网站上的产品五星怎样做优化seo分析与优化实训心得
背景展示:有页码的操作题

背景需求:
实操课终于全部结束了,把考试内容(docx)都写好了
【办公类-21-10】三级育婴师 视频转文字docx(等线小五单倍行距),批量改成“宋体小四、1.5倍行距、蓝色字体、去掉五分钟”-CSDN博客文章浏览阅读787次,点赞9次,收藏7次。【办公类-21-10】三级育婴师 视频转文字docx(等线小五单倍行距),批量改成“宋体小四、1.5倍行距、蓝色字体、去掉五分钟”https://blog.csdn.net/reasonsummer/article/details/137055848

最后所有docx需要合并在一起,便于打印,但是前期发现合并的PDF内没有页码,双面打印后没有页码不知道到底是第几题。
【办公类-21-08】三级育婴师 多个二级文件夹的docx合并成PDF-CSDN博客文章浏览阅读510次,点赞7次,收藏6次。【办公类-21-08】三级育婴师 多个二级文件夹的docx合并成PDFhttps://blog.csdn.net/reasonsummer/article/details/136460044?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22136460044%22%2C%22source%22%3A%22reasonsummer%22%7D

需求:
1、将所有docx文件合并一个docx,
2、插入页码,并确保一个题目一页,
3、保存docx,转成PDF。
通过三天的AI问询,终于将这个需求实现了。
第1步:从二级文件里提取所有的蓝色字体docx,放到整理

代码
import os,time
import shutilprint('-----1、复制每个文件夹下的(没有5分钟字样的docx文件到二级文件夹“整理”里-------')# 一级文件夹路径
folder_path = r'D:\04三级操作题'
# 目标文件夹路径
new_path = folder_path+r'\整理'
os.makedirs(new_path, exist_ok=True)# 获取一级文件夹中的所有二级文件夹(包括整理文件夹)
subfolders = [f.path for f in os.scandir(folder_path) if f.is_dir()]# 遍历二级文件夹并复制docx文件到目标文件夹复制到整理里面
for subfolder in subfolders:if subfolders=='整理': # 排除“整理”文件夹passelse:docx_files = [f for f in os.listdir(subfolder) if f.endswith('.docx')]for file in docx_files:source_file = os.path.join(subfolder, file)destination_file = os.path.join(new_path, file)if source_file == destination_file:# 如果复制文件相同,就跳过 continueif '5分钟' in file:# # 不要有5分钟文件名的docxpasselse:shutil.copy2(source_file, destination_file)

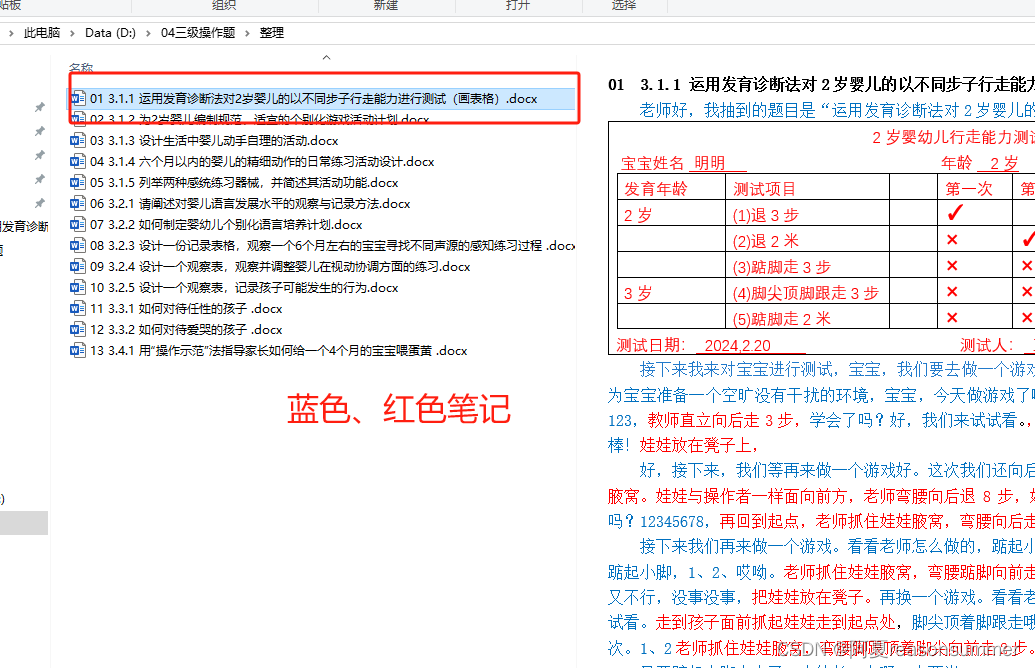
第2步:修改整理内docx的上下左右边距,页脚的边距



并且每段最后加一个下一页换页符(确保每个题目占满一面)

代码
print('-----2、把“整理”里面的所有docx打开,最后添加分节符、设置页眉页脚距离边距的大小(把页面撑到最大)------')
# 打开每个文件,添加一个分节符
from docx import Document
from docx.enum.section import WD_SECTION_START
from docx.shared import Cm# 遍历整理文件夹内的所有docx文件
for filename in os.listdir(new_path):if filename.endswith(".docx"):file_path = os.path.join(new_path, filename)# 打开docx文件doc = Document(file_path)# 设置页脚距离页面边界1厘米section = doc.sections[0]section.left_margin = Cm(1)section.right_margin = Cm(1)section.top_margin = Cm(1)section.bottom_margin = Cm(1)# 将页脚距离页面边界从1.75厘米改为1厘米section.footer_distance = Cm(1)# 添加一个新分节符doc.add_section(WD_SECTION_START.NEW_PAGE) # 保存文档(覆盖原文件)doc.save(file_path)边距修改后,可以写文字的部分变大了


第3步:读取一个有页码的模板,把“整理”内所有的docx文字复制到模板,并另存


print('-----3、读取一个带页码的模板,把整理里面的docx合并到这个模板里------')from docx import Document
from docx.enum.section import WD_SECTION_START
import os
from docx.shared import Cm# # 创建一个带页码的空Document对象,并把页眉页脚边距改小combined_doc = Document(folder_path+r'\页码.docx')# 读取“整理”里面的docx的内容
docx_files = []for file_name in os.listdir(new_path):if file_name.endswith(".docx"):docx_files.append(os.path.join(new_path, file_name))for file in docx_files:doc = Document(file)for element in doc.element.body:combined_doc.element.body.append(element) out_file=folder_path+r'\教育参考题1-13.docx'
combined_doc.save(out_file)
已经实现了每题1-2面(分页符)

但是还有第1行和最后1行(模板自带的,这些空行回车需要删除)

第4步,删除docx的第一个和最后一个回车
print('-----4、把“合并docx"的第一段回车和最后一个回车删除。(页码模板自带)---')
doc = Document(out_file)
# 删除第1个和最后一个段落(都只有一个回车)
for i in [0,-1]:dell_paragraph = doc.paragraphs[i]doc._element.body.remove(dell_paragraph._element)
doc.save(out_file)

第5步,docx转PDF
print('-----5、把“合并docx"转为”合并PDF“---')
# from docx2pdf import convert
# # 转换123.docx为123.pdf
# convert(out_file, out_file[:4]+'.pdf')
# 用这个导致有些内容到下一页了。import comtypes.client,time# 启动Word应用程序
word = comtypes.client.CreateObject('Word.Application')
doc = word.Documents.Open(out_file)# pdf_file=out_file[:-4]+'pdf'# 将文档保存为PDF文件
doc.SaveAs(out_file[:-4]+'pdf', FileFormat=17) # 17表示PDF格式
# r'D:\04三级操作题\教育参考题1-13.pdf'
time.sleep(2)
# 关闭Word应用程序
doc.Close()
word.Quit()print("转换完成!")



现在docx合并和PDF合并都有页码了
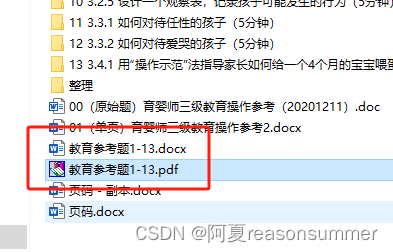
1、docx:便于日后的修改(内容补充)
2、PDF:便于双面打印(内容板式不变化)
全部代码展示:
'''
合并word,带页码(读取一个带页码的空模板),转出PDF
作者:阿夏(AI对话大师)
时间:2024年3月27日
'''import os,time
import shutilprint('-----1、复制每个文件夹下的(没有5分钟字样的docx文件到二级文件夹“整理”里-------')# 一级文件夹路径
folder_path = r'D:\04三级操作题'
# 目标文件夹路径
new_path = folder_path+r'\整理'
os.makedirs(new_path, exist_ok=True)# 获取一级文件夹中的所有二级文件夹(包括整理文件夹)
subfolders = [f.path for f in os.scandir(folder_path) if f.is_dir()]# 遍历二级文件夹并复制docx文件到目标文件夹复制到整理里面
for subfolder in subfolders:if subfolders=='整理': # 排除“整理”文件夹passelse:docx_files = [f for f in os.listdir(subfolder) if f.endswith('.docx')]for file in docx_files:source_file = os.path.join(subfolder, file)destination_file = os.path.join(new_path, file)if source_file == destination_file:# 如果复制文件相同,就跳过 continueif '5分钟' in file:# # 不要有5分钟文件名的docxpasselse:shutil.copy2(source_file, destination_file)print('-----2、把“整理”里面的所有docx打开,最后添加分节符、设置页眉页脚距离边距的大小(把页面撑到最大)------')
# 打开每个文件,添加一个分节符
from docx import Document
from docx.enum.section import WD_SECTION_START
from docx.shared import Cm# 遍历整理文件夹内的所有docx文件
for filename in os.listdir(new_path):if filename.endswith(".docx"):file_path = os.path.join(new_path, filename)# 打开docx文件doc = Document(file_path)# 设置页脚距离页面边界1厘米section = doc.sections[0]section.left_margin = Cm(1)section.right_margin = Cm(1)section.top_margin = Cm(1)section.bottom_margin = Cm(1)# 将页脚距离页面边界从1.75厘米改为1厘米section.footer_distance = Cm(1)# 添加一个新分节符doc.add_section(WD_SECTION_START.NEW_PAGE) # 保存文档(覆盖原文件)doc.save(file_path)print('-----3、读取一个带页码的模板,把整理里面的docx合并到这个模板里------')from docx import Document
from docx.enum.section import WD_SECTION_START
import os
from docx.shared import Cm# # 创建一个带页码的空Document对象,并把页眉页脚边距改小combined_doc = Document(folder_path+r'\页码.docx')# 读取“整理”里面的docx的内容
docx_files = []for file_name in os.listdir(new_path):if file_name.endswith(".docx"):docx_files.append(os.path.join(new_path, file_name))for file in docx_files:doc = Document(file)for element in doc.element.body:combined_doc.element.body.append(element) out_file=folder_path+r'\教育参考题1-13.docx'
combined_doc.save(out_file)print('-----4、把“合并docx"的第一段回车和最后一个回车删除。(页码模板自带)---')
doc = Document(out_file)
# 删除第1个和最后一个段落(都只有一个回车)
for i in [0,-1]:dell_paragraph = doc.paragraphs[i]doc._element.body.remove(dell_paragraph._element)
doc.save(out_file)print('-----5、把“合并docx"转为”合并PDF“---')
# from docx2pdf import convert
# # 转换123.docx为123.pdf
# convert(out_file, out_file[:4]+'.pdf')
# 用这个导致有些内容到下一页了。import comtypes.client,time# 启动Word应用程序
word = comtypes.client.CreateObject('Word.Application')
doc = word.Documents.Open(out_file)# pdf_file=out_file[:-4]+'pdf'# 将文档保存为PDF文件
doc.SaveAs(out_file[:-4]+'pdf', FileFormat=17) # 17表示PDF格式
# r'D:\04三级操作题\教育参考题1-13.pdf'
time.sleep(2)
# 关闭Word应用程序
doc.Close()
word.Quit()print("转换完成!")