建设政府门户网站学生网页制作成品
一、 search检索文档
ES支持两种基本方式检索;
- 通过REST request uri 发送搜索参数 (uri +检索参数);
- 通过REST request body 来发送它们(uri+请求体);
1、信息检索
API: https://www.elastic.co/guide/en/elasticsearch/reference/7.x/getting-started-search.html
请求参数方式检索
GET bank/_search?q=*&sort=account_number:asc
说明:
q=* # 查询所有
sort # 排序字段
asc #升序检索bank下所有信息,包括type和docs
GET bank/_search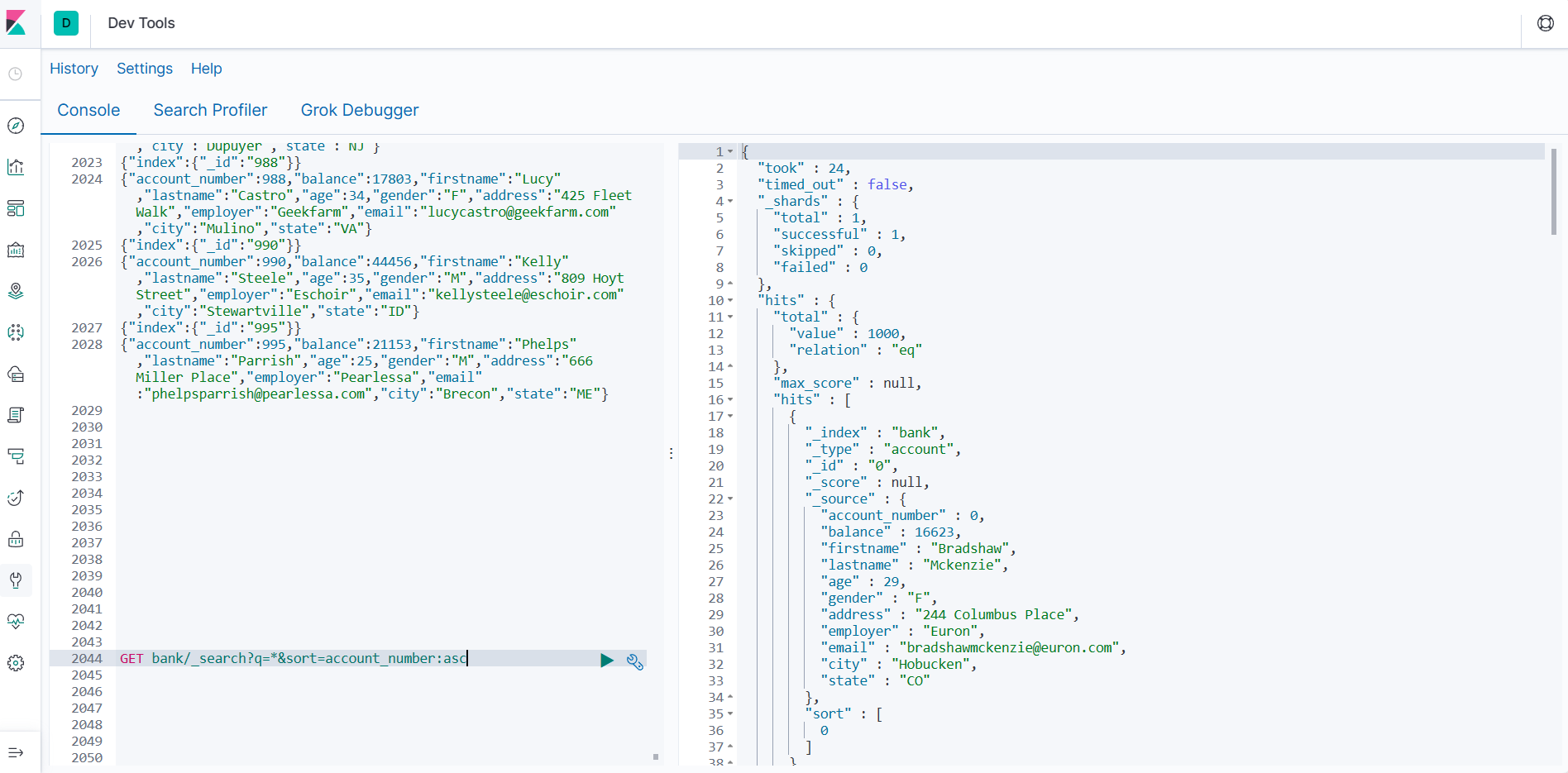
2、查询基本语法–match_all
示例 使用时不要加#注释内容
GET bank/_search
{"query": { # 查询的字段"match_all": {}},"from": 0, # 从第几条文档开始查"size": 5,"_source":["balance"],"sort": [{"account_number": { # 返回结果按哪个列排序"order": "desc" # 降序}}]
}
_source为要返回的字段
3、查询基本语法–match
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索(模糊匹配)
- 基本类型(非字符串),精确控制
GET bank/_search
{"query": {"match": {"account_number": "20"}}
}- 字符串,全文检索(模糊匹配)
GET bank/_search
{"query": {"match": {"address": "kings"}}
}4、query/match_phrase [不拆分匹配]
GET bank/_search
{"query": {"match_phrase": {"address": "mill road" # 就是说不要匹配只有mill或只有road的,要匹配mill road一整个子串}}
}5、query/multi_math【多字段匹配,在每一个字段里面查找,相当于or,并且是分词匹配(默认都是分词)】
state或者address中包含mill,并且在查询过程中,会对于查询条件进行分词。
GET bank/_search
{"query": {"multi_match": { # 前面的match仅指定了一个字段。"query": "mill","fields": [ # state和address有mill子串 不要求都有"state","address"]}}
}6、query/bool/must复合查询(相当于and)
GET bank/_search
{"query": {"bool": {"must": [{"match": {"gender": "M"}},{"match": {"address": "mill"}}],"must_not": [{"match": {"age": "18"}}],"should": [{"match": {"lastname": "Wallace"}}]}}
}should:应该达到should列举的条件,
如果到达会增加相关文档的评分,并不会改变查询的结果。如果query中只有should且只有一种匹配规则,那么should的条件就会被作为默认匹配条件二区改变查询结果。
7、query/filter【结果过滤】
- must 贡献得分
- should 贡献得分
- must_not 不贡献得分
- filter 不贡献得分
GET bank/_search
{"query": {"bool": {"must": [{ "match": {"address": "mill" } }],"filter": { # query.bool.filter"range": {"balance": { # 哪个字段"gte": "10000","lte": "20000"}}}}}
}8、query/term
和match一样。匹配某个属性的值。
- 全文检索字段用match,
- 其他
非text字段匹配用term。
不要使用term来进行文本字段查询
es默认存储text值时用分词分析,所以要搜索text值,使用match
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/query-dsl-term-query.html
- 字段.keyword:要一一匹配到
- match_phrase:子串包含即可
使用term匹配查询
GET bank/_search
{"query": {"term": {"address": "mill Road"}}
}9、aggs/agg1(聚合)
前面介绍了存储、检索,但还没介绍分析
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于SQL Group by和SQL聚合函数。
在elasticsearch中,执行搜索返回this(命中结果),并且同时返回聚合结果,把以响应中的所有hits(命中结果)分隔开的能力。这是非常强大且有效的,你可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的API啦避免网络往返。
例:搜索address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情
# 分别为包含mill、,平均年龄、
GET bank/_search
{"query": { # 查询出包含mill的"match": {"address": "Mill"}},"aggs": { #基于查询聚合"ageAgg": { # 聚合的名字,随便起"terms": { # 看值的可能性分布"field": "age","size": 10}},"ageAvg": { "avg": { # 看age值的平均"field": "age"}},"balanceAvg": {"avg": { # 看balance的平均"field": "balance"}}},"size": 0 # 不看详情
}查询结果:
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4, // 命中4条"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : { // 第一个聚合的结果"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 38, # age为38的有2条"doc_count" : 2},{"key" : 28,"doc_count" : 1},{"key" : 32,"doc_count" : 1}]},"ageAvg" : { // 第二个聚合的结果"value" : 34.0 # balance字段的平均值是34},"balanceAvg" : {"value" : 25208.0}}
}aggs/aggName/aggs/aggName子聚合
复杂:
按照年龄聚合,并且求这些年龄段的这些人的平均薪资
复杂:
按照年龄聚合,并且求这些年龄段的这些人的平均薪资
GET bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": { # 看分布"field": "age","size": 100},"aggs": { # 与terms并列"ageAvg": { #平均"avg": {"field": "balance"}}}}},"size": 0
}输出结果:
{"took" : 49,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"ageAvg" : {"value" : 28312.918032786885}},{"key" : 39,"doc_count" : 60,"ageAvg" : {"value" : 25269.583333333332}},{"key" : 26,"doc_count" : 59,"ageAvg" : {"value" : 23194.813559322032}},{"key" : 32,"doc_count" : 52,"ageAvg" : {"value" : 23951.346153846152}},{"key" : 35,"doc_count" : 52,"ageAvg" : {"value" : 22136.69230769231}},{"key" : 36,"doc_count" : 52,"ageAvg" : {"value" : 22174.71153846154}},{"key" : 22,"doc_count" : 51,"ageAvg" : {"value" : 24731.07843137255}},{"key" : 28,"doc_count" : 51,"ageAvg" : {"value" : 28273.882352941175}},{"key" : 33,"doc_count" : 50,"ageAvg" : {"value" : 25093.94}},{"key" : 34,"doc_count" : 49,"ageAvg" : {"value" : 26809.95918367347}},{"key" : 30,"doc_count" : 47,"ageAvg" : {"value" : 22841.106382978724}},{"key" : 21,"doc_count" : 46,"ageAvg" : {"value" : 26981.434782608696}},{"key" : 40,"doc_count" : 45,"ageAvg" : {"value" : 27183.17777777778}},{"key" : 20,"doc_count" : 44,"ageAvg" : {"value" : 27741.227272727272}},{"key" : 23,"doc_count" : 42,"ageAvg" : {"value" : 27314.214285714286}},{"key" : 24,"doc_count" : 42,"ageAvg" : {"value" : 28519.04761904762}},{"key" : 25,"doc_count" : 42,"ageAvg" : {"value" : 27445.214285714286}},{"key" : 37,"doc_count" : 42,"ageAvg" : {"value" : 27022.261904761905}},{"key" : 27,"doc_count" : 39,"ageAvg" : {"value" : 21471.871794871793}},{"key" : 38,"doc_count" : 39,"ageAvg" : {"value" : 26187.17948717949}},{"key" : 29,"doc_count" : 35,"ageAvg" : {"value" : 29483.14285714286}}]}}
}复杂子聚合:查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": { # 看age分布"field": "age","size": 100},"aggs": { # 子聚合"genderAgg": {"terms": { # 看gender分布"field": "gender.keyword" # 注意这里,文本字段应该用.keyword},"aggs": { # 子聚合"balanceAvg": {"avg": { # 男性的平均"field": "balance"}}}},"ageBalanceAvg": {"avg": { #age分布的平均(男女)"field": "balance"}}}}},"size": 0
}输出结果:
{"took" : 119,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1000,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"ageAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : 31,"doc_count" : 61,"genderAgg" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "M","doc_count" : 35,"balanceAvg" : {"value" : 29565.628571428573}},{"key" : "F","doc_count" : 26,"balanceAvg" : {"value" : 26626.576923076922}}]},"ageBalanceAvg" : {"value" : 28312.918032786885}}].......//省略其他}}
}二、Mapping字段映射
1、创建和查看映射
创建映射PUT /my_index
创建索引并指定映射
PUT /my_index
{"mappings": {"properties": {"age": {"type": "integer"},"email": {"type": "keyword" # 指定为keyword},"name": {"type": "text" # 全文检索。保存时候分词,检索时候进行分词匹配}}}
}查看映射GET /my_index
2、添加某个字段的映射
添加新的字段映射PUT /my_index/_mapping
PUT /my_index/_mapping
{"properties": {"employee-id": {"type": "keyword","index": false # 字段不能被检索。检索}}
}这里的 “index”: false,表明新增的字段不能被检索,只是一个冗余字段。
3、更新映射_reindex
ES不能更新映射
对于已经存在的字段映射,我们不能更新。更新必须创建新的索引,进行数据迁移。
POST _reindex
{"source": {"index": "bank","type": "account"},"dest": {"index": "newbank"}
}
🚩总结:
要更新索引那只能创建新的索引,并且将原来的数据进行转移
三、分词
1、简介_analyze
一个tokenizer(分词器)接收一个字符流,将之分割为独立的tokens(词元,通常是独立的单词),然后输出tokens流。
例如:whitespace tokenizer遇到空白字符时分割文本。它会将文本"Quick brown fox!"分割为[Quick,brown,fox!]
该tokenizer(分词器)还负责记录各个terms(词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term(词条)所代表的原始word(单词)的start(起始)和end(结束)的character offsets(字符串偏移量)(用于高亮显示搜索的内容)。
elasticsearch提供了很多内置的分词器(标准分词器),可以用来构建custom analyzers(自定义分词器)。
关于分词器: https://www.elastic.co/guide/en/elasticsearch/reference/7.6/analysis.html
POST _analyze
{"analyzer": "standard","text": "The 2 Brown-Foxes bone."
}执行结果:
{"tokens" : [{"token" : "the","start_offset" : 0,"end_offset" : 3,"type" : "<ALPHANUM>","position" : 0},{"token" : "2","start_offset" : 4,"end_offset" : 5,"type" : "<NUM>","position" : 1},{"token" : "brown","start_offset" : 6,"end_offset" : 11,"type" : "<ALPHANUM>","position" : 2},{"token" : "foxes","start_offset" : 12,"end_offset" : 17,"type" : "<ALPHANUM>","position" : 3},{"token" : "bone","start_offset" : 18,"end_offset" : 22,"type" : "<ALPHANUM>","position" : 4}]
}对于中文,我们需要安装额外的分词器
2、安装ik分词器
所有的语言分词,默认使用的都是“Standard Analyzer”,但是这些分词器针对于中文的分词,并不友好。为此需要安装中文的分词器。
注意:不能用默认elasticsearch-plugin install xxx.zip 进行自动安装
https://github.com/medcl/elasticsearch-analysis-ik/releases
在前面安装的elasticsearch时,我们已经将elasticsearch容器的“/usr/share/elasticsearch/plugins”目录,映射到宿主机的“ /mydata/elasticsearch/plugins”目录下,所以比较方便的做法就是下载“/elasticsearch-analysis-ik-7.4.2.zip”文件,然后解压到该文件夹下即可。安装完毕后,需要重启elasticsearch容器。
如果不嫌麻烦,还可以采用如下的方式。