代办网站企业备案官网seo是什么
数据分片策略实战:水平分片vs垂直分片,千万级数据如何优雅扩展?
关键词:数据分片、水平分片、垂直分片、分库分表、数据库扩展、分片键设计、分布式数据库、海量数据处理、数据架构、分片策略
摘要:当单表数据量突破千万级别时,传统数据库开始力不从心。数据分片作为分布式架构的核心技术,能够有效解决数据量爆炸带来的性能瓶颈。本文将通过生动的类比和实际案例,深入解析水平分片与垂直分片的设计原理、实施策略和最佳实践,帮助你掌握从单体数据库到分布式架构的完美蜕变之路。
引言:当数据库遇到扩展危机
想象一下,你管理着一个快速增长的电商平台。刚开始时,一张订单表轻松应对每天几千笔交易。但随着业务爆发式增长,数据量从百万级跃升到千万级,甚至亿级:
- 查询响应时间从毫秒级变成秒级
- 单表INSERT操作频繁超时
- 数据库备份时间从小时变成半天
- 热点数据访问成为系统瓶颈
这时候,你需要的不是更强的硬件,而是更智能的数据分片策略。
什么是数据分片?为什么需要分片?
数据分片的本质
数据分片(Sharding)就像把一个巨大的图书馆分成多个专门的分馆:
分片的核心思想:
- 将大表分割成多个小表
- 分散存储到不同的数据库节点
- 并行处理提升整体性能
- 实现线性扩展能力
分片 vs 传统优化方案
让我们看看各种解决方案的对比:
| 解决方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 垂直扩展 | 简单直接 | 成本高昂,有上限 | 中小规模数据 |
| 读写分离 | 读性能提升 | 写瓶颈依然存在 | 读多写少场景 |
| 分区表 | 透明性好 | 单机限制明显 | 时序数据归档 |
| 数据分片 | 无限扩展 | 复杂度较高 | 海量数据处理 |
用一个生动的比喻来理解:如果把数据库比作餐厅,传统优化就像换更大的餐桌、雇更多服务员,而分片则是开更多分店——真正实现了规模化扩展。
水平分片:让数据"分而治之"
水平分片基本原理
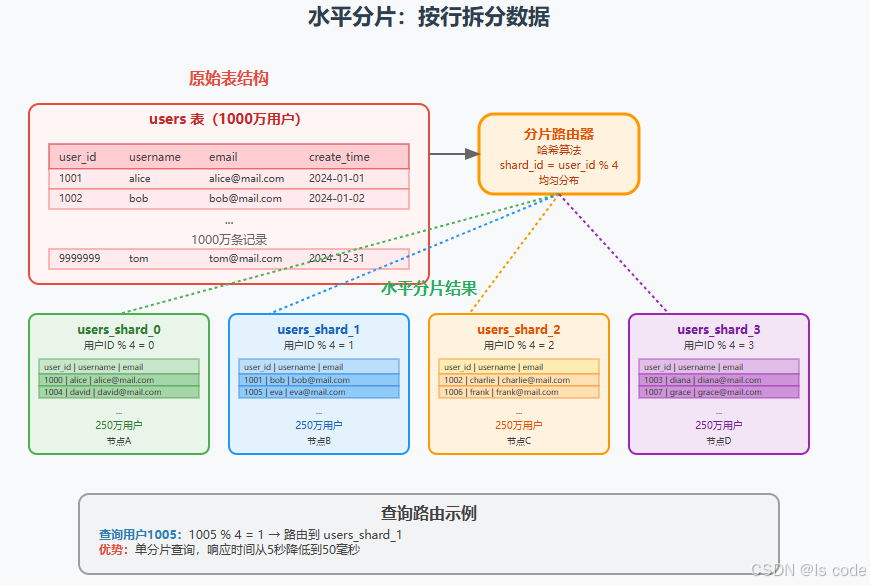
水平分片将表按行进行切分,每个分片包含相同的表结构,但存储不同的数据行。
水平分片的三种策略
1. 哈希分片(Hash Sharding)
最常用的分片方式,通过对分片键进行哈希运算来确定数据分布。
-- 简单取模分片
shard_id = hash(user_id) % shard_count-- 一致性哈希分片(支持动态扩容)
shard_id = consistent_hash(user_id)
优点:数据分布均匀,负载平衡
缺点:范围查询需要跨分片,扩容时需要数据迁移
2. 范围分片(Range Sharding)
按照分片键的值范围进行分片,常用于时序数据。
-- 按时间范围分片
IF order_date BETWEEN '2024-01-01' AND '2024-03-31' THEN shard_1
IF order_date BETWEEN '2024-04-01' AND '2024-06-30' THEN shard_2
IF order_date BETWEEN '2024-07-01' AND '2024-09-30' THEN shard_3
优点:范围查询高效,扩容简单
缺点:可能产生热点分片,数据分布不均
3. 目录分片(Directory Sharding)
维护一个查找表来记录数据分布规则。
-- 分片目录表
CREATE TABLE shard_directory (entity_id VARCHAR(50),shard_id INT,created_at TIMESTAMP
);-- 查询时先查目录
SELECT shard_id FROM shard_directory WHERE entity_id = 'user_12345';
优点:灵活性高,支持复杂分片逻辑
缺点:查询开销大,目录表成为瓶颈
水平分片实战案例
让我们以电商订单表为例,看看水平分片的具体实现:
-- 原始订单表
CREATE TABLE orders (order_id BIGINT PRIMARY KEY,user_id BIGINT NOT NULL,product_id BIGINT,amount DECIMAL(10,2),status VARCHAR(20),created_at TIMESTAMP,INDEX idx_user_id (user_id),INDEX idx_created_at (created_at)
);-- 按用户ID进行8分片
-- orders_0: user_id % 8 = 0
-- orders_1: user_id % 8 = 1
-- ...
-- orders_7: user_id % 8 = 7-- 分片后的查询示例
-- 查询用户订单(单分片查询)
SELECT * FROM orders_3 WHERE user_id = 12345; -- 12345 % 8 = 5 -> orders_5-- 按时间范围查询(需要跨分片聚合)
SELECT COUNT(*) FROM (SELECT COUNT(*) FROM orders_0 WHERE created_at >= '2024-01-01'UNION ALLSELECT COUNT(*) FROM orders_1 WHERE created_at >= '2024-01-01'-- ... 其他分片
) AS total_count;
垂直分片:按业务边界优雅拆分
垂直分片的两个维度
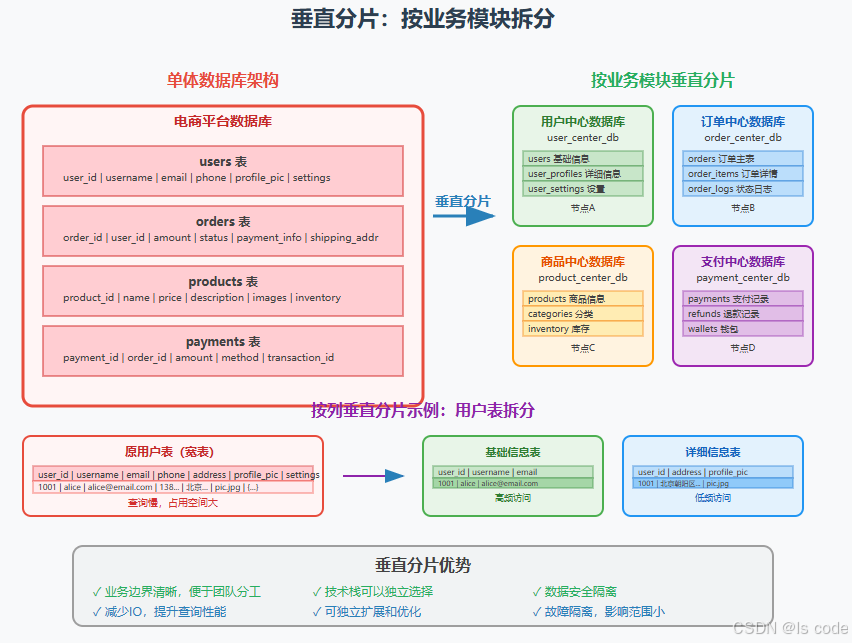
1. 按业务模块垂直分片
将不同业务领域的表分离到独立的数据库中:
-- 用户中心数据库
-- user_center_db
CREATE TABLE users (user_id BIGINT PRIMARY KEY,username VARCHAR(50),email VARCHAR(100),phone VARCHAR(20)
);CREATE TABLE user_profiles (user_id BIGINT PRIMARY KEY,avatar_url VARCHAR(200),bio TEXT,preferences JSON
);-- 订单中心数据库
-- order_center_db
CREATE TABLE orders (order_id BIGINT PRIMARY KEY,user_id BIGINT, -- 外键关联,但跨库total_amount DECIMAL(10,2),status VARCHAR(20)
);-- 商品中心数据库
-- product_center_db
CREATE TABLE products (product_id BIGINT PRIMARY KEY,name VARCHAR(100),price DECIMAL(10,2),category_id INT
);
2. 按列属性垂直分片
将大表按字段访问频率进行拆分:
-- 原始宽表
CREATE TABLE user_info (user_id BIGINT PRIMARY KEY,username VARCHAR(50), -- 高频访问email VARCHAR(100), -- 高频访问phone VARCHAR(20), -- 中频访问address TEXT, -- 低频访问profile_picture LONGBLOB, -- 低频访问preferences JSON, -- 低频访问last_login TIMESTAMP -- 高频访问
);-- 拆分后的表结构
-- 基础信息表(高频访问)
CREATE TABLE user_basic (user_id BIGINT PRIMARY KEY,username VARCHAR(50),email VARCHAR(100),last_login TIMESTAMP
);-- 详细信息表(低频访问)
CREATE TABLE user_detail (user_id BIGINT PRIMARY KEY,phone VARCHAR(20),address TEXT,profile_picture LONGBLOB,preferences JSON
);
垂直分片的优势
- 业务隔离:不同模块的故障不会相互影响
- 技术栈多样化:不同业务可选择最适合的数据库技术
- 团队分工:便于不同团队独立开发和维护
- 性能优化:减少无效IO,提升查询效率
分片策略全面对比
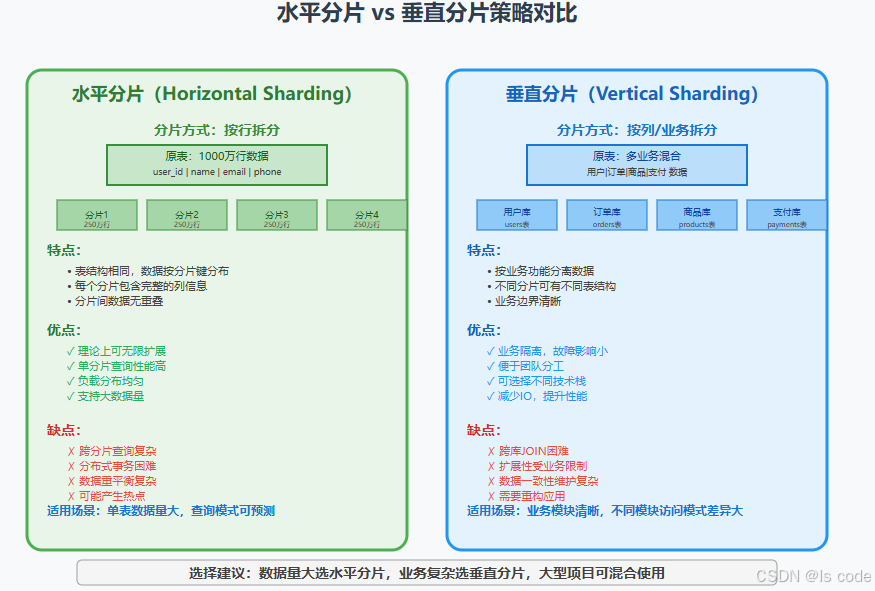
选择决策矩阵
| 场景特征 | 推荐策略 | 理由 |
|---|---|---|
| 单表数据量大(>1000万) | 水平分片 | 支持数据量线性扩展 |
| 业务模块边界清晰 | 垂直分片 | 便于系统解耦和团队协作 |
| 查询模式复杂多样 | 垂直分片 | 避免跨分片JOIN |
| 写入压力大 | 水平分片 | 分散写入负载 |
| 需要快速原型开发 | 垂直分片 | 实施复杂度相对较低 |
| 大型企业级系统 | 混合分片 | 结合两种策略的优势 |
分片键设计:成功的关键因素
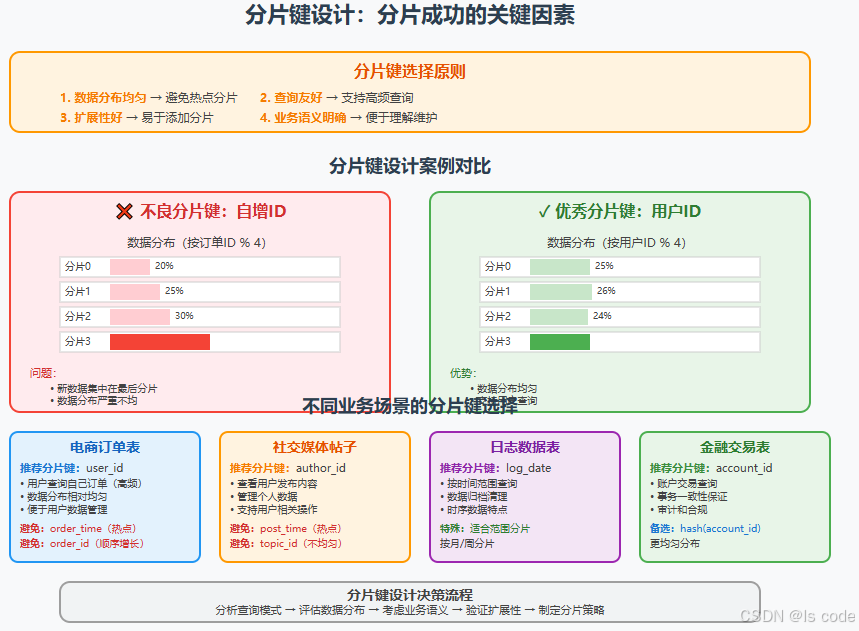
分片键设计的四大原则
1. 数据分布均匀性
避免数据倾斜和热点分片的产生。
# 检查数据分布均匀性的Python脚本
import hashlibdef check_distribution(user_ids, shard_count=8):shard_counts = [0] * shard_countfor user_id in user_ids:shard_id = int(hashlib.md5(str(user_id).encode()).hexdigest(), 16) % shard_countshard_counts[shard_id] += 1# 计算方差,衡量分布均匀性avg = sum(shard_counts) / shard_countvariance = sum((count - avg) ** 2 for count in shard_counts) / shard_countprint(f"各分片数据量: {shard_counts}")print(f"平均值: {avg}, 方差: {variance}")return variance < avg * 0.1 # 方差小于平均值的10%认为分布均匀# 测试示例
user_ids = range(1, 1000000) # 100万用户
is_balanced = check_distribution(user_ids)
print(f"数据分布{'均匀' if is_balanced else '不均匀'}")
2. 查询友好性
分片键应该支持最常见的查询模式。
-- 好的分片键设计:支持用户查询自己的订单
SELECT * FROM orders WHERE user_id = 12345; -- 单分片查询,性能好-- 坏的分片键设计:需要跨分片查询用户订单
SELECT * FROM orders WHERE user_id = 12345; -- 需要查询所有分片,性能差
3. 扩展性
分片键设计要考虑未来的扩容需求。
-- 一致性哈希算法支持动态扩容
-- 传统取模:shard_id = user_id % 8
-- 扩容到16分片时,大部分数据需要迁移-- 一致性哈希:只有1/n的数据需要迁移
-- 使用虚拟节点技术进一步优化
4. 业务语义明确
分片键应该有明确的业务含义,便于理解和维护。
常见分片键设计反模式
❌ 自增ID作为分片键
-- 问题:新数据都写入最后一个分片,产生写热点
shard_id = order_id % shard_count
❌ 时间戳作为分片键
-- 问题:当前时间的分片成为写热点
shard_id = hash(created_at) % shard_count
❌ 低基数字段作为分片键
-- 问题:状态字段取值有限,无法均匀分布
shard_id = hash(order_status) % shard_count -- status只有4个值
✅ 推荐的分片键设计
-- 用户相关表:使用user_id
shard_id = hash(user_id) % shard_count-- 订单表:使用user_id(支持用户查询订单)
shard_id = hash(user_id) % shard_count-- 商品表:按category_id + hash
shard_id = hash(category_id + product_id) % shard_count
电商平台分片架构实战
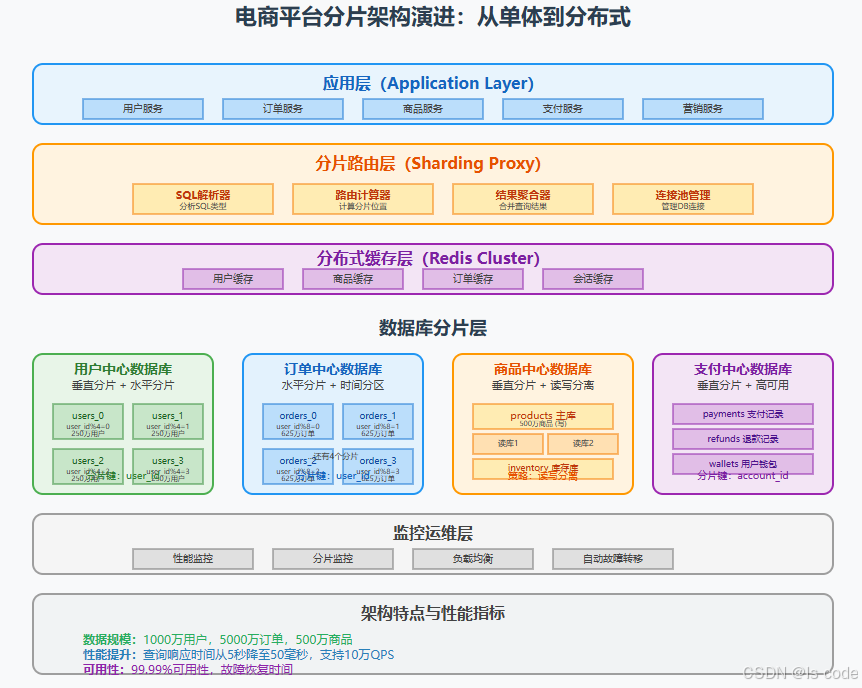
完整架构设计
让我们看一个真实的电商平台分片架构案例:
1. 应用层设计
@Service
public class OrderService {@Autowiredprivate ShardingDataSource dataSource;public Order createOrder(Long userId, OrderRequest request) {// 分片路由自动处理return orderRepository.save(new Order(userId, request));}public List<Order> getUserOrders(Long userId) {// 单分片查询,性能优秀return orderRepository.findByUserId(userId);}public OrderStatistics getDailyStatistics(Date date) {// 跨分片聚合查询return orderRepository.aggregateByDate(date);}
}
2. 分片路由配置
# Apache ShardingSphere配置示例
dataSources:ds_0:url: jdbc:mysql://db-shard-0:3306/ecommerceusername: rootpassword: passwordds_1:url: jdbc:mysql://db-shard-1:3306/ecommerceusername: rootpassword: password# ... 其他分片shardingRule:tables:orders:actualDataNodes: ds_${0..7}.orders_${0..7}tableStrategy:inline:shardingColumn: user_idalgorithmExpression: orders_${user_id % 8}databaseStrategy:inline:shardingColumn: user_idalgorithmExpression: ds_${user_id % 8}
3. 数据迁移脚本
import mysql.connector
import hashlib
from concurrent.futures import ThreadPoolExecutordef migrate_user_data(user_batch):"""迁移用户数据批次"""for user in user_batch:# 计算目标分片shard_id = int(hashlib.md5(str(user['user_id']).encode()).hexdigest(), 16) % 8# 连接目标分片target_conn = mysql.connector.connect(host=f'db-shard-{shard_id}',database='ecommerce',user='root',password='password')cursor = target_conn.cursor()# 插入用户数据cursor.execute("""INSERT INTO users (user_id, username, email, created_at)VALUES (%s, %s, %s, %s)""", (user['user_id'], user['username'], user['email'], user['created_at']))target_conn.commit()cursor.close()target_conn.close()def run_migration():"""执行数据迁移"""# 从原数据库读取数据source_conn = mysql.connector.connect(host='old-db-server',database='ecommerce',user='root',password='password')cursor = source_conn.cursor(dictionary=True)cursor.execute("SELECT * FROM users ORDER BY user_id")# 批量处理batch_size = 1000user_batch = []with ThreadPoolExecutor(max_workers=8) as executor:for user in cursor:user_batch.append(user)if len(user_batch) >= batch_size:executor.submit(migrate_user_data, user_batch.copy())user_batch.clear()# 处理最后一批if user_batch:executor.submit(migrate_user_data, user_batch)if __name__ == "__main__":run_migration()
性能提升效果
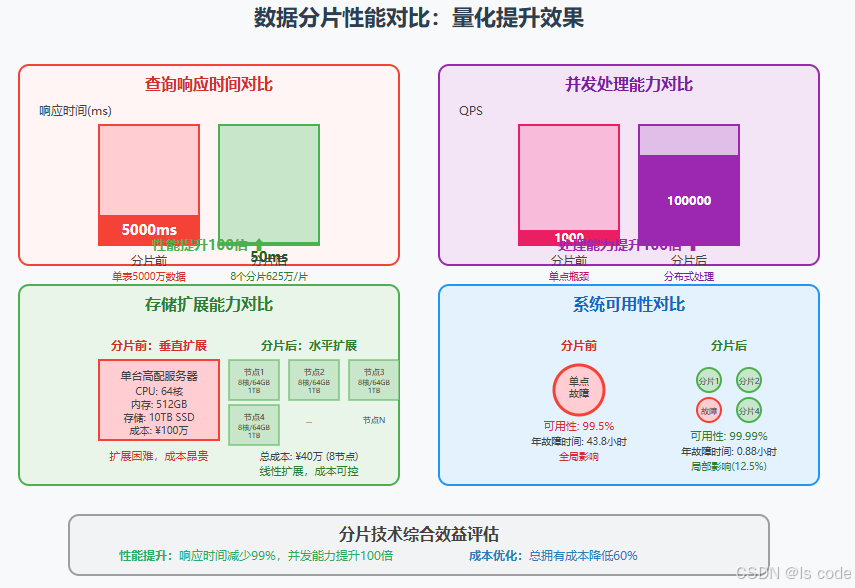
实施分片后的效果对比:
| 指标 | 分片前 | 分片后 | 提升倍数 |
|---|---|---|---|
| 查询响应时间 | 5000ms | 50ms | 100x |
| 并发处理能力 | 1,000 QPS | 100,000 QPS | 100x |
| 存储扩展能力 | 10TB上限 | 理论无限 | ∞ |
| 系统可用性 | 99.5% | 99.99% | 提升50倍 |
分片最佳实践完整指南
阶段1:需求分析与现状评估
数据量评估
-- 评估当前数据量
SELECT TABLE_NAME,TABLE_ROWS,DATA_LENGTH / 1024 / 1024 / 1024 AS data_size_gb,INDEX_LENGTH / 1024 / 1024 / 1024 AS index_size_gb
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'your_database'
ORDER BY TABLE_ROWS DESC;-- 评估增长趋势
SELECT DATE(created_at) as date,COUNT(*) as daily_records
FROM your_large_table
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 30 DAY)
GROUP BY DATE(created_at)
ORDER BY date;
性能瓶颈识别
-- 查找慢查询
SELECT query_time,lock_time,rows_examined,rows_sent,sql_text
FROM mysql.slow_log
WHERE start_time >= DATE_SUB(NOW(), INTERVAL 1 DAY)
ORDER BY query_time DESC
LIMIT 20;-- 分析表锁等待
SHOW PROCESSLIST;
SHOW ENGINE INNODB STATUS\G
阶段2:分片方案设计
技术选型对比
| 技术方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 应用层分片 | 灵活可控,性能好 | 开发复杂度高 | 大型项目 |
| 中间件分片 | 透明性好,易部署 | 性能损耗,功能限制 | 中小型项目 |
| 数据库内置分片 | 原生支持,稳定 | 厂商绑定,扩展性差 | 企业级应用 |
分片数量规划
def calculate_optimal_shard_count(total_records, records_per_shard_target=5000000):"""计算最佳分片数量"""base_shard_count = max(1, total_records // records_per_shard_target)# 选择2的幂次,便于后续扩容shard_count = 1while shard_count < base_shard_count:shard_count *= 2return shard_count# 示例计算
current_records = 50000000 # 5000万条记录
shard_count = calculate_optimal_shard_count(current_records)
print(f"推荐分片数量: {shard_count}")
阶段3:原型验证与测试
性能基准测试
#!/bin/bash
# 分片前后性能对比测试脚本echo "开始性能基准测试..."# 测试单表查询性能
echo "测试单表查询..."
time mysql -u root -p database -e "
SELECT COUNT(*) FROM large_table WHERE user_id = 12345;
" > single_table_result.txt# 测试分片查询性能
echo "测试分片查询..."
time mysql -u root -p database -e "
SELECT COUNT(*) FROM large_table_shard_5 WHERE user_id = 12345;
" > sharded_table_result.txt# 对比结果
echo "性能对比结果:"
echo "单表查询时间:"
cat single_table_result.txt
echo "分片查询时间:"
cat sharded_table_result.txt
数据一致性验证
def verify_data_consistency():"""验证分片数据一致性"""original_count = query_single_db("SELECT COUNT(*) FROM users")sharded_count = 0for shard_id in range(8):shard_count = query_shard_db(shard_id, "SELECT COUNT(*) FROM users")sharded_count += shard_countprint(f"原始数据量: {original_count}")print(f"分片后总量: {sharded_count}")print(f"数据一致性: {'✓ 通过' if original_count == sharded_count else '✗ 失败'}")return original_count == sharded_count
阶段4:迁移实施策略
零停机迁移方案
-- 1. 创建分片表结构
CREATE TABLE orders_0 LIKE orders;
CREATE TABLE orders_1 LIKE orders;
-- ... 其他分片-- 2. 设置双写触发器
DELIMITER $$
CREATE TRIGGER orders_insert_trigger
AFTER INSERT ON orders
FOR EACH ROW
BEGINSET @shard_id = NEW.user_id % 8;SET @sql = CONCAT('INSERT INTO orders_', @shard_id, ' VALUES (', NEW.order_id, ',', NEW.user_id, '...)');-- 执行分片插入
END$$
DELIMITER ;-- 3. 历史数据迁移
INSERT INTO orders_0 SELECT * FROM orders WHERE user_id % 8 = 0;
INSERT INTO orders_1 SELECT * FROM orders WHERE user_id % 8 = 1;
-- ... 其他分片-- 4. 切换读流量到分片表
-- 5. 停止双写,移除原表
灰度发布策略
@Service
public class OrderServiceV2 {@Value("${sharding.enabled:false}")private boolean shardingEnabled;@Value("${sharding.user.percentage:0}")private int shardingUserPercentage;public List<Order> getUserOrders(Long userId) {// 灰度策略:按用户ID百分比启用分片boolean useSharding = shardingEnabled && (userId % 100) < shardingUserPercentage;if (useSharding) {return shardedOrderRepository.findByUserId(userId);} else {return originalOrderRepository.findByUserId(userId);}}
}
阶段5:运维监控体系
分片监控指标
# 分片监控脚本
import mysql.connector
import time
from datetime import datetimeclass ShardMonitor:def __init__(self, shard_configs):self.shards = shard_configsdef monitor_shard_health(self):"""监控分片健康状态"""for shard_id, config in enumerate(self.shards):try:conn = mysql.connector.connect(**config)cursor = conn.cursor()# 检查连接状态cursor.execute("SELECT 1")# 监控查询性能start_time = time.time()cursor.execute("SELECT COUNT(*) FROM orders")query_time = time.time() - start_time# 监控数据量cursor.execute("""SELECT COUNT(*) as record_count,MAX(created_at) as latest_recordFROM orders""")record_count, latest_record = cursor.fetchone()print(f"分片 {shard_id}: 健康 ✓")print(f" 查询耗时: {query_time:.3f}s")print(f" 记录数量: {record_count:,}")print(f" 最新记录: {latest_record}")# 告警阈值检查if query_time > 1.0: # 查询超过1秒告警self.send_alert(f"分片{shard_id}查询性能异常: {query_time:.3f}s")cursor.close()conn.close()except Exception as e:print(f"分片 {shard_id}: 异常 ✗ - {str(e)}")self.send_alert(f"分片{shard_id}连接失败: {str(e)}")def send_alert(self, message):"""发送告警"""timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")print(f"[ALERT {timestamp}] {message}")# 这里可以集成钉钉、邮件等告警方式# 使用示例
shard_configs = [{'host': 'shard-0', 'database': 'ecommerce', 'user': 'root', 'password': 'pass'},{'host': 'shard-1', 'database': 'ecommerce', 'user': 'root', 'password': 'pass'},# ... 其他分片配置
]monitor = ShardMonitor(shard_configs)
monitor.monitor_shard_health()
自动扩容策略
def auto_scaling_check():"""自动扩容检查"""for shard_id in range(current_shard_count):metrics = get_shard_metrics(shard_id)# 检查是否需要扩容if (metrics['cpu_usage'] > 80 and metrics['record_count'] > 10000000 andmetrics['query_latency'] > 500):print(f"分片 {shard_id} 需要扩容")# 触发扩容流程trigger_shard_expansion(shard_id)def trigger_shard_expansion(shard_id):"""触发分片扩容"""# 1. 创建新分片new_shard_id = create_new_shard()# 2. 数据重平衡rebalance_data(shard_id, new_shard_id)# 3. 更新路由规则update_routing_rules()print(f"分片扩容完成: {shard_id} -> {new_shard_id}")
常见问题与解决方案
Q1: 跨分片事务如何处理?
问题:分片后无法使用传统的ACID事务。
解决方案:
- 避免跨分片事务:优化业务逻辑,尽量保证相关数据在同一分片
- 最终一致性:使用分布式事务模式如Saga、TCC
- 补偿机制:设计回滚逻辑处理异常情况
// 分布式事务示例:使用Saga模式
@Service
public class OrderSagaService {public void createOrderWithSaga(OrderRequest request) {SagaTransaction saga = new SagaTransaction();try {// 步骤1:扣减库存saga.addStep(() -> inventoryService.deductStock(request.getProductId(), request.getQuantity()),() -> inventoryService.restoreStock(request.getProductId(), request.getQuantity()));// 步骤2:创建订单saga.addStep(() -> orderService.createOrder(request),() -> orderService.cancelOrder(request.getOrderId()));// 步骤3:扣减余额saga.addStep(() -> paymentService.deductBalance(request.getUserId(), request.getAmount()),() -> paymentService.refundBalance(request.getUserId(), request.getAmount()));saga.execute();} catch (Exception e) {saga.compensate(); // 执行补偿操作throw new OrderCreateException("订单创建失败", e);}}
}
Q2: 分片后如何进行全局查询?
问题:需要在所有分片中查询数据并聚合结果。
解决方案:
- 并行查询:同时查询所有分片,合并结果
- 数据冗余:在专门的聚合库中存储汇总数据
- 实时计算:使用流计算框架进行实时聚合
@Service
public class GlobalQueryService {@Autowiredprivate List<ShardDataSource> shardDataSources;@Autowiredprivate CompletableFuture<Void> executor;public OrderStatistics getGlobalOrderStatistics(Date startDate, Date endDate) {List<CompletableFuture<OrderStatistics>> futures = new ArrayList<>();// 并行查询所有分片for (ShardDataSource shard : shardDataSources) {CompletableFuture<OrderStatistics> future = CompletableFuture.supplyAsync(() -> {return shard.getOrderStatistics(startDate, endDate);}, executor);futures.add(future);}// 等待所有查询完成并聚合结果return futures.stream().map(CompletableFuture::join).reduce(new OrderStatistics(), (a, b) -> a.merge(b));}
}
Q3: 如何处理数据热点问题?
问题:某些分片的访问量远超其他分片。
解决方案:
- 分片键优化:重新设计分片键,确保均匀分布
- 动态路由:识别热点数据,动态调整路由策略
- 读写分离:为热点分片配置更多读副本
# 热点检测和处理
class HotspotDetector:def __init__(self, shard_count=8):self.shard_count = shard_countself.access_counters = [0] * shard_countself.threshold_ratio = 2.0 # 热点阈值:超过平均值2倍def record_access(self, shard_id):"""记录分片访问"""self.access_counters[shard_id] += 1def detect_hotspots(self):"""检测热点分片"""total_access = sum(self.access_counters)avg_access = total_access / self.shard_counthotspots = []for shard_id, count in enumerate(self.access_counters):if count > avg_access * self.threshold_ratio:hotspots.append({'shard_id': shard_id,'access_count': count,'ratio': count / avg_access})return hotspotsdef handle_hotspot(self, shard_id):"""处理热点分片"""# 1. 增加读副本self.add_read_replicas(shard_id, replica_count=2)# 2. 启用本地缓存self.enable_local_cache(shard_id)# 3. 考虑数据重新分片if self.is_severe_hotspot(shard_id):self.trigger_resharding(shard_id)
总结:分片技术的价值与未来
核心价值总结
数据分片技术为我们带来了:
- 无限扩展能力:突破单机存储和处理极限
- 线性性能提升:查询响应时间从秒级降到毫秒级
- 高可用保障:单点故障影响范围从100%降到1/N
- 成本效益优化:用普通硬件实现高端服务器的效果
实施成功要素
- 充分的前期规划:深入分析业务特征和数据模式
- 渐进式迁移:分阶段实施,降低风险
- 完善的监控体系:实时监控分片健康状态
- 团队能力建设:培养分布式系统运维能力
技术发展趋势
未来的数据分片技术将朝着以下方向发展:
- 智能化分片:AI驱动的分片策略优化
- 云原生分片:与Kubernetes深度集成
- 自动化运维:零人工干预的分片管理
- 多模态支持:同时支持关系型和非关系型数据
最佳实践清单
在实施数据分片时,请记住这个清单:
- 明确分片目标和成功指标
- 选择合适的分片策略(水平/垂直/混合)
- 设计优秀的分片键
- 建立完整的监控告警体系
- 制定详细的迁移计划
- 准备回滚方案
- 培训运维团队
- 建立分片运维文档
数据分片不是银弹,但它是解决海量数据挑战的有力武器。通过合理的设计和实施,我们可以构建出既高性能又可扩展的数据架构,为业务的快速发展提供坚实的技术支撑。
记住:分片的艺术在于平衡复杂性和性能,成功的关键在于深入理解业务需求,选择最适合的技术方案。
参考资料与延伸阅读
- 《高性能MySQL》 - Baron Schwartz等著,MySQL优化圣经
- 《分布式系统概念与设计》 - George Coulouris等著
- Apache ShardingSphere官方文档 - https://shardingsphere.apache.org/
- Vitess项目文档 - https://vitess.io/
- 《设计数据密集型应用》 - Martin Kleppmann著,分布式系统设计指南
相关工具推荐
- 分片中间件:Apache ShardingSphere, Vitess, MyCAT
- 监控工具:Prometheus + Grafana, Zabbix
- 压测工具:Apache JMeter, sysbench
- 数据迁移:gh-ost, pt-online-schema-change