门户网站开发投标文件.doc微信搜一搜怎么做推广
非书中全部内容,只是写了些自认为有收获的部分。
自然语言处理简介
NLP的难点
(1)语言有很多复杂的情况,比如歧义、省略、指代、重复、更正、倒序、反语等
(2)歧义至少有如下几种:
1.有些歧义是指代不明确带来的。比如“曾记否,我与你认识的时候,还是个十来岁的少年,纯真无瑕,充满幻想。"其中十来岁的少年指代不明,有可能指你,也有可能指我。
2.有些歧义是机器断句困难导致组合层次不同带来的。比如“我们四个人一”可以理解为“我们/四个人一组”或“我们四个人/一组”,“这件事我办不好”可以理解为“这件事/我/办不好”或“这件事/我办/不好”。
3.有些歧义是结构关系不同导致的。比如“学生家长”可以理解为“学生的家长”或"学生和家长”,"出口食品”可以理解为动宾关系,也可以理解为偏正关系。
4.有些歧义是词语语义多带来的。比如“他想起来了”可以理解为“他想起床了”或者“他想起来某件事情了”
5.词类不同也可以带来歧义。比如“我要炒饭”中的“炒”可以是动词,也可以是形容词.
6.很多新的品牌或网络用语也会带来歧义问题
NLP的研究范围
(1)分词:利用算法将一个汉字序列切分为一个个单独的词。比如将“手
爱机器学习”切分为“我/爱/机器学习“
(2)词性标注:将分词结果中的每个单词标注为名词、动词、形容词或其他词性的过程
(3)命名实体识别:识别文本串中具有特定物理意义的实体单词,比如人名、地名、机构名等
(4)关键词提取:提取文本串中若干个可以代表文章语义内容的词汇或词语
(5)自动摘要:也称为摘要提取,即根据文本语义内容提取较短的语句
(6)主题模型:隐式的主题模型如Latent Semantic Analysis (LSA) 、Probabilistic Latent Semantic Analysis ( PLSA) 、 Latent Dirichlet Allocation (LDA) 等都是非常常见的研究领域。
(7)依存句法分析:分析语言成分之间的依存关系,并揭示其语法树
(8)词嵌入 (Word Embedding) :将词采用向量表示。词嵌入从2013年左右开始就一直比较流行,可以说,词嵌入本身不是深度学习,但词嵌入是深度学习用于自然语言处理的基本前提
(9)机器翻译:利用计算机将一种自然语言转换成另一种自然语言的过程,两种自然语言分别称为源语言和目标语言
词性标注
传统词性标注模型
(1)传统的词性标注方法有隐马尔可夫模型(HMM)和最大马尔可夫模型(MEMM)等。其中,HMM是生成模型,MEMM是判别模型
(2)基于MEMM的词性标注器抽取当前待标注单词附近的特征,然后利用这些特征判别当前单词的词性。MEMM是最大熵模型(ME) 在处理序列模型方面的变种。其思想是在一串满足约束的标签中选出一个熵最大的标签
(3)当前单词的上下文信息又叫作特征。根据在语料中出现的频次,可以将单词分为常见词和罕见词。常见词周围的特征包括:待标注的单词、待标注单词附近的单词、待标注单词附近已标注单词的词性标签等;罕见词的特征包括:单词的后缀、单词的前缀、单词是否包合数字、单词是否首字母大写等
(4)HMM和MEMM存在同一个问题,就是只能从一个方向预测接下来的标注。一种解决方法是用例如CRF这样的强大模型,但是CRF的计算开销太大,并且对标注效果的提升有限
基于神经网络的词性标注模型
(1)模型从左向右依次标注句子中的单词,对于当前单词,抽取周用一定窗口大小内的特征,然后将其作为特征向量送入前馈神经网络分类器
(2)整个神经网络分为多层。第一层把每个单词映射到一个特征向量,得到单词级别的特征,第二层利用滑动窗口得到单词上下文的特征向量,不像传统的词袋方法,这个方法保留了窗口内单词的顺序关系。同时也可以加入其他特征,如单词是否首字母大写、单词的词干等
(3)在计算上下文特征时只考虑当前单词附近窗口大小为k范围内的单词,这种方法叫作窗口方法
(4)将整个句子的单词特征向量送入后续网络中,这种方法叫作句子方法
(5)对于词性标注来说,句子方法并不能带来明显的效果提升,但是对于自然语言里的某些任务,如语义角色标注(SRL),句子方法带来的效果提升会比较明显
(6)因为句子长度一般是不定的,所以在使用句子方法的神经网络模型中会增加卷积层
(7)用无监督训练得到的词向量初始化词性标注模型的词向量,能明显提升词性标注的准确率
基于Bi-LSTM的神经网络词性标注
(1)普通的词向量结合大量语料可以学习到单词间语义和语法上的相似性。举个例子,模型可以学到cats、kings、queens之间的线性相关性与cat、king、queen之间的线性相关性一样。不过模型并不能学到前面这组单词是由后面这组单词在末尾加s得到的
(2)普通的词向量模型查找表过于庞大,于是就有人提出将单词拆成更小的单元。基于字符的词向量模型的输入、输出和普通的词向量模型是一样的,因此在神经网络模型中这两种模型可以相互替换。与普通的词向量模型类似,基于字符的词向量模型是给字符集合建立一个查找表。字符集合包括大小写字母、数字、标点等,每个字符都可以在查找表中找到对应的字符向量,每个单词都可以看成一串字符,将单词中的字符对应的向量从左到右依次送入LSTM模型,再以右向左依次送入LSTM模型。两个方向的LSTM模型生成的结果组合生成当前单词的词向量,这样就可以利用Bi-LSTM模型得到单词的向量表示。整个过程如图19-3所示

(3)模型架构
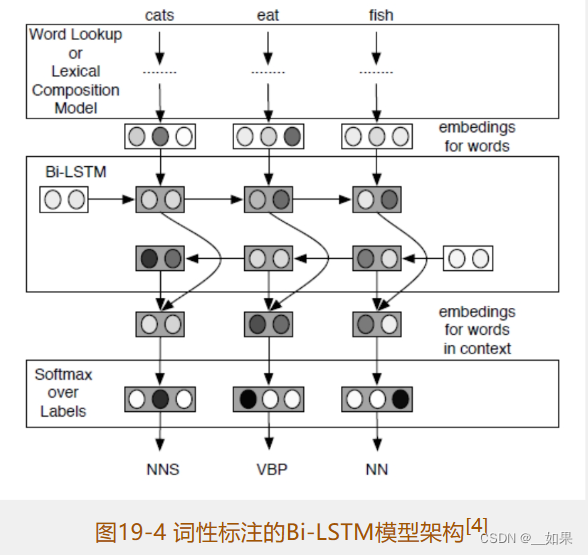
(4)相对于普通的词向量模型,基于字符的词向量模型减少了很多参数。不过,因为英文中单词构成的复杂性,该模型在词性标注上的表现并没有超越现有模型
(5)虽然基于字符的词向量模型可以学习ed,ily这种形变特征,但是英文中有些字符构成很像的单词之间的差异却很大,比如lesson和lessen,虽然以字符角度看起来很像,但是它们的含义却完全不同
依存句法分析
未完待续...