南昌网站建设 南昌做网站公司google chrome官网
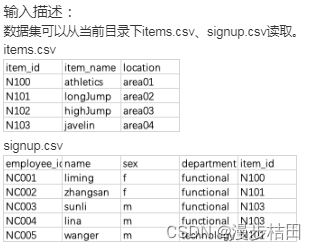
1.某公司计划举办一场运动会,现有运动会项目数据集items.csv。 包含以下字段:
item_id:项目编号;
item_name:项目名称;
location:比赛场地。
有员工报名情况数据集signup.csv。包含以下字段:
employee_id:员工编号;
name:员工姓名;
sex:性别;
department:所属部门;
item_id:报名项目id
请你统计职能部门(functional)中报名标枪(javenlin)的所有员工的员工编号(employee_id)、姓名(name)及性别(sex)。
import pandas as pditems = pd.read_csv("items.csv", sep=",")
signup = pd.read_csv("signup.csv", sep=",")
pd.set_option("display.unicode.east_asian_width", True)
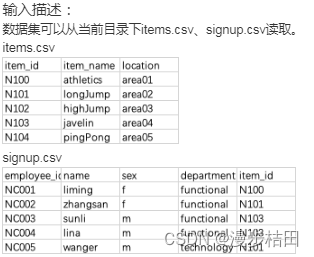
data = pd.merge(items, signup, how="inner", on="item_id")print(data[(data.department == "functional") & (data.item_name == "javelin")][["employee_id", "name", "sex"]].reset_index(drop=True))2.某公司计划举办一场运动会,现有运动会项目数据集items.csv。 包含以下字段:
item_id:项目编号;
item_name:项目名称;
location:比赛场地。
有员工报名情况数据集signup.csv。包含以下字段:
employee_id:员工编号;
name:员工姓名;
sex:性别;
department:所属部门;
item_id:报名项目id
请你输出报名的各个项目情况(不包含没人报名的项目)对应的透视表。
import pandas as pdsignup = pd.read_csv("signup.csv")
items = pd.read_csv("items.csv")
x = pd.merge(signup, items, on="item_id")
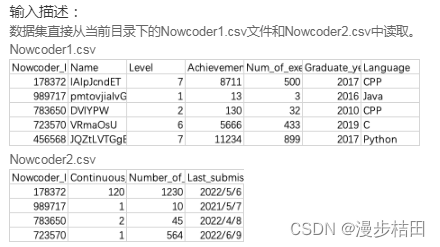
y = x.pivot_table(index=["sex", "department"],columns="item_name",aggfunc={"employee_id": "size"},fill_value=0,)print(y)3.现有一个Nowcoder1.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
另外一个Nowcoder2.csv文件记录了用户的活跃情况,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
两张表分开查看对于运营同学太困难了,请帮助他通过用户ID将两张表合并输出。
import pandas as pdpd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
nd1 = pd.read_csv("Nowcoder1.csv")
nd2 = pd.read_csv("Nowcoder2.csv")
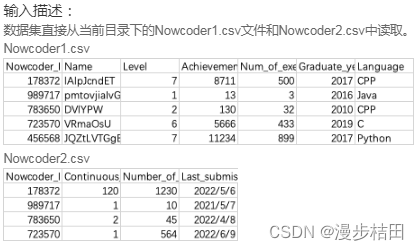
df = pd.merge(nd1, nd2, on="Nowcoder_ID")print(df)4.现有一个Nowcoder1.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
另外一个Nowcoder2.csv文件记录了用户的活跃情况,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
如果你想要的信息各自在两个csv文件中,你该怎么输出?同时输出用户的名字、刷题量和代码提交次数。
import pandas as pdpd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)
nd1 = pd.read_csv("Nowcoder1.csv")
nd2 = pd.read_csv("Nowcoder2.csv")
df = pd.merge(nd1, nd2, on="Nowcoder_ID")print(df[["Name", "Num_of_exercise", "Number_of_submissions"]])5.现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你统计消费金额最多的前3名用户。
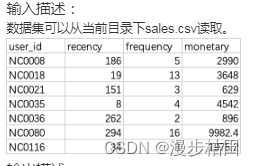
import pandas as pdsales = pd.read_csv("sales.csv")print(sales.sort_values(by="monetary", ascending=False).reset_index(drop=True).head(3))6.现有一个Nowcoder.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
牛牛在查看这些数据的时候,等级都是混乱的,他想按照1-7级的递增序查看这些用户数据,你能帮他输出一下吗?
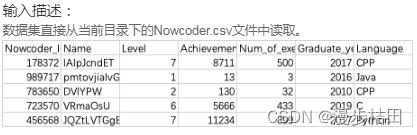
import pandas as pdpd.set_option("display.width", 300)
pd.set_option("display.max_rows", None)
pd.set_option("display.max_columns", None)nd = pd.read_csv("Nowcoder.csv")print(nd.sort_values(by="Level"))7.现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你分别对每个用户的每个消费特征进行评分。
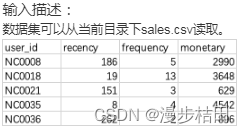
import pandas as pddata = pd.read_csv("sales.csv")data["R_Quartile"] = pd.qcut(data["recency"], [0, 0.25, 0.5, 0.75, 1], ["4", "3", "2", "1"]
).astype("int")
data["F_Quartile"] = pd.qcut(data["frequency"], [0, 0.25, 0.5, 0.75, 1], ["1", "2", "3", "4"]
).astype("int")
data["M_Quartile"] = pd.qcut(data["monetary"], [0, 0.25, 0.5, 0.75, 1], ["1", "2", "3", "4"]
).astype("int")print(data.head())8.现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你统计最有价值的用户中消费金额最多的前5名用户。
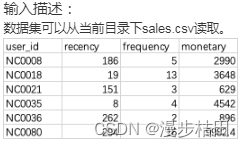
import pandas as pddata = pd.read_csv("sales.csv")R = pd.qcut(data["recency"], [0, 0.25, 0.5, 0.75, 1.0], ["4", "3", "2", "1"]).astype(str)
F = pd.qcut(data["frequency"], [0, 0.25, 0.5, 0.75, 1.0], ["1", "2", "3", "4"]).astype(str)
M = pd.qcut(data["monetary"], [0, 0.25, 0.5, 0.75, 1.0], ["1", "2", "3", "4"]).astype(str)
data["RFMClass"] = R + F + Mprint(data.head())
print(data[data["RFMClass"] == "444"].sort_values("monetary", ascending=False))