一个疑问,作者在代码中初始化了一个空的context将其与输入图像进行cat得到了一个4D图像,但如果输入为空的如何进行训练context encoder?
接下来会将combine对应的4D图像输入LUT_enhancement模块进行增强处理。需要注意的是,该模块仅使用一条4DLUT(通过4D插值生成输出gen_A0),而非论文中所述的三条4DLUT。
最终计算param的L2正则norm损失并执行LUT融合。此处将先前预测的12个参数用于输出融合,融合过程会利用LUT的每个维度。因此是需要 12=3 * 1 * 3 + 1 * 3,3个通道乘以1条LUT乘以3个通道代表的权重项加上1条LUT乘以3个通道代表的偏置项。若这么理解的话,则与论文中给出的公式不一致,论文中给出的权重的个数是 3 ∗ N l u t 2 3*N_{lut}^2 3∗Nlut2,我们这里看代码只能理解为 3 ∗ 3 ∗ N l u t 3*3*N_{lut} 3∗3∗Nlut。
之后是计算损失的过程:
# Pixel-wise lossmse = criterion_pixelwise(fake_B, real_B)tv_enhancement, mn_enhancement = TV4(LUT_enhancement)tv_cons = tv_enhancementmn_cons = mn_enhancement# loss = mseloss = mse + opt.lambda_smooth * (weights_norm + tv_cons) + opt.lambda_monotonicity * mn_cons
包含mse损失和正则、单调损失,正则损失使用的是我们前面讲到的TV_4D类,最后进行权重进行加权融合即可。
3、总结
代码实现核心的部分讲解完毕,但作者开源的4DLUT代码还是不完整和存在很多疑问点的,目前可以看到很多点与实际论文表述不一致,上面提到的疑问点总结有:
- 4DLUT的初始化中关于context的维度个数,代码中显示是2,而非跟颜色通道一样大,这样如何进行部署。
- 4DLUT训练中关于context的初始化,如果在计算完context后不使用,而是使用一个0初始化的context,如何将context信息加入到4DLUT中。
- 基础4DLUT的个数,不是3条而是单独的1条。
- 4DLUT中param encoder预测param的个数,跟论文中给出的公式不一致,论文中给出的weight权重的个数是 3 ∗ N l u t 2 3*N_{lut}^2 3∗Nlut2,但实际是 3 ∗ 3 ∗ N l u t 3*3*N_{lut} 3∗3∗Nlut。
4DLUT虽然利用context解决了图像中局部区域增强的问题,但是有一个问题是利用4DLUT来推理,加入了更多的计算量和更多的限制,这可能会减少其适用的场景,实用性相比较3DLUT有所降低。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。