做美女图片网站合法吗怎么在百度上发布信息
统一码(Unicode),它也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
如果把各种文字编码形容为各地的方言,那么Unicode就是世界各国合作开发的一种语言。
在这种语言环境下,不会再有语言的编码冲突,在同屏下,可以显示任何语言的内容,这就是Unicode的最大好处。就是将世界上所有的文字用2个字节统一进行编码。那样,像这样统一编码,2个字节就已经足够容纳世界上所有的语言的大部分文字了。
Universal Multiple-Octet Coded Character Set,简称为UCS。
现在用的是UCS-2,即2个字节编码,而UCS-4是为了防止将来2个字节不够用才开发的。
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
编码方式
在Unicode中:汉字"字"对应的数字是23383。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是"UCS Transformation Format"的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。例如,"汉字"对应的数字是0x6c49和0x5b57,而编码的程序数据是:
BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8编码
WORD data_utf16[] = {0x6c49, 0x5b57}; // UTF-16编码
DWORD data_utf32[] = {0x6c49, 0x5b57}; // UTF-32编码
这里用BYTE、WORD、DWORD分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以BYTE、WORD、DWORD作为编码单位。"汉字"的UTF-8编码需要6个字节。"汉字"的UTF-16编码需要两个WORD,大小是4个字节。"汉字"的UTF-32编码需要两个DWORD,大小是8个字节。根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。
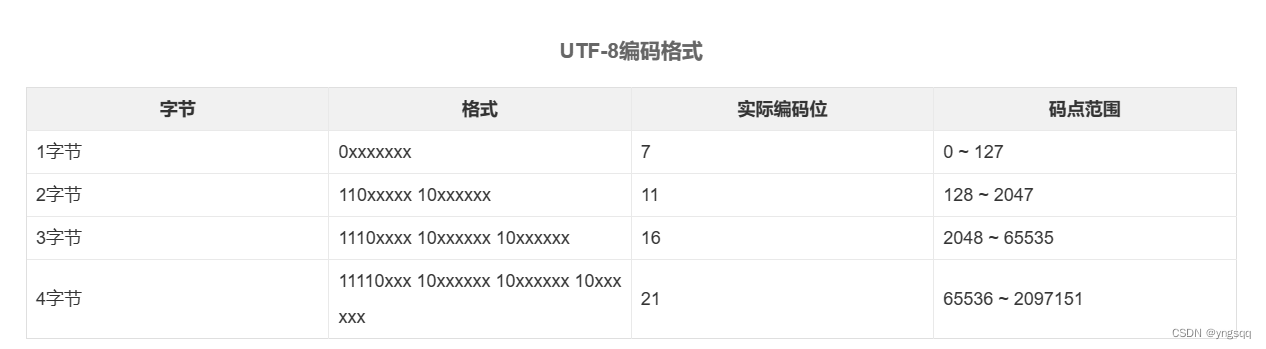
UTF-8
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
Unicode编码(十六进制)║UTF-8字节流(二进制)
F ║0xxxxxxxx║110xxxxx 10xxxxxx║1110xxxx 10xxxxxx 10xxx10xxxx║11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
 计算机只是处理数字。它们指定一个数字,来储存字母或其他字符。在创造Unicode之前,有数百种指定这些数字的编码系统。没有一个编码可以包含足够的字符:例如,单单欧州共同体就需要好几种不同的编码来包括所有的语言。即使是单一种语言,例如英语,也没有哪一个编码可以适用于所有的字母,标点符号,和常用的技术符号。这些编码系统也会互相冲突。也就是说,两种编码可能使用相同的数字代表两个不同的字符,或使用不同的数字代表相同的字符。任何一台特定的计算机(特别是服务器)都需要支持许多不同的编码,但是,不论什么时候数据通过不同的编码或平台之间,那些数据总会有损坏的危险。
计算机只是处理数字。它们指定一个数字,来储存字母或其他字符。在创造Unicode之前,有数百种指定这些数字的编码系统。没有一个编码可以包含足够的字符:例如,单单欧州共同体就需要好几种不同的编码来包括所有的语言。即使是单一种语言,例如英语,也没有哪一个编码可以适用于所有的字母,标点符号,和常用的技术符号。这些编码系统也会互相冲突。也就是说,两种编码可能使用相同的数字代表两个不同的字符,或使用不同的数字代表相同的字符。任何一台特定的计算机(特别是服务器)都需要支持许多不同的编码,但是,不论什么时候数据通过不同的编码或平台之间,那些数据总会有损坏的危险。
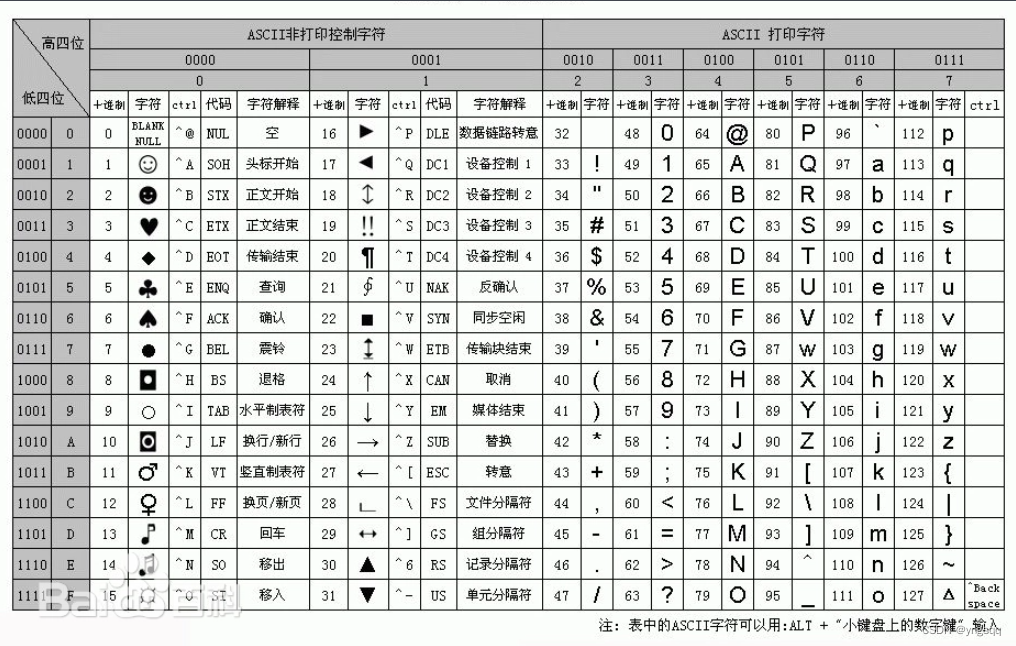
ASCII码
大多数计算机采用ASCII码(美国标准信息交换码),它是表示所有大小写字母、数字、标点符号和控制字符的7位编码方案。统一码(Unicode)包含ASCII码,'\\u0000'到'\\u007F'对应全部128个ACSII字符,0-127共128个编码。在JAVA中可以使用统一码。

unicode字符表:
ANSI和UTF-8的区别
ANSI 和 UTF-8 是两种不同的编码方式,它们的主要区别在于字符的编码方式和所支持的语言范围。
ANSI(American National Standards Institute)是一种美国的行业标准,用于在不同国家和地区的操作系统中表示字符。ANSI 使用单一字节(8位)来编码字符,这导致了一些问题,因为它只能表示有限的字符集,并且不同版本的 ANSI 编码之间不兼容。例如,在简体中文 Windows 操作系统中,ANSI 编码可能对应于 GBK 编码;而在日文中,它可能与 Shift_JIS 编码相关联。因此,当需要在不同系统和平台上共享文本时,ANSI 编码可能会遇到困难,因为不是所有平台都能正确解析所有 ANSI 编码的文本内容。1
UTF-8(Unicode Transformation Format)是一种广泛使用的多字节编码方案,它可以表示世界上几乎所有语言和符号。UTF-8 通过使用 1 到 4 个字节来编码每一个字符,从而能够表达更丰富的字符集。与 ANSI 编码相比,UTF-8 具有更好的通用性和扩展性,能够在多种系统和平台上正确地表示文本。12
总结一下,ANSI 主要是一个美国标准的单字节编码,而 UTF-8 是一个通用的多字节编码,适合跨文化和跨平台的文本传输。