嵌入式转行到网站开发游戏搜索风云榜
目录
一、前情提要
二、代码Demo
(一)多写问题
(二)如果要两个流写一个表,这种情况怎么处理?
(三)测试结果
三、后序
一、前情提要
基于数据湖对两条实时流进行拼接(如前端埋点+服务端埋点、日志流+订单流等);
基础概念见前一篇文章:基于数据湖的多流拼接方案-HUDI概念篇_Leonardo_KY的博客-CSDN博客
二、代码Demo
下文demo均使用datagen生成mock数据进行测试,如到生产,改成Kafka或者其他source即可。
第一个job:stream A,落hudi表:
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(minPauseBetweenCP); // 1senv.getCheckpointConfig().setCheckpointTimeout(checkpointTimeout); // 2 minenv.getCheckpointConfig().setMaxConcurrentCheckpoints(maxConcurrentCheckpoints);// env.getCheckpointConfig().setCheckpointStorage("file:///D:/Users/yakang.lu/tmp/checkpoints/");TableEnvironment tableEnv = StreamTableEnvironment.create(env);// datagen====================================================================tableEnv.executeSql("CREATE TABLE sourceA (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `name` VARCHAR(3)," +" _ts1 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");// hudi====================================================================tableEnv.executeSql("create table hudi_tableA(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " age int,\n"+ " name VARCHAR(3),\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3),\n"+ " d VARCHAR(10)\n"+ ")\n"+ " PARTITIONED BY (d)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = 'hdfs://ns/user/hive/warehouse/ctripdi_prodb.db/hudi_mor_mutil_source_test', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '10',\n"+ " 'write.tasks' = '10',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'write.partition.timestamp.type' = 'EPOCHMILLISECONDS',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1")+ " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job1',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"// + " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n" // todo// + " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n" //+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='false',\n"+ " 'compaction.async.enabled'='false',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='3',\n"+ " 'compaction.delta_seconds' ='60',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false',\n"+ " 'hive_sync.enable' = 'false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");// sql====================================================================StatementSet statementSet = tableEnv.createStatementSet();String sqlString = "insert into hudi_tableA(uuid, name, _ts1, d) select * from " +"(select *,date_format(CURRENT_TIMESTAMP,'yyyyMMdd') AS d from sourceA) view1";statementSet.addInsertSql(sqlString);statementSet.execute();第二个job:stream B,落hudi表:
StreamExecutionEnvironment env = manager.getEnv();env.getCheckpointConfig().setMinPauseBetweenCheckpoints(minPauseBetweenCP); // 1senv.getCheckpointConfig().setCheckpointTimeout(checkpointTimeout); // 2 minenv.getCheckpointConfig().setMaxConcurrentCheckpoints(maxConcurrentCheckpoints);// env.getCheckpointConfig().setCheckpointStorage("file:///D:/Users/yakang.lu/tmp/checkpoints/");TableEnvironment tableEnv = StreamTableEnvironment.create(env);// datagen====================================================================tableEnv.executeSql("CREATE TABLE sourceB (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `age` int," +" _ts2 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");// hudi====================================================================tableEnv.executeSql("create table hudi_tableB(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " age int,\n"+ " name VARCHAR(3),\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3),\n"+ " d VARCHAR(10)\n"+ ")\n"+ " PARTITIONED BY (d)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = 'hdfs://ns/user/hive/warehouse/ctripdi_prodb.db/hudi_mor_mutil_source_test', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '10',\n"+ " 'write.tasks' = '10',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1")+ " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job2',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"// + " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n" // todo// + " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n"+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='true',\n"+ " 'compaction.async.enabled'='true',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='2',\n"+ " 'compaction.delta_seconds' ='90',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");// sql====================================================================StatementSet statementSet = tableEnv.createStatementSet();String sqlString = "insert into hudi_tableB(uuid, age, _ts1, _ts2, d) select * from " +"(select *, _ts2 as ts1, date_format(CURRENT_TIMESTAMP,'yyyyMMdd') AS d from sourceB) view2";// statementSet.addInsertSql("insert into hudi_tableB(uuid, age, _ts2) select * from sourceB");statementSet.addInsertSql(sqlString);statementSet.execute();也可以将两个 writer 放到同一个app中(使用statement):
import java.time.ZoneOffset;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.StatementSet;
import org.apache.flink.table.api.TableConfig;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.config.TableConfigOptions;
import org.apache.hudi.common.model.PartialUpdateAvroPayload;
import org.apache.hudi.configuration.FlinkOptions;
// import org.apache.hudi.table.marker.SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy;public class Test00 {public static void main(String[] args) {Configuration configuration = TableConfig.getDefault().getConfiguration();configuration.setString(TableConfigOptions.LOCAL_TIME_ZONE, ZoneOffset.ofHours(8).toString());//设置东八区// configuration.setInteger("rest.port", 8086);StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(configuration);env.setParallelism(1);env.enableCheckpointing(12000L);// env.getCheckpointConfig().setCheckpointStorage("file:///Users/laifei/tmp/checkpoints/");TableEnvironment tableEnv = StreamTableEnvironment.create(env);// datagen====================================================================tableEnv.executeSql("CREATE TABLE sourceA (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `name` VARCHAR(3)," +" _ts1 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");tableEnv.executeSql("CREATE TABLE sourceB (\n" +" uuid bigint PRIMARY KEY NOT ENFORCED,\n" +" `age` int," +" _ts2 TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'datagen', \n" +" 'fields.uuid.kind'='sequence',\n" +" 'fields.uuid.start'='0', \n" +" 'fields.uuid.end'='1000000', \n" +" 'rows-per-second' = '1' \n" +")");// hudi====================================================================tableEnv.executeSql("create table hudi_tableA(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " name VARCHAR(3),\n"+ " age int,\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3)\n"+ ")\n"+ " PARTITIONED BY (_ts1)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = 'file:\\D:\\Ctrip\\dataWork\\tmp', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '2',\n"+ " 'write.tasks' = '2',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'write.partition.timestamp.type' = 'EPOCHMILLISECONDS',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"// + String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1:name|_ts2:age")// + " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job1',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"+ " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n"+ " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n" //+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='false',\n"+ " 'compaction.async.enabled'='false',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='3',\n"+ " 'compaction.delta_seconds' ='60',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false',\n"+ " 'hive_sync.enable' = 'false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");tableEnv.executeSql("create table hudi_tableB(\n"+ " uuid bigint PRIMARY KEY NOT ENFORCED,\n"+ " name VARCHAR(3),\n"+ " age int,\n"+ " _ts1 TIMESTAMP(3),\n"+ " _ts2 TIMESTAMP(3)\n"+ ")\n"+ " PARTITIONED BY (_ts2)\n"+ " with (\n"+ " 'connector' = 'hudi',\n"+ " 'path' = '/Users/laifei/tmp/hudi/local.db/mutiwrite1', \n" // hdfs path+ " 'table.type' = 'MERGE_ON_READ',\n"+ " 'write.bucket_assign.tasks' = '2',\n"+ " 'write.tasks' = '2',\n"+ " 'write.partition.format' = 'yyyyMMddHH',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"+ " 'changelog.enabled' = 'true',\n"+ " 'index.type' = 'BUCKET',\n"+ " 'hoodie.bucket.index.num.buckets' = '2',\n"// + String.format(" '%s' = '%s',\n", FlinkOptions.PRECOMBINE_FIELD.key(), "_ts1:name|_ts2:age")// + " 'write.payload.class' = '" + PartialUpdateAvroPayload.class.getName() + "',\n"+ " 'hoodie.write.log.suffix' = 'job2',\n"+ " 'hoodie.write.concurrency.mode' = 'optimistic_concurrency_control',\n"+ " 'hoodie.write.lock.provider' = 'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',\n"+ " 'hoodie.cleaner.policy.failed.writes' = 'LAZY',\n"+ " 'hoodie.cleaner.policy' = 'KEEP_LATEST_BY_HOURS',\n"+ " 'hoodie.consistency.check.enabled' = 'false',\n"+ " 'hoodie.write.lock.early.conflict.detection.enable' = 'true',\n"+ " 'hoodie.write.lock.early.conflict.detection.strategy' = '"// + SimpleTransactionDirectMarkerBasedEarlyConflictDetectionStrategy.class.getName() + "',\n"+ " 'hoodie.keep.min.commits' = '1440',\n"+ " 'hoodie.keep.max.commits' = '2880',\n"+ " 'compaction.schedule.enabled'='true',\n"+ " 'compaction.async.enabled'='true',\n"+ " 'compaction.trigger.strategy'='num_or_time',\n"+ " 'compaction.delta_commits' ='2',\n"+ " 'compaction.delta_seconds' ='90',\n"+ " 'compaction.max_memory' = '3096',\n"+ " 'clean.async.enabled' ='false'\n"// + " 'hive_sync.mode' = 'hms',\n"// + " 'hive_sync.db' = '%s',\n"// + " 'hive_sync.table' = '%s',\n"// + " 'hive_sync.metastore.uris' = '%s'\n"+ ")");// sql====================================================================StatementSet statementSet = tableEnv.createStatementSet();statementSet.addInsertSql("insert into hudi_tableA(uuid, name, _ts1) select * from sourceA");statementSet.addInsertSql("insert into hudi_tableB(uuid, age, _ts2) select * from sourceB");statementSet.execute();}
}(一)多写问题
由于HUDI官方提供的code打成jar包是不支持“多写”的,这里使用Tencent改造之后的code进行打包测试;
如果使用官方包,多个writer写入同一个hudi表,则会报如下异常:
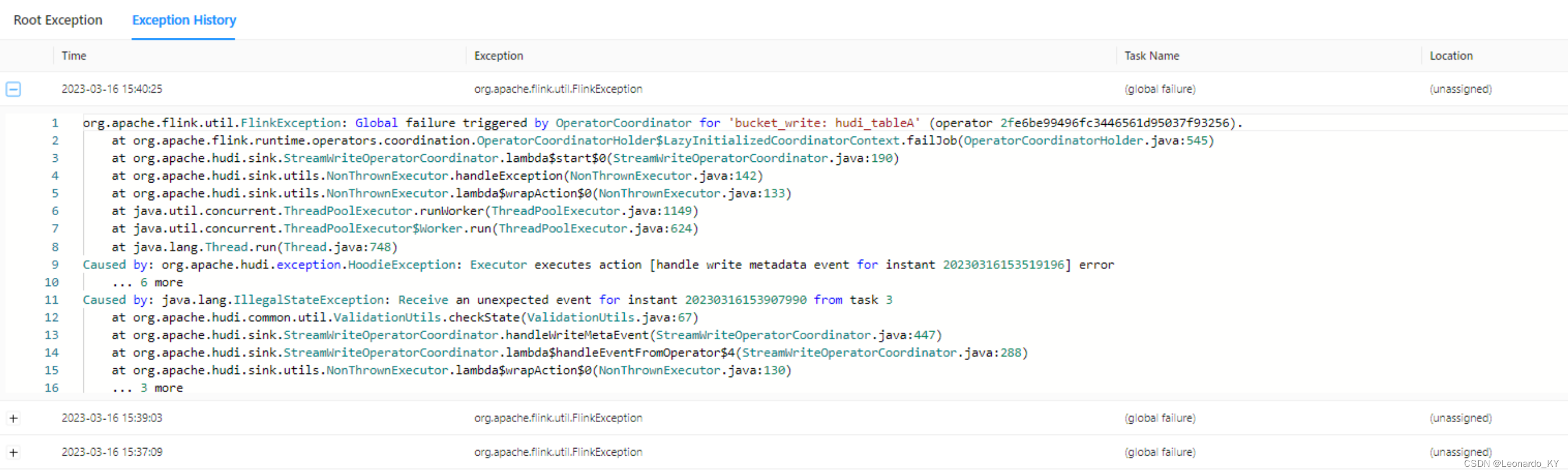
而且:
hudi中有个preCombineField,在建表的时候只能指定其中一个字段为preCombineField,但是如果使用官方版本,双流写同一个hudi的时候出现两种情况:
1. 一条流写preCombineField,另一条流不写这个字段,后者会出现 ordering value不能为null;
2. 两条流都写这个字段,出现字段冲突异常;
(二)如果要两个流写一个表,这种情况怎么处理?
经过本地测试:
hudi0.12-multiWrite版本(Tencent修改版),可以支持多 precombineField(在此版本中,只要保证主键、分区字段之外的字段,在多个流中不冲突即可实现多写!)
hudi0.13版本,不支持,而且存在上述问题;
(三)测试结果

Tencent文章链接:https://cloud.tencent.com/developer/article/2189914
github链接:GitHub - XuQianJin-Stars/hudi at multiwrite-master-7
hudi打包很麻烦,如果需要我将后续上传打好的jar包;
三、后序
基于上述code,当流量比较大的时候,似乎会存在一定程度的数据丢失(在其中一条流进行compact,则另一条流就会存在一定程度的数据丢失);
可以尝试:
(1)先将两个流UNION为一个流,再sink到hudi表(也避免了写冲突);
(2)使用其他数据湖工具,比如apache paimon,参考:新一代数据湖存储技术Apache Paimon入门Demo_Leonardo_KY的博客-CSDN博客