模板网站会影响网站优化吗安徽做网站公司哪家好
吾杯网络安全技能大赛WP(部分)
MISC
Sign
直接16进制解码即可

原神启动
- 将图片用StegSolve打开

找到了压缩包密码
将解出docx文件改为zip
找到了一张图片和zip


再把图片放到stegSlove里找到了img压缩包的密码

然后在document.xml里找到了text.zip压缩包密码

然后就出来flag了

太极

先把编码格式转换为utf-8

根据提示4,找到了拼音规律,

每一段的第一个字取第一个字母,第二个取第二个字母,如果拼音不足的话再从头数

旋转木马
给了两段base编码,先把他们合并到一起
因为两个文件太大了所以只能用脚本了
import osdef concatenate_files(file1_path, file2_path, output_path):try:# 检查文件是否存在if not os.path.exists(file1_path) or not os.path.exists(file2_path):print("一个或多个文件不存在。")return# 打开并读取第一个文件with open(file1_path, 'r', encoding='utf-8') as file1:content1 = file1.read()# 打开并读取第二个文件with open(file2_path, 'r', encoding='utf-8') as file2:content2 = file2.read()# 将两个文件内容拼接combined_content = content1 + content2# 将拼接后的内容写入新文件with open(output_path, 'w', encoding='utf-8') as output_file:output_file.write(combined_content)print(f"文件内容已成功拼接并保存到 '{output_path}'.")except FileNotFoundError as e:print(f"文件未找到: {e}")except IOError as e:print(f"文件操作错误: {e}")except Exception as e:print(f"发生未知错误: {e}")file1_path = 'flag1'
file2_path = 'flag2'
output_path = 'out.txt'concatenate_files(file1_path, file2_path, output_path)然后将合并后的base编码循环解码
import base64def decode(f):n = 0while True:try:f = base64.b64decode(f)n += 1except base64.binascii.Error as e:print(f"[+] Base64共解码了{n}次,最终解码结果如下:")print(f.decode('utf-8', errors='replace')) # 处理无效的UTF-8序列breakexcept Exception as e:print(f"[!] 发生未知错误: {e}")breakif __name__ == '__main__':# 使用 with 语句确保文件正确关闭with open('./out.txt', 'r', encoding='utf-8') as file:content = file.read().strip() # 去除首尾空白字符# 尝试Base64解码decode(content)
解出一个16进制,再解码

音文
给了一个wav文件,先用Audacity看一下

看不太懂,
slienteye也试了,没东西
用kali foremost 一下找到了一个zip文件

这里就想到把文件里的所有文件名提取出来
import os
import redef extract_number(file_name):# 使用正则表达式查找文件名中的第一个数字序列match = re.search(r'(\d+)', file_name)if match:return int(match.group())else:return float('inf') # 如果没有找到数字,返回一个很大的值,以确保这些文件排在最后# 获取并过滤掉非文件项(如目录)
file_names = [f for f in os.listdir('.') if os.path.isfile(f)]# 根据文件名中的数字排序
file_names_sorted = sorted(file_names, key=extract_number)# 拼接文件名中的中文字符
result = ''.join(chinese_charsfor file_name in file_names_sortedfor chinese_chars in re.findall(r'[\u4e00-\u9fa5]', file_name)
)# 写入结果到 out.txt 文件
output_path = 'out.txt'
try:with open(output_path, 'w', encoding='utf-8') as f:f.write(result)print(f"结果已保存到 {output_path}")
except IOError as e:print(f"写入文件时出错: {e}")

然后发现类似与摩斯密码
将苏珊替换为.哎哟替换为-你干嘛替换为空格

然后发现了一个地址

下载下来是一个apk文件
拖进模拟器

发现是一个解密软件,需要输入文件路径
考虑把wav放进去

找到文件路径

/mnt/shared/Pictures/AT.wav


解密失败,文件hash不对
考虑把wav里的压缩包去掉
这里用手动去,foremost后的不行(我也不知道为啥)


然后再拖进模拟器中,再解密

Crypto
Easy
给了两个文件
flag.txt:
d8d2 963e 0d8a b853 3d2a 7fe2 96c5 2923
3924 6eba 0d29 2d57 5257 8359 322c 3a77
892d fa72 61b8 4f
附件.txt
get buf unsign s[256]get buf t[256]we have key:hello worldwe have flag:????????????????????????????????for i:0 to 256set s[i]:ifor i:0 to 256set t[i]:key[(i)mod(key.lenth)]for i:0 to 256set j:(j+s[i]+t[i])mod(256)swap:s[i],s[j]for m:0 to 37set i:(i + 1)mod(256)set j:(j + S[i])mod(256)swap:s[i],s[j]set x:(s[i] + (s[j]mod(256))mod(256))set flag[m]:flag[m]^s[x]fprint flagx to file
直接通义出
import binasciidef rc4(key, data):# Initialize S and T arrayss = list(range(256))j = 0for i in range(256):j = (j + s[i] + key[i % len(key)]) % 256s[i], s[j] = s[j], s[i]# Pseudo-random generation algorithm (PRGA)i = j = 0result = []for byte in data:i = (i + 1) % 256j = (j + s[i]) % 256s[i], s[j] = s[j], s[i]k = s[(s[i] + s[j]) % 256]result.append(byte ^ k)return bytes(result)# Provided key and flag as hex string
key = b'hello world'
hex_flag = "d8d2963e0d8ab8533d2a7fe296c5292339246eba0d292d5752578359322c3a77892dfa7261b84f"# Convert hex string to bytes
flag_bytes = binascii.unhexlify(hex_flag)# Decrypt the flag using RC4
decrypted_flag = rc4(key, flag_bytes)# Print the decrypted flag
print(decrypted_flag.decode('utf-8', errors='replace'))

web
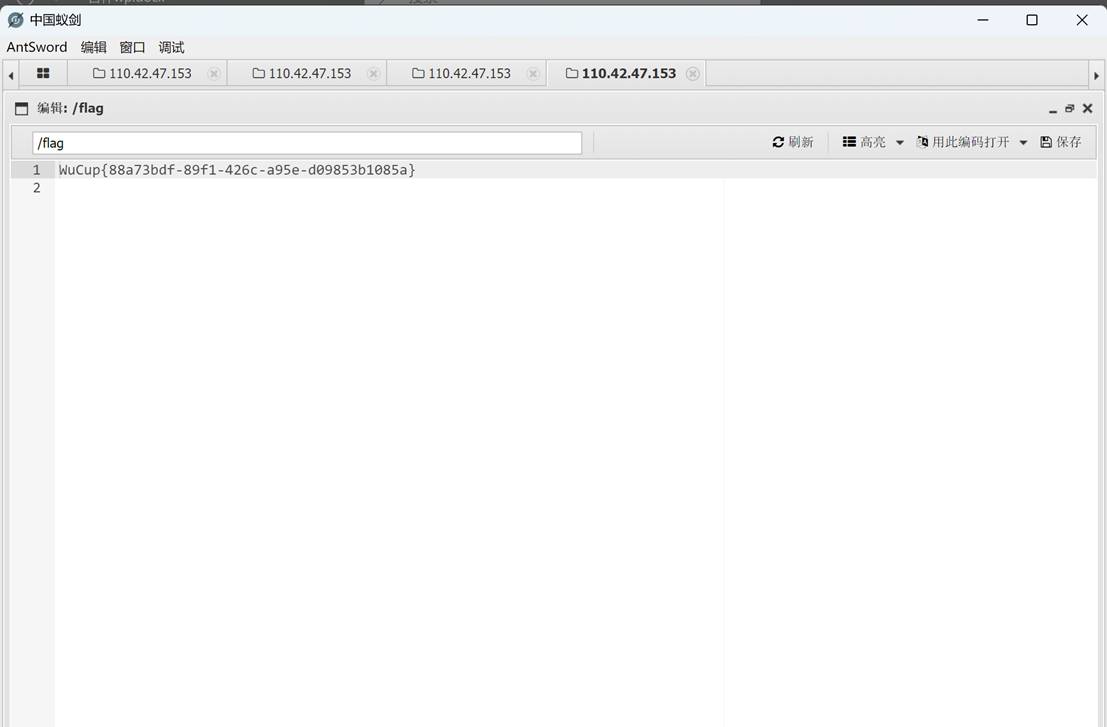
sign

访问页面发现给了密码了,根据提示直接用蚁剑连即可。


然后在根目录下找到了flag