用flash做网站超链接怎么创建网站快捷方式到桌面
数据一致性模型
根据一致性的强弱分类,可以将一致性模型按以下顺序排列:
强一致性 > 最终一致性 > 弱一致性
数据一致性模型一般用于分布式系统中,目的是定义多个节点间的同步规范。
在这里,我们将其引入数据库和缓存组成的存储系统中,在这个系统中,数据库和缓存就是两个节点。
我们将尝试采用不同的方案,实现这两个节点的同步状态。
此外,由于 MySQL 和 Redis 的广泛流行,我们这里可以把数据库 = MySQL,缓存 = Redis。
强一致性模型
强一致性模型要求在分布式系统中,所有节点对于某个数据项的值都是一致的。
即:所有读操作总能返回最新的写操作结果。
强一致性模型可以通过使用共享内存、锁、原子操作等同步机制来实现。
最终一致性模型
允许在分布式系统中,不同节点可能对于某个数据项的值是不一致的,但是在某个时间点,所有节点对于某个数据项的值都会达到一致。
即:读操作不一定能返回最新的写操作结果。数据更新后,不保证立即一致,但保证在一定时间内最终一致。
最终一致性模型通常使用消息队列和事件源等异步机制来解决数据一致性问题。
弱一致性模型
弱一致性模型允许在分布式系统中,不同节点可能对于某个数据项的值是不一致的。
弱一致性模型通常使用版本号(version number)和最近COMMIT时间戳等机制来解决数据一致性问题。
区别
- 强一致性与弱一致性的区别
强一致性要求在分布式系统中,所有节点对于某个数据项的值是一致的。弱一致性允许在分布式系统中,不同节点可能对于某个数据项的值是不一致的。强一致性可以通过使用共享内存、锁等同步机制来实现,而弱一致性可以通过使用版本号、时间戳等机制来解决数据一致性问题。
- 最终一致性和弱一致性的区别
弱一致性允许在分布式系统中,不同节点可能对于某个数据项的值是不一致的。最终一致性允许在分布式系统中,不同节点可能对于某个数据项的值是不一致的,但是在某个时间点,所有节点对于某个数据项的值都会达到一致。最终一致性可以通过使用消息队列、事件源等异步机制来解决数据一致性问题。
强一致性模型适用于需要高度一致性的场景,如银行转账、电子商务订单等。
弱一致性模型适用于需要高度可用性和扩展性的场景,如缓存、数据备份等。
最终一致性模型适用于需要实时性和弹性的场景,如实时数据分析、日志处理等。在选择数据一致性模型时,需要权衡应用场景的一致性、可用性、扩展性和实时性需
数据库和缓存的数据一致性
- 过程一致性- 第一种不一致:缓存和数据其中一者为空- 第二种不一致:缓存和数据皆存在,但值不同。-
先抛一下结论:在满足实时性的条件下,不存在同时保证过程一致性和最终一致性的方案
最好的结果是第一种过程不一致 + 最终一致性方案。
在满足实时性的前提下,不存在强一致性的方案,只有最终一致性方案。
事实上,除了秒杀、余额交易等准确性要求高的业务外,其它业务并不追求强一致性。
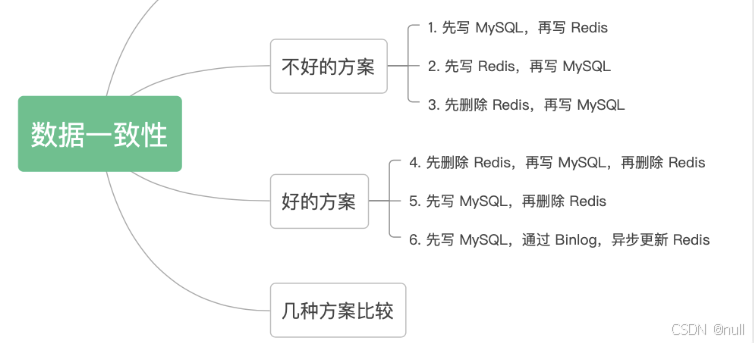
不好的方案:每个请求都先写数据库,再写缓存
例如 :A请求在先,更新数据为10;B请求在后,更新数据为11。最终数据库和缓存中的变量应该都为 11。
至少应有四步,理想的顺序为
- 线程 A 执行 updateMySQL(10)。
- 线程 A 执行 updateRedis(10)。
- 线程 B 执行 updateMySQL(11)。
- 线程 B 执行 updateRedis(11)。
然而,As we all know:进程并发执行,其执行顺序并非固定。
理想的情况是 1234,但1324也是可能的。
最坏的情况,1342,即下图:
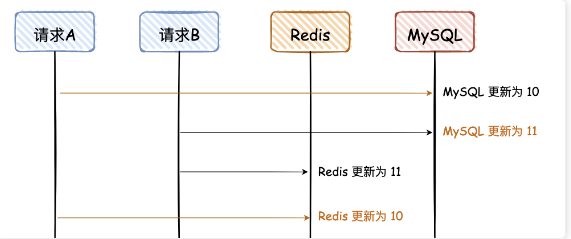
这种顺序下执行完四步,最终数据库为 11;缓存为 10。
不好的方案:每个请求都先写 Redis,再写 MS
与第一种方案出错的原因一致。
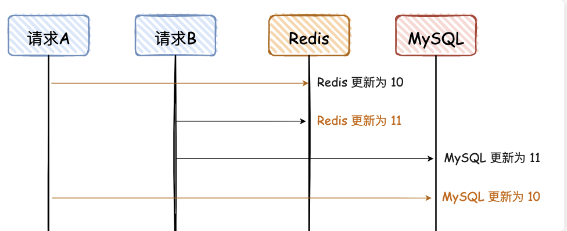
不好的方案:每个请求都先删除 Redis,再写 MS,最后写 Redis
这种方法可以达到最终 一致性,但可能由于过程不一致,被并发线程脏读。
请求 A 是更新请求,目标是将变量更新为 11
请求 B 是读请求
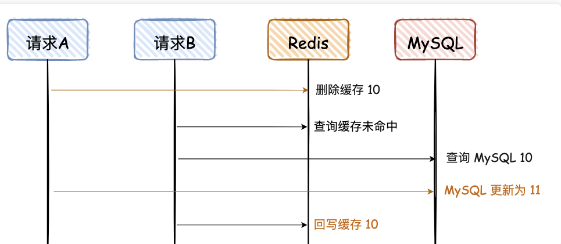
最初状态下:MS 和 Redis 都为 10。
- A请求第一步:删除缓存。此时 MS 为 10,缓存为空。
- B 查询变量的值,但是由于未命中缓存,查询 MS 得到 10。查询结果错误
- A请求第二步:更新 MS 11。此时 MS 为 11,缓存为空
- B 知道缓存中不存在,但 MS 中有,自然会写回 Redis,此时 MS 为 11,Redis 为 10。此时数据已经不一致了,任意线程此时查询,会查到错误的 10
- A请求第三步:更新 Redis 11。此时 MS 为 11,Redis 为 11。
【2】和【4】都是可能的脏读发生时机,【2】发生的可能更大,因为查询远快于更新。
好的方案:【缓存双删】每个请求都先删除 Redis,再写 MySQL,再删除 Redis
这个方案是对 “先删除 Redis,再写 MySQL” 的升级,因为在后者,存在最终一致性问题。
既然最终 MS 和 Redis 不一致,那干脆把 Redis 重新删除即可,这个也是大家常说的“缓存双删”。
A请求为更新请求,目标是将变量更新为 11
B请求为读请求,查询变量的值
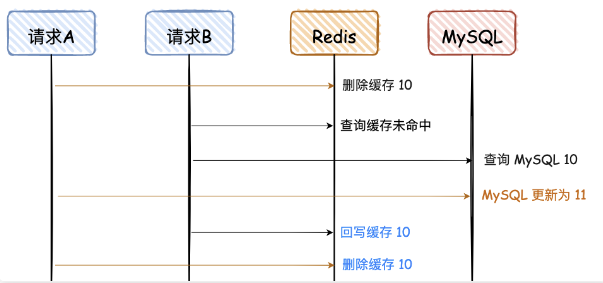
最初状态下:MS 和 Redis 都为 10。
- A请求第一步:删除 Redis 中的变量10。此时 MS 为 10, Redis 为空
- B 查询变量的值,但是由于未命中缓存,查询 MS 得到 10
- A请求第二步:写 MS 为 11。此时 MS 为 11,Redis 空
- B 知道缓存中不存在,但 MS 中有,自然会写回 Redis,此时 MS 为 11,Redis 为 10。
- A请求第三步:删除 Redis 中的变量 10。此时 MS 为 11,Redis 为 空。
【2】和【4】都是可能的脏读发生时机,【2】发生的可能更大,因为查询远快于更新。
尝试改进【延时双删】每个请求都先删除 Redis,再写 MySQL,再延时删除 Redis
回看上一个方案的蓝字部分-- 即时序图的第四步、第五步。
需要注意,第四步和第五步必须依次执行。
倘若先第五步: A请求第三步:删除 Redis 中的变量 10。此时 MS 为 11,Redis 为 空。
再第四步:B 知道缓存中不存在,但 MS 中有,自然会写回 Redis,此时 MS 为 11,Redis 为 10。
连最终一致性也不能保证了!这就是一个很坏的方案。
为了确保第四步第五步依次执行,不妨在执行第五步前,主动休眠 A请求一段时间,以确保最后执行。
这就是延时的地方。
但也并非完美,因为延时的时机如果掌控不好仍然会被脏读。
继续改进 使用消息队列
既然休眠总体第五步:定时延时删除缓存,不一定好用。
将这一步加入加入消息队列中,执行异步串行化删除。
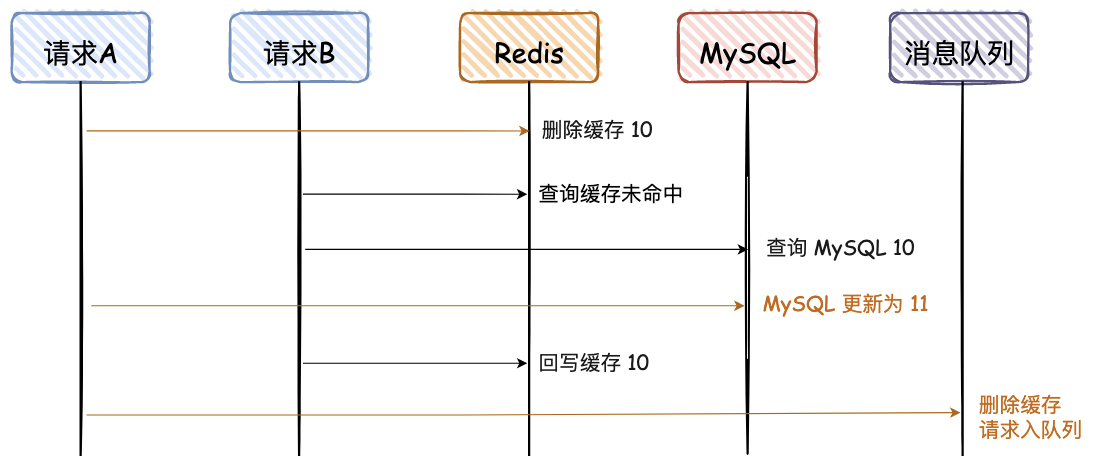
好的方案:每个请求都先写 MS,再删除 Redis
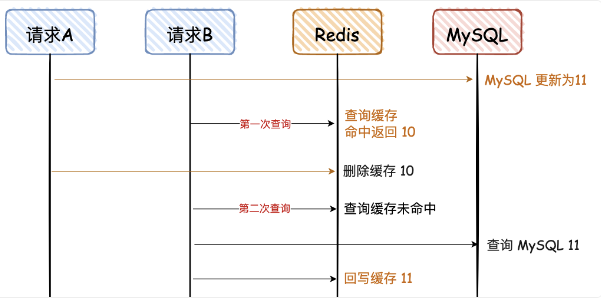
【2】是可能的脏读发生时机
此外,在满足以下两个条件时,这种方案还可能出现另一种意外:
- 请求B开始查询时,缓存刚好自动失效;
- 请求 B 从数据库查出 10,回写缓存的耗时,比请求 A 写数据库,并且删除缓存的还长。
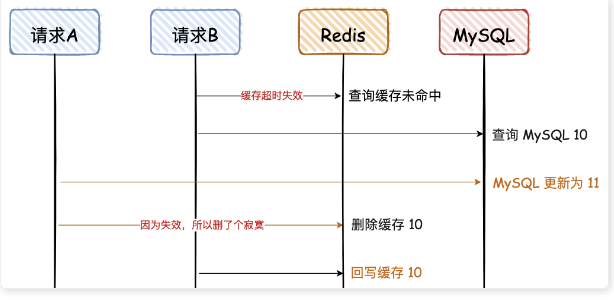
此时完全乱套了,数据库中的是错误的数据。
但注意,这种情况发生的条件之一是:请求 B 从数据库查出 10 的耗时 + 请求B 回写缓存的耗时 > 请求 A 写数据库 + 请求A 删除缓存的耗时
不等式左右两边各有一次数据库 + 一次缓存,但我们显然可知,左边查数据库的耗时,是远小于右边写数据库的耗时的
因此这一条件很难满足,极端情况发生的概率很小。
先写 MySQL,通过 Binlog,异步更新 Redis
这种方案,主要是监听 MySQL 的 Binlog,然后通过异步的方式,将数据更新到 Redis,这种方案有个前提,查询的请求,不会回写 Redis。
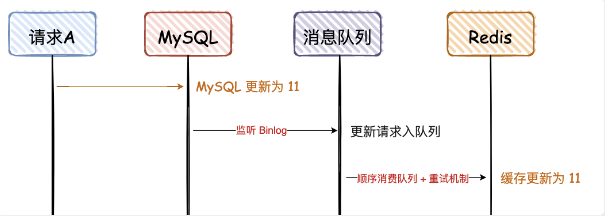
这个方案,会保证 MySQL 和 Redis 的最终一致性,但是如果中途请求 B 需要查询数据,如果缓存无数据,就直接查 DB;如果缓存有数据,查询的数据也会存在不一致的情况。
所以这个方案,是实现最终一致性的终极解决方案,但是不能保证实时性。
定论
- 先写 Redis,再写 MySQL
这种方案,我肯定不会用,万一 DB 挂了,你把数据写到缓存,DB 无数据,这个是灾难性的;
我之前也见同学这么用过,如果写 DB 失败,对 Redis 进行逆操作,那如果逆操作失败呢,是不是还要搞个重试?
- 先写 MySQL,再写 Redis
对于并发量、一致性要求不高的项目,很多就是这么用的,我之前也经常这么搞,但是不建议这么做;
当 Redis 瞬间不可用的情况,需要报警出来,然后线下处理。
- 先删除 Redis,再写 MySQL
这种方式,我还真没用过,直接忽略吧。
- 先删除 Redis,再写 MySQL,再删除 Redis
这种方式虽然可行,但是感觉好复杂,还要搞个消息队列去异步删除 Redis。
- 先写 MySQL,再删除 Redis
比较推荐这种方式,删除 Redis 如果失败,可以再多重试几次,否则报警出来;
这个方案,是实时性中最好的方案,在一些高并发场景中,推荐这种。
- 先写 MySQL,通过 Binlog,异步更新 Redis
对于异地容灾、数据汇总等,建议会用这种方式,比如 binlog + kafka,数据的一致性也可以达到秒级;
纯粹的高并发场景,不建议用这种方案,比如抢购、秒杀等。
个人结论:
实时一致性方案:采用“先写 MySQL,再删除 Redis”的策略,这种情况虽然也会存在两者不一致,但是需要满足的条件有点苛刻,所以是满足实时性条件下,能尽量满足一致性的最优解。
最终一致性方案:采用“先写 MySQL,通过 Binlog,异步更新 Redis”,可以通过 Binlog,结合消息队列异步更新 Redis,是最终一致性的最优解。