网站 关键词 出现频率志鸿优化网
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、实验介绍
本实验包含 645 名阿尔茨海默病受试者,分为 AD、CN 和 MCI 组,数据集包含 3D MRI 图像与一份CSV数据,MRI数据与CSV中的数据通过受试者ID进行关联。

- AD (Alzheimer’s Disease):指的是已经确诊的阿尔茨海默病,这是一种神经退行性疾病,通常表现为认知功能的显著下降,特别是记忆丧失、语言问题、以及其他认知能力的严重损害。AD 是痴呆最常见的原因。
- CN (Cognitively Normal):代表认知正常,指的是没有出现明显的认知障碍或记忆问题的人。这类人在认知测试中表现正常,不显示出认知功能的下降。
- MCI (Mild Cognitive Impairment):指的是轻度认知障碍,这是介于认知正常和痴呆之间的一个中间阶段。MCI 的患者虽然表现出一些认知功能的下降,特别是在记忆方面,但这些问题尚未严重到影响日常生活的程度。MCI 有可能发展为阿尔茨海默病,但并不是所有的 MCI 患者都会最终患上 AD。
二、实验环境
- 语言环境:python 3.8
- 编译器:Pycharm
- 深度学习环境:Pytorch
- 显卡:GeForce RTX 4090D
三、准备工作
1. 设置GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasetsimport os, PIL, pathlib, random
import pandas as pd
import nibabel as nib
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
import torch.utils.data as data
import numpy as np
import torch.nn.functional as F# 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2. 导入CSV数据
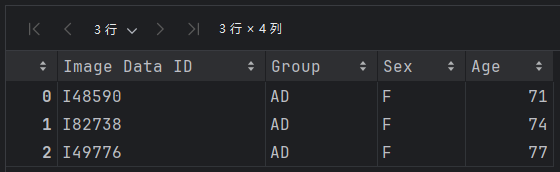
df = pd.read_csv("./K1data/ADNI_1p5T_Filtered.csv",usecols=["Image Data ID", "Group", "Sex", "Age"])
df.head(3)
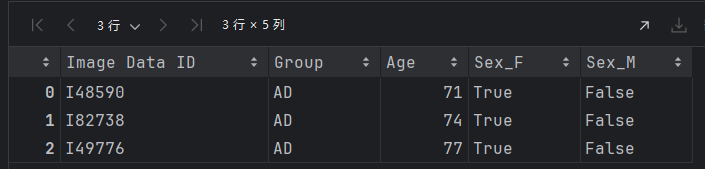
# 对sex列做one-hot编码
df = pd.get_dummies(df, columns=['Sex'])
df.head(3)
3. 导入mgz数据
labels = []
img_paths = []
strnums = []for index, row in df.iterrows():labels.append(row['Group'])# 合成文件路径img_path = "./K1data/" + row['Group'] + "/" + row['Image Data ID'] + ".nii_aseg_deep.mgz"img_paths.append(img_path)strnums.append([row['Age'], row['Sex_F'], row['Sex_M']])strnums[:3]

# 定义数据文件夹路径
data_path = r'./K1data/AD/I48590.nii_aseg_deep.mgz' # 替换为AD文件夹的实际路径img_data = nib.load(data_path).get_fdata()# 将 NumPy 数组转换为 PyTorch 张量
img_tensor = torch.tensor(img_data, dtype=torch.float32)
img_tensor.shape

4. 数据可视化
# 加载 .mgz 文件
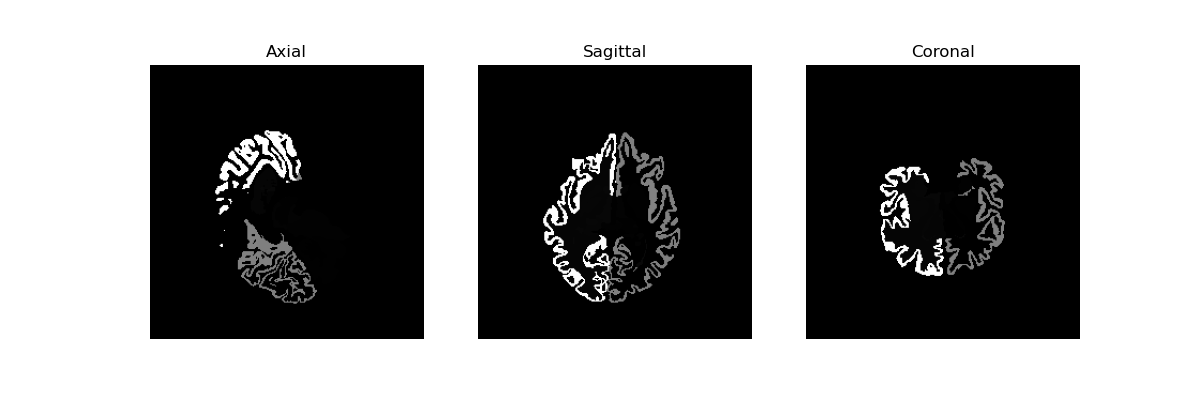
def load_mgz_file(file_path):return nib.load(file_path).get_fdata()# 可视化三个方向的切片
def visualize_slices(img_data):# 选择每个方向的中间切片slice_axial = img_data[img_data.shape[0] // 2, :, :]slice_sagittal = img_data[:, img_data.shape[1] // 2, :]slice_coronal = img_data[:, :, img_data.shape[2] // 2]# 创建子图并显示fig, axes = plt.subplots(1, 3, figsize=(12, 4))axes[0].imshow(slice_axial.T, cmap='gray', origin='lower')axes[0].set_title('Axial')axes[1].imshow(slice_sagittal.T, cmap='gray', origin='lower')axes[1].set_title('Sagittal')axes[2].imshow(slice_coronal.T, cmap='gray', origin='lower')axes[2].set_title('Coronal')# 隐藏坐标轴for ax in axes:ax.axis('off')plt.show()# 示例:加载并显示 MRI 数据
file_path = './K1data/AD/I31143.nii_aseg_deep.mgz' # 替换为实际文件路径
img_data = load_mgz_file(file_path)
visualize_slices(img_data) # 轴向切片
四、数据预处理
1. 构建数据集
class MyDataset(Dataset):def __init__(self, all_labels, img_paths, strnums, transform):self.img_labels = all_labels # 获取标签信息self.img_dir = img_paths # 图像目录路径self.strnums = strnums # 获取数值信息self.transform = transform # 目标转换函数def __len__(self):return len(self.img_labels)def __getitem__(self, index):image = nib.load(self.img_dir[index]).get_fdata()if self.img_labels[index] == "CN":label = torch.tensor(0, dtype=torch.long)elif self.img_labels[index] == "MCI":label = torch.tensor(1, dtype=torch.long)else:label = torch.tensor(2, dtype=torch.long)strnum = torch.tensor(self.strnums[index], dtype=torch.float32)if self.transform:image = self.transform(image)return image, strnum, label # 返回图像和标签
2. 数据预处理
def interpolate_volume(vol, size, mode='trilinear', align_corners=True):vol = torch.tensor(vol, dtype=torch.float32)vol = vol.unsqueeze(0).unsqueeze(0) # 扩展为 (1, 1, D, H, W) 的形状vol_resized = F.interpolate(vol, size=size,mode=mode, align_corners=align_corners)return vol_resized.squeeze(0).squeeze(0) # 去掉多余的维度,返回 (D_target, H_target, W_target)class ToTensor3D:"""将 3D numpy.ndarray 转换为 PyTorch Tensor,并调整维度顺序为 (C, D, H, W)。"""def __call__(self, img):# 确保输入为 numpy.ndarrayif isinstance(img, np.ndarray):img = torch.from_numpy(img).float()# 调整维度顺序为 (C, D, H, W),这里我们假设只有一个通道return img.unsqueeze(0) # 添加通道维度class Normalize3D:"""对 3D 图像进行标准化处理。"""def __init__(self, mean, std):self.mean = torch.tensor(mean).view(-1, 1, 1, 1) # 调整维度匹配self.std = torch.tensor(std).view(-1, 1, 1, 1)def __call__(self, tensor):return (tensor - self.mean) / self.stddef train_transforms(img):"""3D 图像的训练数据转换。Args:img (numpy.ndarray): 输入 3D 图像,形状为 (D, H, W)。Returns:torch.Tensor: 转换后的图像张量,形状为 (C, D, H, W)。"""img = np.array(img)img = interpolate_volume(img, size=224).numpy()tensor = torch.tensor(img, dtype=torch.float32)# Step 3: 标准化处理# 计算适合医学图像的均值和标准差mean = tensor.mean()std = tensor.std()normalized_tensor = Normalize3D(mean=[mean], std=[std])(tensor)return normalized_tensor# 实例化数据集
total_data = MyDataset(labels, img_paths, strnums, transform=train_transforms)
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data,[train_size, test_size])
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=4,shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=4,shuffle=True)print("The number of images in a training set is: ", len(train_loader) * 4)
print("The number of images in a test set is: ", len(test_loader) * 4)
print("The number of batches per epoch is: ", len(train_loader))

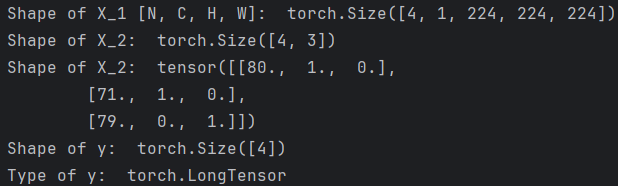
for X_1, X_2, y in test_loader:print("Shape of X_1 [N, C, H, W]: ", X_1.shape)print("Shape of X_2: ", X_2.shape)print("Shape of X_2: ", X_2[:3])print("Shape of y: ", y.shape)print("Type of y: ", y.type())break
五、模型定义
1. 定义CNN模型
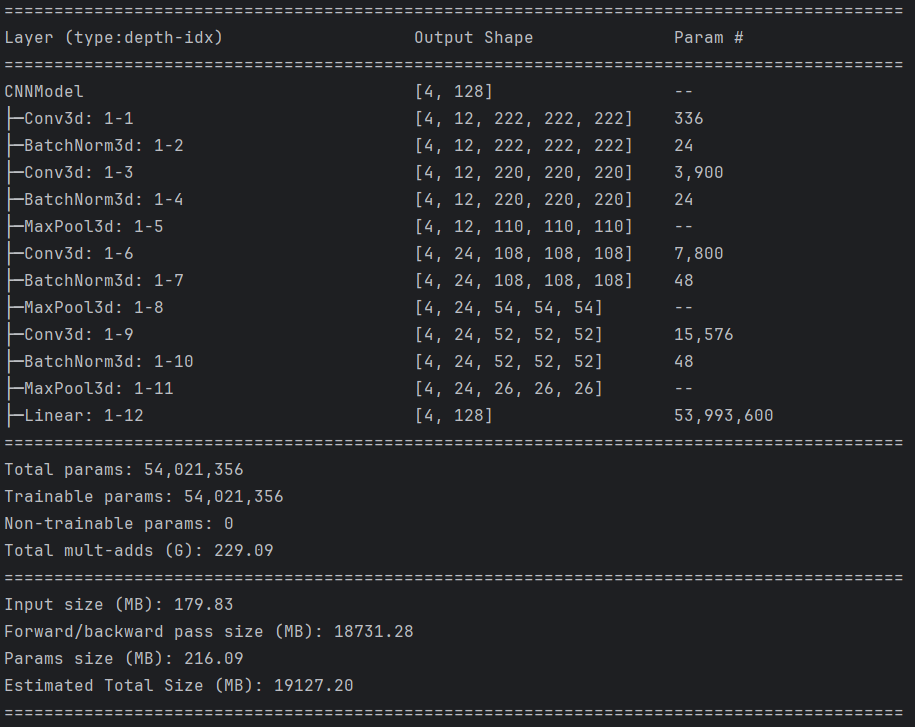
class CNNModel(nn.Module):def __init__(self):super(CNNModel, self).__init__()self.conv1 = nn.Conv3d(in_channels=1, out_channels=12, kernel_size=3, stride=1, padding=0)self.bn1 = nn.BatchNorm3d(12)self.conv2 = nn.Conv3d(in_channels=12, out_channels=12, kernel_size=3, stride=1, padding=0)self.bn2 = nn.BatchNorm3d(12)self.pool1 = nn.MaxPool3d(2, 2)self.conv4 = nn.Conv3d(in_channels=12, out_channels=24, kernel_size=3, stride=1, padding=0)self.bn4 = nn.BatchNorm3d(24)self.pool2 = nn.MaxPool3d(2, 2)self.conv5 = nn.Conv3d(in_channels=24, out_channels=24, kernel_size=3, stride=1, padding=0)self.bn5 = nn.BatchNorm3d(24)self.pool3 = nn.MaxPool3d(2, 2)self.fc1 = nn.Linear(24 * 26 * 26 * 26, 128)def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = self.pool1(x)x = F.relu(self.bn4(self.conv4(x)))x = self.pool2(x)x = F.relu(self.bn5(self.conv5(x)))x = self.pool3(x)# print(x.shape)x = x.view(-1, 24 * 26 * 26 * 26)x = self.fc1(x)return xmodel = CNNModel().to(device)from torchinfo import summarysummary(model, (4, 1, 224, 224, 224))
2. 定义融合模型
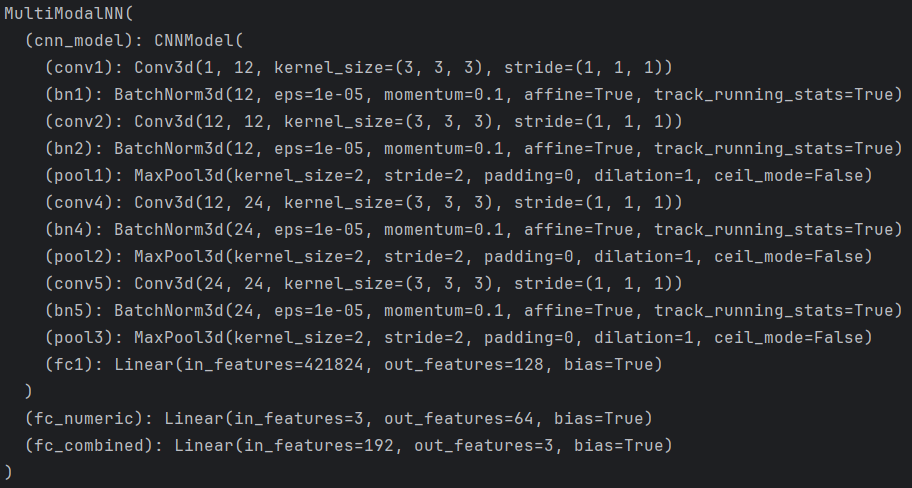
class MultiModalNN(nn.Module):def __init__(self):super(MultiModalNN, self).__init__()self.cnn_model = CNNModel() # 图像 CNNself.fc_numeric = nn.Linear(3, 64) # 假设数值型数据有 3 个特征self.fc_combined = nn.Linear(128 + 64, 3) # 最终分类或回归层def forward(self, mri_data, numeric_data):# 处理 MRI 数据img_features = self.cnn_model(mri_data)# 处理数值型数据num_features = F.relu(self.fc_numeric(numeric_data))# print(img_features.shape, num_features.shape)# 合并两种特征combined = torch.cat((img_features, num_features), dim=1)# 输出分类或回归结果output = self.fc_combined(combined)return output# 创建多模态模型
multi_modal_model = MultiModalNN().to(device)print(multi_modal_model)
3. 定义训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,num_batches = len(dataloader) # 批次数目,train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X_1, X_2, y in dataloader: # 获取图片及其标签X_1, X_2, y = X_1.to(device), X_2.to(device), y.to(device)# 计算预测误差pred = model(X_1, X_2) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
4. 定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for X_1, X_2, y in dataloader:X_1, X_2, y = X_1.to(device), X_2.to(device), y.to(device)# 计算lossy_pred = model(X_1, X_2)loss = loss_fn(y_pred, y)test_loss += loss.item()test_acc += (y_pred.argmax(1) == y).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
六、训练模型
1. 设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-3 # 学习率
opt = torch.optim.Adam(multi_modal_model.parameters(), lr=learn_rate)
2. 训练模型
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):multi_modal_model.train()epoch_train_acc, epoch_train_loss = train(train_loader, multi_modal_model, loss_fn, opt)multi_modal_model.eval()epoch_test_acc, epoch_test_loss = test(test_loader, multi_modal_model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
👉 代码输出:
Epoch: 1, Train_acc:34.1%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 2, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 3, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 4, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 5, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 6, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 7, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 8, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch: 9, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Epoch:10, Train_acc:31.2%, Train_loss:nan, Test_acc:27.1%, Test_loss:nan
Done
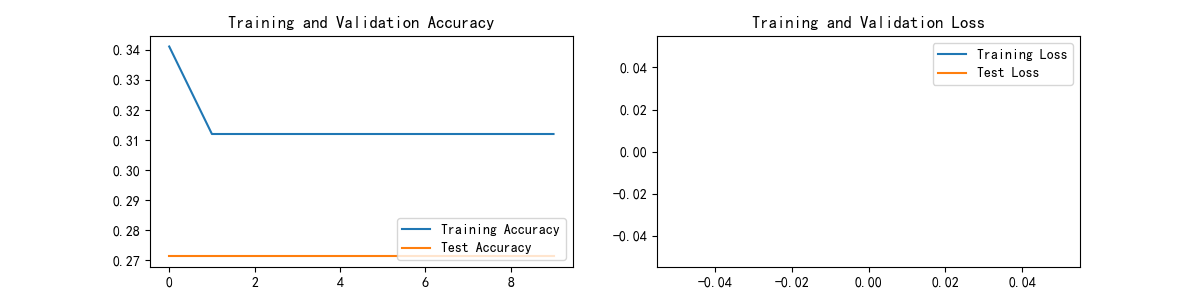
3. 结果分析
-
准确率(Accuracy):
- 训练集和验证集的准确率都非常低且基本保持不变。
- 这表明模型可能没有很好地学习到数据中的模式。
-
损失(Loss):
- 训练损失和测试损失均为
nan(Not a Number),说明在计算损失时出现了数值不稳定的情况。
- 训练损失和测试损失均为
4. 可能的原因及解决方案
- 损失为
nan:通常是由于梯度爆炸或反向传播过程中出现了无效的数值操作(如除以零、对数运算等)。
- 解决方案:
- 检查输入数据:确保所有输入数据都是有效的,并且没有异常值。
- 初始化权重:适当的权重初始化可以避免梯度消失/爆炸问题。
- 使用梯度裁剪:限制梯度的最大范数,防止梯度爆炸。
- 调整学习率:过高的学习率可能导致梯度爆炸。尝试减小学习率。
- 数据标准化:确保输入数据经过适当的标准化处理。
- 准确率较低且不变:模型可能过于简单无法捕捉数据中的复杂模式,或者存在过拟合的风险。
- 解决方案:
- 增加模型复杂度:适当增加卷积层的数量或每层的输出通道数。
- 正则化:添加 Dropout 层或其他正则化技术来减少过拟合。
- 数据增强:通过数据增强技术提高模型的泛化能力。
import matplotlib.pyplot as plt
# 隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
七、总结
本实验是基于多模态数据(MRI图像和数值特征)的AD检测模型,在运行原代码的过程中碰到较多问题。第一个是出现“RuntimeError: mat1 and mat2 must have the same dtype, but got Long and Float”的报错。
表示在进行矩阵乘法(如 torch.mm 或线性层)时,输入的数据类型不一致,一个是 Long 类型(整数类型),另一个是 Float 类型(浮点数)。这里主要是通过在多个步骤中添加了断言检查,随后出现第二个报错"AssertionError: X_2 must be float32"。
表明X_2 的数据类型不是 torch.float32,这是在训练数据的预处理或加载过程中出现的问题。随后返回检查数据类型时发现X_2 dtype: torch.int64,通过强制转换为folat32后问题似乎得到了解决,但更推荐的是在数据准备阶段处理以避免后续的问题:
# 确保 strnums 是 numpy.float32 类型
strnums = np.array(strnums, dtype=np.float32)
我的代码相比原代码主要是修改了三个地方:
class ToTensor3D:"""将 3D numpy.ndarray 转换为 PyTorch Tensor,并调整维度顺序为 (C, D, H, W)。"""def __call__(self, img):# 确保输入为 numpy.ndarrayif isinstance(img, np.ndarray):img = torch.from_numpy(img).float()# 调整维度顺序为 (C, D, H, W),这里我们假设只有一个通道return img.unsqueeze(0) # 添加通道维度
# 计算适合医学图像的均值和标准差
# 使用统计量对张量进行标准化
mean = tensor.mean()
std = tensor.std()
normalized_tensor = Normalize3D(mean=[mean], std=[std])(tensor)return normalized_tensor
class CNNModel(nn.Module):def __init__(self):super(CNNModel, self).__init__()self.conv1 = nn.Conv3d(in_channels=1, out_channels=12, kernel_size=3, stride=1, padding=0) # 输入通道数改为1self.bn1 = nn.BatchNorm3d(12)self.conv2 = nn.Conv3d(in_channels=12, out_channels=12, kernel_size=3, stride=1, padding=0)self.bn2 = nn.BatchNorm3d(12)self.pool1 = nn.MaxPool3d(2, 2)self.conv4 = nn.Conv3d(in_channels=12, out_channels=24, kernel_size=3, stride=1, padding=0)self.bn4 = nn.BatchNorm3d(24)self.pool2 = nn.MaxPool3d(2, 2)self.conv5 = nn.Conv3d(in_channels=24, out_channels=24, kernel_size=3, stride=1, padding=0)self.bn5 = nn.BatchNorm3d(24)self.pool3 = nn.MaxPool3d(2, 2)self.fc1 = nn.Linear(24 * 26 * 26 * 26, 128)
最终成功跑通模型,期间还因为别的软件开太多内存不够崩了一次,但是结果却并不理想。尝试了下列操作结果反而变差了,另外两处改进:全局标准化因为内存不足没法子,减小目标尺寸到64x64x64出现报错……
- 学习率调整:从1e-3 减小到 1e-4
- 梯度裁剪:在反向传播后添加梯度裁剪,防止梯度爆炸
- 权重初始化:使用 He 初始化 (kaiming_normal_) 和 Xavier 初始化 (xavier_uniform_) 来初始化卷积层和线性层的权重
Anyway,对菜鸡来说跑通就是胜利吧,实验到此告一段落,我得去修返回的文章了=.=
1. 主要深度学习方法
- 卷积神经网络 (CNN): 用于处理MRI图像数据。通过一系列的3D卷积层 (
nn.Conv3d)、批归一化层 (nn.BatchNorm3d) 和池化层 (nn.MaxPool3d) 来提取图像特征。- 全连接神经网络 (FCN): 用于处理数值型数据(年龄、性别等),并将其与CNN提取的图像特征进行融合,最终通过全连接层进行分类。
2. 多模态融合方式
- 特征级融合:
- 首先,使用CNN模型对MRI图像数据进行特征提取,得到图像特征向量
img_features。- 然后,使用一个全连接层
self.fc_numeric对数值型数据进行处理,得到数值特征向量num_features。- 最后,将这两个特征向量在维度1上进行拼接 (
torch.cat((img_features, num_features), dim=1)),并通过另一个全连接层self.fc_combined进行最终的分类。3. 难点及解决方案
- 数据处理和标准化:
- 难点: MRI图像数据通常具有不同的尺寸和强度范围,需要进行标准化处理。
- 解决方案: 使用
interpolate_volume函数将图像数据插值到统一大小,通过计算每个图像自身的均值和标准差进行标准化处理。- 模型设计和调参:
- 难点: 设计合适的CNN结构以及确定全连接层的参数,以有效地融合多模态数据并进行准确分类。
- 解决方案: 通过实验和调整卷积层、池化层以及全连接层的参数,同时使用交叉熵损失函数 (
nn.CrossEntropyLoss) 和Adam优化器 (torch.optim.Adam) 进行训练。4. 改进方向
- 数据增强: 对MRI图像进行更多的数据增强操作,如旋转、翻转、缩放等,以增加数据的多样性,提高模型的泛化能力。
- 模型优化:
- 尝试更深层次的CNN结构,如3D ResNet,以更好地提取图像特征。
- 调整全连接层的结构和参数,优化多模态特征融合的方式。
- 超参数调优: 使用更系统的超参数调优方法,如随机搜索、网格搜索或更高级的调优算法(如Optuna),找到最优的超参数组合。
- 集成学习: 将多个不同的多模态模型进行集成,以提高模型的稳定性和准确性。
- 使用预训练模型: 在大规模医学图像数据集上预训练的模型,迁移学习到该任务中,以加速收敛并提高性能。