毕业设计做网站答辩国外网站设计
目录
一、数据及分析对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据准备
七、模型训练
八、模型评价
九、模型调参
十、模型改进
十一、模型预测
一、数据及分析对象
CSV文件——“bc_data.csv”
数据集链接:https://download.csdn.net/download/m0_70452407/88524905
该数据集主要记录了569个病例的32个属性,主要属性/字段如下:
(1)ID:病例的ID。
(2)Diagnosis(诊断结果):M为恶性,B为良性。该数据集共包含357个良性病例和212个恶性病例。
(3)细胞核的10个特征值,包括radius(半径)、texture(纹理)、perimeter(周长)、面积(area)、平滑度(smoothness)、紧凑度(compactness)、凹面(concavity)、凹点(concave points)、对称性(symmetry)和分形维数(fractal dimension)等。同时,为上述10个特征值分别提供了3种统计量,分别为均值(mean)、标准差(standard error)和最大值(worst or largest)。
二、目的及分析任务
理解机器学习方法在数据分析中的应用——KNN方法进行分类分析。
(1)样本为训练集进行有监督学习,并预测——“诊断结果(diagnosis)”。
(2)以剩余记录为测试集,进行KNN建模。
(3)按KNN模型预测测试集的dignosis类型。
(4)按KNN模型给出的diagnosis“预测类型”与数据集bc_data.csv自带的“实际类型”进行对比分析,验证KNN建模的有效性。
三、方法及工具
Python语言及scikit-learn包
四、数据读入
import pandas as pd
bc_data=pd.read_csv("D:\\Download\\JDK\\数据分析理论与实践by朝乐门_机械工业出版社\\第4章 分类分析\\bc_data.csv",header=0)
bc_data.head()
五、数据理解
对数据框bc_data进行探索性分析,这里采用的实现方法为调用pandas包中数据框(DataFrame)的describe()方法。
bc_data.describe()
除了describe()方法,还可以调用shape属性和pandas_profiling包对数据框进行探索性分析。
bc_data.shape(569, 32)
六、数据准备
在数据框bc_data中,对于乳腺癌诊断分析有用的数据为细胞核的10个特征值,为了将该数据值提取出来,需要在数据框bc_data的基础上删除列名为“id”和“diagnosis”的数据,删除后的数据框命名为“data”,实现方式为调用数据框的drop()方法,并使用该包的head()方法观察数据情况。
data=bc_data.drop(['id'],axis=1)
X_data=data.drop(['diagnosis'],axis=1)
X_data.head()
接着,调用NumPy的ravel()方法对数据框data中命名为“diagnosis”的列信息以视图形式(view)返回,并以一维数组形式输出。
import numpy as np
y_data=np.ravel(data[['diagnosis']])
y_data[0:6]array(['M', 'M', 'M', 'M', 'M', 'M'], dtype=object)
为了实现基于KNN算法乳腺癌自动诊断的目标,先将data数据框信息随机分为训练集和测试集两部分。采用的实现方式为调用scikit-learn包中model_selection模块的train_test_split()方法,设定训练集数据容量占总数居的75%,剩下的为测试集数据,调用pandas包中数据框(DataFrame)的describe()方法。
from sklearn.model_selection import train_test_split
X_trainingSet,X_testSet,y_trainingSet,y_testSet=train_test_split(X_data,y_data,random_state=1,test_size=0.25)
X_trainingSet.describe()
除了describe()方法,还可以调用shape属性和pandas_profiling包对数据框进行探索性分析。
X_trainingSet.shape(426, 30)
同时,对测试集数据框也对其做相同的处理。
X_testSet.describe()
X_testSet.shape(143, 30)
对训练集数据进行“学习训练”后,自动获取它的均值和方差,再分别对训练集和测试集进行“归一化”处理。采用的实现方式为调用scikit-learn包中的preprocessing模块的StandardScaler()方法。其中,训练集数据的归一化处理如下:
from sklearn.preprocessing import StandardScaler
means_normalization=StandardScaler() #均值归一化处理
means_normalization.fit(X_trainingSet) #进行训练集的“诊断学习”,得到均值和方差
X_train_normalization=means_normalization.transform(X_trainingSet)X_train_normalizationarray([[ 0.30575375, 2.59521918, 0.46246107, ..., 1.81549702,2.10164609, 3.38609913],[ 0.23351721, -0.05334893, 0.20573083, ..., 0.5143837 ,0.14721854, 0.05182385],[ 0.15572401, 0.18345881, 0.11343692, ..., 0.69446859,0.263409 , -0.10011179],...,[ 0.85586279, 1.19276558, 0.89773369, ..., 1.12967374,0.75591781, 2.97065009],[-0.02486734, 0.44095848, -0.08606303, ..., -0.52515632,-1.1291423 , -0.45561747],[-0.30270019, -0.20968802, -0.37543871, ..., -0.967865 ,-1.54361274, -1.31500348]])
对测试集数据也采用相同的方式进行归一化处理。
X_test_normalization=means_normalization.transform(X_testSet)
X_test_normalizationarray([[ 0.15850234, -1.23049032, 0.25369143, ..., -0.05738582,-0.08689656, 0.48863884],[-0.2638036 , -0.15450952, -0.23961754, ..., 1.41330744,1.77388495, 2.02105229],[-0.32492682, -0.76147305, -0.35407811, ..., -0.1354226 ,0.87210827, 0.71179432],...,[ 0.25852216, -0.06024625, 0.21500053, ..., -0.03937733,-1.03202789, -0.84910706],[ 1.46709506, 0.95825694, 1.49824869, ..., 0.62693676,0.07438274, -0.45739797],[-0.61942964, 0.42256565, -0.6261235 , ..., -0.48013509,0.34318156, -0.6134881 ]])
七、模型训练
训练集进行学习概念“诊断结果”,利用测试集进行KNN建模。通过对训练和测试数据进行适当的处理后,接下来进行模型参数的确定。KNN模型类别有暴力法、KD树和球树。暴力法适用于数据较少的形式,而KD树在较多的数据中更有优势,考虑到算法效率问题,结合本项目中数据框的数据量,选择KD树进行建模,首先取得KNN分类器,并使用内置参数调整KNN三要素。
这里采用的模型训练实现方式为scikit-learn包中的neighbors模块的KNeighborsClassifier()方法,其中对于设置的各项参数解释如下:
(1)algorithm表示快速k近邻搜索算法,这里确定的算法模型为KD树。
(2)leaf_size是构造KD树的大小,默认为30。
(3)metric用于距离度量,默认度量是minkowski。
(4)metric_params表示距离公式的其他关键参数,并不是很重要,使用默认的None。
(5)n_jobs是并行处理设置,使用默认的None。
(6)n_neighbors表示初始设定的近邻树,即KNN算法中的k值。
(7)p代表距离度量公式,其中1为哈曼顿距离公式,2为欧氏距离公式,这里使用欧氏距离公式进行距离度量,将p值设置为2。
(8)weights表权重,默认为uniform(均等权重)。
接着,利用训练函数fit()和预测函数predict()实现对训练集已知数据和测试集数据的对比输出。
from sklearn.neighbors import KNeighborsClassifier
myModel=KNeighborsClassifier(algorithm="kd_tree",leaf_size=30,metric="minkowski",metric_params=None,n_jobs=None,n_neighbors=5,p=2,weights="uniform")
myModel.fit(X_trainingSet,y_trainingSet)
y_predictSet=myModel.predict(X_testSet)fit()函数数据训练结果如下:
y_testSetarray(['B', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'M', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'M', 'B', 'B', 'M', 'B', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'M', 'M','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'B', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B'],dtype=object)
用predict()函数进行预测的结果如下:
y_predictSetarray(['M', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'M', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'M', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'M', 'B', 'B', 'M', 'M', 'B'],dtype=object)
最后,使用get_params()方法实现对模型各参数的查询:
myModel.get_params(){'algorithm': 'kd_tree','leaf_size': 30,'metric': 'minkowski','metric_params': None,'n_jobs': None,'n_neighbors': 5,'p': 2,'weights': 'uniform'}
由上述输出结果可以看出,使用get_params()方法查询参数是以字典结构的形式展现,并且可以看到参数结果与之前设置保持一致。
八、模型评价
为了评价所建立模型的性能,采用“预测准确率(Accuracy Score)”参数,具体实现方式是调用scikit-learn包的metrics模块的accuracy_score()方法。
from sklearn.metrics import accuracy_score
accuracy_score(y_testSet,y_predictSet)0.9370629370629371
通过结果输出可知,模型预测结果的准确率约为93.71%,可以考虑尝试进一步优化。
九、模型调参
通过前面分析可知,k值的大小对模型预测结果会产生很多的影响。为此,接下来利用准确率函数score()来实现k值范围在1~22的准确率值计算。
import matplotlib.pyplot as plt
NumberOfNeighbors=range(1,23)
KNNs=[KNeighborsClassifier(n_neighbors=i) for i in NumberOfNeighbors]
range(len(KNNs))
scores=[KNNs[i].fit(X_trainingSet,y_trainingSet).score(X_testSet,y_testSet) for i in range(0,22)]
plt.plot(NumberOfNeighbors,scores)
plt.title("Elbow Curve")
plt.xlabel("Number of Neighbors")
plt.ylabel("Score")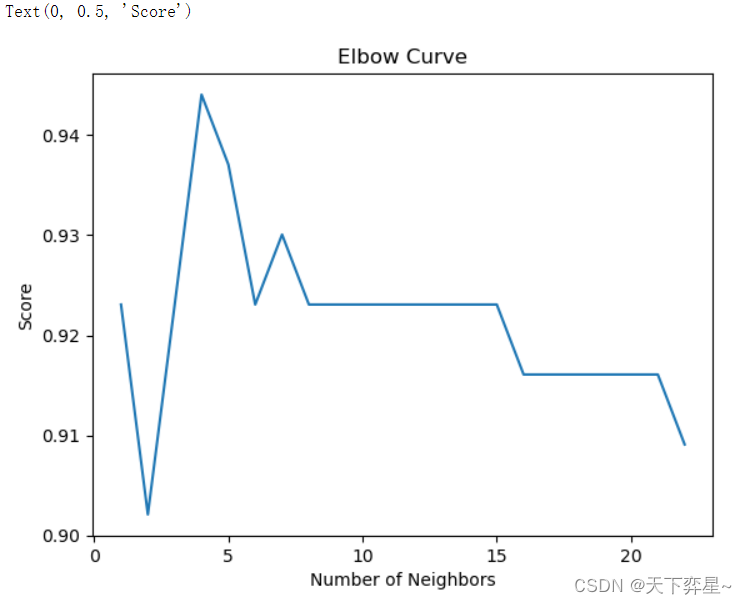
通过图标信息可以看到,当k的值(即n_neighbors)为4时,模型预测得分最高,因此接下来对模型参数进行改进。
十、模型改进
myModel_prove=KNeighborsClassifier(algorithm="kd_tree",leaf_size=30,metric="minkowski",metric_params=None,n_jobs=None,n_neighbors=4,p=2,weights="uniform")
myModel_prove.fit(X_trainingSet,y_trainingSet)
y_predictSet=myModel_prove.predict(X_testSet)十一、模型预测
fit()函数数据训练结果如下:
y_predictSetarray(['B', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'B', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'M', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B'],dtype=object)
用predict()函数进行预测的结果如下:
y_predictSetarray(['B', 'M', 'B', 'M', 'M', 'M', 'M', 'M', 'B', 'B', 'B', 'B', 'M','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B','B', 'M', 'M', 'M', 'M', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'B','B', 'B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'M', 'M','B', 'B', 'B', 'B', 'B', 'M', 'B', 'B', 'B', 'M', 'B', 'M', 'B','B', 'B', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B', 'M', 'B', 'B','B', 'M', 'B', 'M', 'B', 'M', 'B', 'B', 'M', 'B', 'M', 'B', 'B','M', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'B', 'B', 'M', 'M', 'B','B', 'B', 'B', 'B', 'M', 'M', 'B', 'B', 'M', 'M', 'M', 'M', 'M','B', 'B', 'B', 'M', 'B', 'M', 'M', 'B', 'B', 'B', 'M', 'M', 'B'],dtype=object)
为了评价所建立模型的性能,采用“预测准确率(Accuracy Score)”参数,具体实现方式是调用scikit-learn包的metrics模块的accuracy_score()方法。
accuracy_score(y_testSet,y_predictSet)0.9440559440559441
从输出结果可以看出,模型的预测准确率提高了,说明对模型进行了优化。