怎么用数据库做动态网站北京seo网站管理
常见控件应用
- 复杂的控件操作
- 1.操作Ajax选项
- 2.滑动滑块操作
- WebDriver的特殊操作
- 元素class值包含空格
- property、attribute、text的区别
- 定位动态id
- 截图功能
- 页面截图
- 页面截图,返回截图的二进制数据
- 页面截图,返回base64的字符串
- 截取指定元素。先定位元素,然后截图
- 测试断言失败截图
- 获取焦点元素
- 颜色验证
- JavaScript的应用
- 高亮显示正在被操作的页面元素
- 修改页面元素属性
- 操作页面元素
- 操作滚动条
- 借助JavaScript操作纵向滚动条
- 借助JavaScript操作横向滚动条
- 操作内嵌滚动条
- 引申通过ActionChains 实现滚动条
- 操作span类型元素
- 通过id来定位元素,获取span的文本
- 通过JavaScript修改标签的文本
复杂的控件操作
1.操作Ajax选项
Ajax即Asynchronous JavaScript and XML(异步JavaScript和XML),是指一种创建交互式、快速动态网页应用的网页开发技术。通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。这意味着Ajax可以在不重新加载整个网页的情况下,对网页的某部分内容进行更新。搜狗搜索的搜索框使用了Ajax。被测地址为https://www.sogou.com/。单击一下搜狗搜索框,切换到搜索框后,会弹出推荐搜索的热词,这个效果就是Ajax效果。
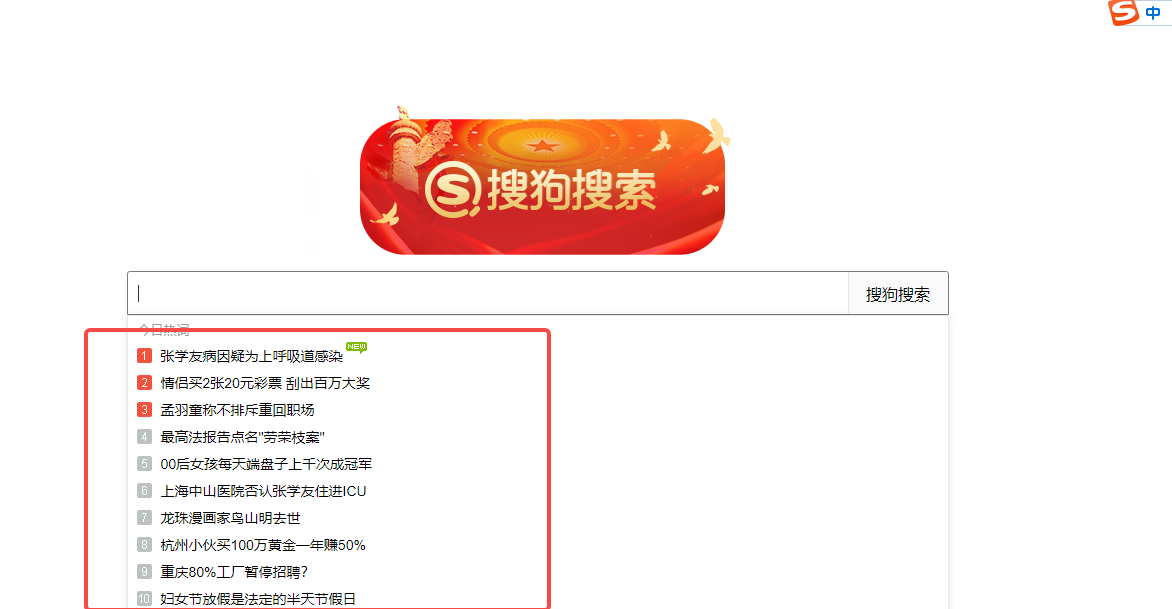
- 通过模拟键盘输入下键(↓)进行选项选择
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get('https://www.sogou.com/')ele1 = driver.find_element(By.ID,"query")
ele1.click()
sleep(1)
ele1.send_keys(Keys.ARROW_DOWN)
ele1.send_keys(Keys.ARROW_DOWN)
ele1.send_keys(Keys.ARROW_DOWN)
sleep(5)
driver.quit()
- 通过模糊匹配选择选项。
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get('https://www.sogou.com/')
driver.find_element(By.ID,'query').send_keys('storm')
sleep(1)
sercont = driver.find_element(By.XPATH,'//*[@id="vl"]/div[1]/ul/li[contains(.,"形容词")]').click()
sleep(5)
driver.quit()
上述代码先在搜索框中输入了“storm”,然后从匹配的选项中选择了带有“形容词”字样的选项,再进行搜索操作(搜索“storm+形容词”)。
- 固定选择某一个位置的选项。
Ajax悬浮框的内容会发生变化(根据一定的推荐算法),而某些时候你可能只是想固定选择悬浮框中的某一个选项,如第二项,这时可以参考下面的代码
from selenium import webdriver
from time import sleepdriver = webdriver.Chrome()
driver.get('https://www.sogou.com/')
driver.find_element('id','query').send_keys('storm')
sleep(1)
sercont = driver.find_element('xpath','//*[@id="vl"]/div[1]/ul/li[2]').click() # li[2]选择第2项
sleep(5)
driver.quit()
2.滑动滑块操作
在实际项目中,你可能会遇到以下场景:在某些页面中需要从左到右拖动滑块进行验证,然后才能进行下一步操作。
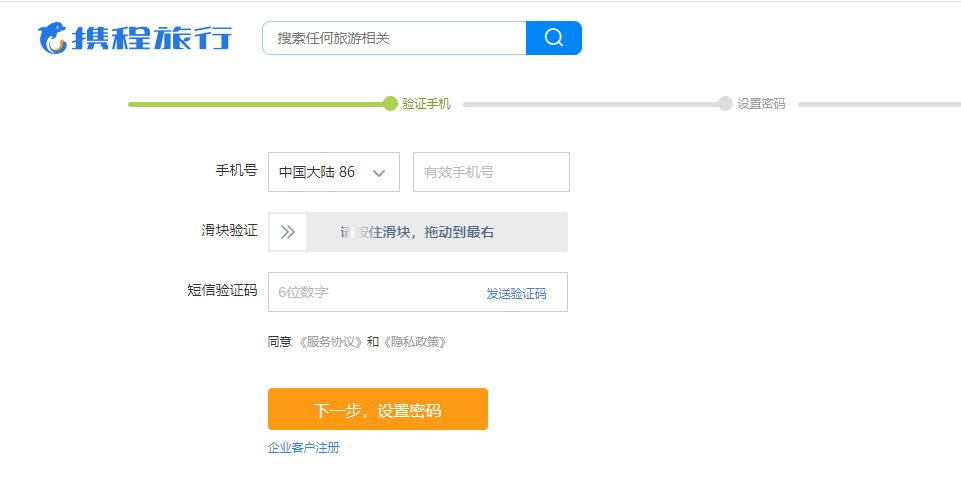

可以看出,无论是滑块本身,还是滑块所在的框,都是div元素。
- 操作思路
- 定位到滑块。
- 计算滑块框的宽度。
- 然后将滑块向右拖动框的宽度的距离。
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get('https://passport.ctrip.com/user/reg/home')
driver.find_element(By.XPATH,'//*[@id="agr_pop"]/div[3]/a[2]').click()
sleep(2)
# 获取滑块
slider = driver.find_element(By.XPATH,'//*[@id="slideCode"]/div[1]/div[2]')
# 获取整个滑块框
ele = driver.find_element(By.ID,'slideCode')
# 需要使用到Actions的方法来进行拖动
ActionChains(driver)\.drag_and_drop_by_offset(slider,ele.size['width'], ele.size ['height'])\.perform()
# 这样也行,向右拖动一定的距离,长度是滑块框的宽度
# ActionChains(driver).drag_and_drop_by_offset(slider,ele.size['width'], 0).perform()
sleep(2)
driver.quit()
WebDriver的特殊操作
元素class值包含空格
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>元素class值带空格</title>
</head>
<body>
Please input your name: <input class="hello storm">
</body>
</html>
- 使用空格前面或后面的部分来定位元素
rom selenium import webdriver
from time import sleep
import osdriver = webdriver.Chrome()
html_file = 'File:///' + os.getcwd() + os.sep + 'myhtml7_1.html'
driver.get(html_file)
# 使用空格前面或后面的部分来定位元素
driver.find_element_by_class_name('hello').send_keys('Storm')
sleep(2)
driver.quit()
- 使用CSS来定位元素,空格用“.”代替
from selenium import webdriver
from time import sleep
import osdriver = webdriver.Chrome()
html_file = 'File:///' + os.getcwd() + os.sep + 'myhtml7_1.html'
driver.get(html_file)
# 使用CSS来定位元素,空格用"."代替
driver.find_element_by_css_selector('.hello.storm').send_keys('Storm')
sleep(2)
driver.quit()
property、attribute、text的区别
- get_property就是用来获取元素属性的,目标元素id和name就可以通过该方法获取;
- get_attribute(“value”)就是用来获取文本框中输入的内容的;
- text属性就是元素本身的文字显示;
- “property”是DOM中的属性,是JavaScript里的对象;“attribute”是HTML标签上的特性,它的值只能是字符串。
定位动态id
输入框有id属性,id的值由两大部分构成,前面是“auto-id-”字符,后面是一串数字。当你刷新页面的时候会发现,这串数字会发生变化,这个id就是动态id。
那如何定位动态id元素呢?
- 使用其他方式定位如果该元素有其他唯一属性值,如class name、name等,我们可以使用这些属性来定位。
- 根据相对关系定位根据父子、兄弟相邻节点定位
- 根据部分元素属性定位
XPath提供了3种非常强大的方法来支持定位部分属性值。contains(a, b):如果a中含有字符串b,则返回True,否则返回False。starts-with(a, b):如果a以字符串b开头,则返回True,否则返回False。ends-with(a, b):如果a以字符串b结尾,返回True,否则返回False。
使用contains关键字
from selenium import webdriver
from time import sleepdriver = webdriver.Chrome()
driver.get('https://www.126.com/')
driver.find_element_by_link_text('密码登录').click()
sleep(2)
driver.switch_to.frame(0)
driver.find_element_by_xpath('//input[contains(@id,"auto-id-")]').send_keys('storm')
sleep(2)
driver.quit()
使用starts-with关键字
from selenium import webdriver
from time import sleepdriver = webdriver.Chrome()
driver.get('https://www.126.com/')
driver.find_element_by_link_text('密码登录').click()
sleep(2)
driver.switch_to.frame(0)
driver.find_element_by_xpath('//input[starts-with(@id,"auto-id-")]').send_keys('storm')
sleep(2)
driver.quit()
截图功能
页面截图
截取当前页面,保存成.png图片
from selenium import webdriverdriver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.save_screenshot('a.png') # 截取当前页面,保存到当前目录,保存成.png图片
# driver.get_screenshot_as_file('a.png'),和上面功能相同
driver.quit()
脚本执行后,程序会在脚本所在目录生成一张名为“a.png”的图片。为了避免图片名重复,我们将图片名修改为“脚本名+时间戳+.png”的格式
from selenium import webdriver
import os
import timescript_name = os.path.basename(__file__).split('.')[0] # 获取当前脚本的名称,不包含扩展名
file_name = script_name + '_' + str(time.time()) + '.png' #组合成图片名
# print(file_name)
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.save_screenshot(file_name) # 截取当前页面,保存成".png"图片
driver.quit()
页面截图,返回截图的二进制数据
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
a = driver.get_screenshot_as_png() # 截图,返回截图的二进制数据
print(type(a))
print(a)
driver.quit()
页面截图,返回base64的字符串
截取指定元素。先定位元素,然后截图
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
driver.find_element_by_id('su').screenshot('d:\\A\\button.png') # 定位元素,然后截图
driver.quit()
测试断言失败截图
这里我们构造一个断言失败的场景:打开百度首页,在搜索框中输入“Storm”,然后断言搜索框中的文字是不是“storm”,因大小写不匹配执行截图操作。
from selenium import webdriverdriver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
driver.find_element_by_id('kw').send_keys('Storm')
if driver.find_element_by_id('kw').text == "storm":pass
else:driver.save_screenshot('d:\\A\\a.png')
driver.quit()
获取焦点元素
当浏览器访问某个页面时,页面中会有默认的焦点元素。例如,我们访问百度首页时,默认的焦点元素是搜索框,即打开百度首页后,光标自动定位在搜索框。这时候我们可以使用“driver.switch_to.active_element”来获取搜索框元素。
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 获取当前焦点所在元素的attribute信息
id = driver.switch_to.active_element.get_attribute('id')print(id)
driver.quit()
颜色验证
在测试过程中,偶尔会需要验证某事物的颜色。但问题是网络上对颜色的定义可能采用了不同的方式,如HEX、RGB、RGBA、HSLA。如何去判断颜色是否符合预期呢?首先,你需要引入“Color”的包。
from selenium.webdriver.support.color import Color
创建颜色对象
HEX_COLOUR = Color.from_string('#2F7ED8')
RGB_COLOUR = Color.from_string('rgb(255, 255, 255)')
RGB_COLOUR = Color.from_string('rgb(40%, 20%, 40%)')
RGBA_COLOUR = Color.from_string('rgba(255, 255, 255, 0.5)')
RGBA_COLOUR = Color.from_string('rgba(40%, 20%, 40%, 0.5)')
HSL_COLOUR = Color.from_string('hsl(100, 0%, 50%)')
HSLA_COLOUR = Color.from_string('hsla(100, 0%, 50%, 0.5)')
还可以指定基本颜色
BLACK = Color.from_string('black')
CHOCOLATE = Color.from_string('chocolate')
HOTPINK = Color.from_string('hotpink')
如果元素未设置颜色,则有时浏览器将返回“透明”的颜色值。Color类也支持以下内容。
TRANSPARENT = Color.from_string('transparent')
现在可以安全地查询元素以获取其颜色或背景色,直到任何响应都会被正确解析并转换为有效的Color对象。
login_button_colour = Color.from_string(driver.find_element(By.ID,'login').value_of_css_property('color'))login_button_background_colour = Color.from_string(driver.find_element(By.ID,'login').value_of_css_property('background-color'))
还可以直接比较颜色对象。
assert login_button_background_colour == HOTPINK
可以将颜色转换为以下格式之一,并执行静态验证。
assert login_button_background_colour.hex == '#ff69b4'
assert login_button_background_colour.rgba == 'rgba(255, 105, 180, 1)'
assert login_button_background_colour.rgb == 'rgb(255, 105, 180)'
JavaScript的应用
JavaScript是Web页面的编程语言。Selenium提供了execute_script方法,用来执行JavaScript,从而完成一些特殊的操作。
高亮显示正在被操作的页面元素
测试过程中,我们可以借助JavaScript高亮显示正在被操作的元素。

from selenium.webdriver.common.by import Bydef highLightElement(driver, element):'''#封装高亮显示页面元素的方法:使用js代码将页面元素对象的背景颜色设置为绿色,边框设置为红色:param driver::param element::return:'''driver.execute_script("arguments[0].setAttribute('style', arguments[1]);", element,"background: green; border: 2px solid red;")if __name__ == '__main__':from selenium import webdriverfrom time import sleepdriver = webdriver.Chrome()driver.get('https://www.baidu.com/')ele = driver.find_element(By.ID,'kw')highLightElement(driver, ele)sleep(3)driver.quit()
修改页面元素属性
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>日期时间控件</title>
</head>
<body>
<input type="date" name="name1" id="id1" readonly>
</body>
</html>
from selenium import webdriver
from time import sleep
import osfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
html_file = 'File:///' + os.getcwd() + os.sep + 'myhtml.html'
driver.get(html_file)
sleep(2)
driver.find_element(By.TAG_NAME,'input').send_keys('002020/06/06')
sleep(5)
driver.quit()执行脚本,虽然没有报错,但是内容并没写入文本框。接下来我们通过JavaScript先删除掉readonly属性,再来输入内容。
from selenium import webdriver
from time import sleep
import osfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
html_file = 'File:///' + os.getcwd() + os.sep + 'myhtml.html'
driver.get(html_file)
sleep(2)
js2 = "document.getElementById('id1').removeAttribute('readonly')"
driver.execute_script(js2)driver.find_element(By.TAG_NAME,'input').send_keys('002020/06/06')
sleep(5)
driver.quit()

操作页面元素
from selenium import webdriver
from time import sleepdriver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
ele1JS = "document.getElementById('kw').value='storm'"
ele2JS = "document.getElementById('su').click()"
driver.execute_script(ele1JS)
sleep(3)
driver.execute_script(ele2JS)
sleep(3)
driver.quit()
运行成功,通过removeAttribute方法成功删除掉了readonly属性并输入了内容。另外,再提供以下几种删除元素属性的方法
# js = "document.getElementById('c-date1').removeAttribute('readonly')" # 原生js,移除属性
# js = "$('input[id=c-date1]').removeAttr('readonly')" # jQuery,移除属性
# js = "$('input[id=c-date1]').attr('readonly',False)" # jQuery,设置为False
# js = "$('input[id=c-date1]').attr('readonly','')" # jQuery,设置为空
ele = driver.find_element_by_id('reg_butt')
js1 = "arguments[0].click()"
driver.execute_script(js1,ele)
操作滚动条
借助JavaScript操作纵向滚动条
from selenium import webdriver
from time import sleepfrom selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
# driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
driver.find_element(By.ID,'kw').send_keys("storm")
driver.find_element(By.ID,'su').click()
js1 = "window.scrollTo(0, document.body.scrollHeight)"# 滑动滚动条到底部
js2 = "window.scrollTo(0,0)"# 滑动到顶端
js3 = "window.scrollTo(0,200)"# 向下滑动200像素
js4 = "arguments[0].scrollIntoView();" # 滑动到指定元素
sleep(2) #等待页面加载完,注意观察滚动条目前处于最上方
driver.execute_script(js1) #执行js1,将滚动条滑到最下方
sleep(2) #加等待时间,看效果
driver.execute_script(js2) #执行js2,将滚动条滑到最上方
sleep(2) #加等待时间,看效果
driver.execute_script(js3) #执行js3,将滚动条向下滑动到200像素
sleep(2) #加等待时间,看效果
driver.execute_script(js2) #执行js2,将滚动条滑到最上方
sleep(2)
ele = driver.find_element(By.ID,'con-ar') #定位一个元素
driver.execute_script(js4,ele) #滑动到上面定位的元素的地方
sleep(2)
driver.quit()
借助JavaScript操作横向滚动条
from selenium import webdriver
from time import sleepdriver = webdriver.Chrome()
# driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
driver.find_element('id','kw').send_keys("storm")
driver.find_element('id','su').click()
driver.set_window_size(500,500) #缩小浏览器窗口,使之出现横向滚动条
js5 = "window.scrollTo(document.body.scrollWidth,0)"
js6 = "window.scrollTo(0,0)"
js7 = "window.scrollTo(200,0)"
driver.execute_script(js5) #滑动到最右边
sleep(2)
driver.execute_script(js6) #滑动到最左边
sleep(2)
driver.execute_script(js7) #向右滑动200像素
sleep(2)
driver.quit()
操作内嵌滚动条
内嵌滚动条一般嵌在一个iframe里面,先切换到要操作的滚动条所在的iframe,然后正常调用JavaScript即可。
from selenium import webdriver
from time import sleepdriver = webdriver.Chrome()
# driver = webdriver.Firefox()
driver.get("http://sahitest.com/demo/iframesTest.htm")
sleep(2)
driver.switch_to.frame(1)
js5 = "window.scrollTo(0,200)"
driver.execute_script(js5) #向下滑动200像素
sleep(2)
driver.quit()
引申通过ActionChains 实现滚动条
import time
from time import sleepfrom selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.actions.wheel_input import ScrollOrigin'''
scroll_to_element: 滚动条移动到元素
'''
def test_can_scroll_to_element(driver):driver.get("https://selenium.dev/selenium/web/scrolling_tests/frame_with_nested_scrolling_frame_out_of_view.html")time.sleep(1)iframe = driver.find_element(By.TAG_NAME, "iframe")ActionChains(driver)\.scroll_to_element(iframe)\.perform()time.sleep(5)assert _in_viewport(driver, iframe)def test_can_scroll_from_viewport_by_amount(driver):driver.get("https://selenium.dev/selenium/web/scrolling_tests/frame_with_nested_scrolling_frame_out_of_view.html")footer = driver.find_element(By.TAG_NAME, "footer")delta_y = footer.rect['y']print(delta_y)ActionChains(driver)\.scroll_by_amount(0, delta_y)\.perform()sleep(0.5)assert _in_viewport(driver, footer)def test_can_scroll_from_element_by_amount(driver):driver.get("https://selenium.dev/selenium/web/scrolling_tests/frame_with_nested_scrolling_frame_out_of_view.html")iframe = driver.find_element(By.TAG_NAME, "iframe")scroll_origin = ScrollOrigin.from_element(iframe)ActionChains(driver)\.scroll_from_origin(scroll_origin, 0, 200)\.perform()sleep(0.5)driver.switch_to.frame(iframe)checkbox = driver.find_element(By.NAME, "scroll_checkbox")sleep(3)assert _in_viewport(driver, checkbox)def test_can_scroll_from_element_with_offset_by_amount(driver):driver.get("https://selenium.dev/selenium/web/scrolling_tests/frame_with_nested_scrolling_frame_out_of_view.html")footer = driver.find_element(By.TAG_NAME, "footer")scroll_origin = ScrollOrigin.from_element(footer, 0, -50)ActionChains(driver)\.scroll_from_origin(scroll_origin, 0, 200)\.perform()sleep(2)iframe = driver.find_element(By.TAG_NAME, "iframe")driver.switch_to.frame(iframe)checkbox = driver.find_element(By.NAME, "scroll_checkbox")assert _in_viewport(driver, checkbox)def test_can_scroll_from_viewport_with_offset_by_amount(driver):driver.get("https://selenium.dev/selenium/web/scrolling_tests/frame_with_nested_scrolling_frame.html")sleep(2)scroll_origin = ScrollOrigin.from_viewport(10, 10)ActionChains(driver)\.scroll_from_origin(scroll_origin, 0, 200)\.perform()sleep(3)iframe = driver.find_element(By.TAG_NAME, "iframe")driver.switch_to.frame(iframe)checkbox = driver.find_element(By.NAME, "scroll_checkbox")assert _in_viewport(driver, checkbox)def _in_viewport(driver, element):script = ("for(var e=arguments[0],f=e.offsetTop,t=e.offsetLeft,o=e.offsetWidth,n=e.offsetHeight;\n""e.offsetParent;)f+=(e=e.offsetParent).offsetTop,t+=e.offsetLeft;\n""return f<window.pageYOffset+window.innerHeight&&t<window.pageXOffset+window.innerWidth&&f+n>\n""window.pageYOffset&&t+o>window.pageXOffset")return driver.execute_script(script, element)
操作span类型元素
实际项目中可能会遇到span类型元素,针对此类型元素,有一些特殊的操作
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>span类型元素测试</title>
</head>
<body><span id="span_id">span的文本</span>
</body>
</html>
通过id来定位元素,获取span的文本
from selenium import webdriver
import os'''
定位元素,通过text取文本
'''
driver = webdriver.Chrome()
html_file = 'File:///' + os.getcwd() + os.sep + 'myhtml.html'
driver.get(html_file)
ele = driver.find_element('id','span_id')
print(ele.text)
driver.quit()
通过JavaScript修改标签的文本
from selenium import webdriver
from time import sleep
import os'''
通过js的方式修改span中间的值
js = 'document.getElementById("span_id").innerText="aaaa"'
'''
driver = webdriver.Chrome()
html_file = 'File:///' + os.getcwd() + os.sep + 'myhtml.html'
driver.get(html_file)
sleep(2)
js1 = "document.getElementById('span_id').innerText='aaa'"
driver.execute_script(js1)
sleep(2)
driver.quit()