湖北企业网站建设公司宁波seo企业网络推广
1 小工具说明
1.1 功能说明
一般来说,我们会先有一个老的文件,这个文件内容是定制好相关列的表格,作为每天的报告。
当下一天来的时候,需要根据新的报表文件和昨天的报表文件做一个合并,合并的时候就会出现有些事新增条目、有些是可能要删除的条目、有些是要更新状态的条目。
当前使用python编写的练习就是达到这个简单目的。
1.2 配置文件
配置文件内容样例:
yesterday=F:\projects\daily_merge_tool\test_files\scene1_no_diff\yesterday.xlsx
today=F:\projects\daily_merge_tool\test_files\scene1_no_diff\today.xlsx
report=F:\projects\daily_merge_tool\test_files\scene1_no_diff\report.csv
yesterday_primary_key_column=D
yesterday_status_column=E
today_primary_key_column=F
today_status_column=E
today_mapping_yesterday=C:B,D:C,F:D,E:E,H:F,I:G,J:H,K:I,L:J,M:K
yesterday的值为昨天的报表文件绝对路径
today的值为今天从其他系统新导出来的报表文件的绝对路径
report的值为存放合并当天最新报表的csv文件的绝对路径
yesterday_primary_key_column的值为昨天的报表文件中能够唯一代表一行数据的属性所在的列,例如:如果值是字母A是excel表格的第一列
yesterday_status_column的值为昨天的报表文件中当前行数据的状态列,例如:如果值是字母A是excel表格的第一列
today_primary_key_column值为今天的报表文件中能够唯一代表一行数据的属性所在的列,例如:如果值是字母A是excel表格的第一列
today_status_column的值为今天的报表文件中当前行数据的状态列,例如:如果值是字母A是excel表格的第一列
today_mapping_yesterday的值为昨天报表文件中各个列的数据来源映射到今天新导出的报表文件中的列
1.3 几个文件的样例
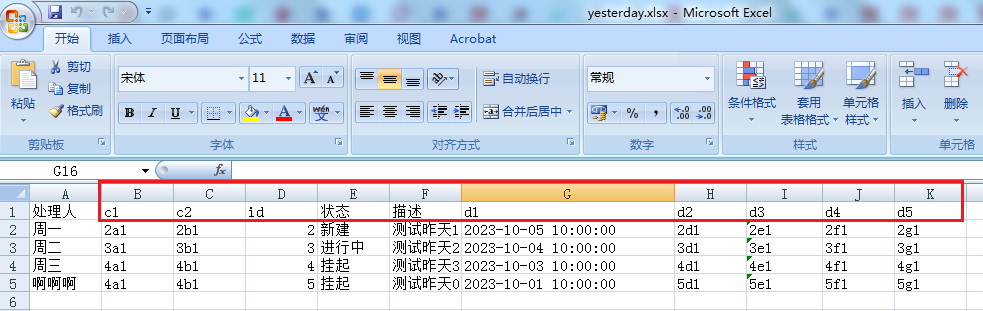
yesterday.xlsx
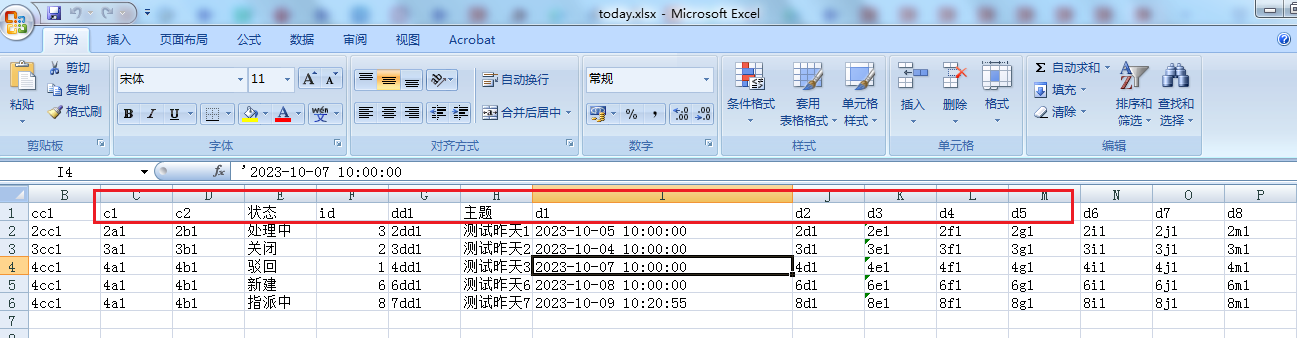
today.xlsx
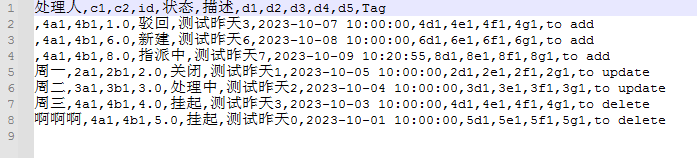
生成的report.csv,相比yesterday.xlsx,增加了1列Tag,标示当前行是新加还是修改了状态还是确认是否要删除
2 工具代码
https://download.csdn.net/download/WolfOfSiberian/88399882
import sys
import datetime
import xlrddef read_excel(excel_file_path):print("read excel: " + str(excel_file_path))readfile = xlrd.open_workbook(excel_file_path)names = readfile.sheet_names()obj_sheet = readfile.sheet_by_name(names[0])row = obj_sheet.nrows# col = obj_sheet.ncolsresult = [0 for i in range(row)]for i in range(row):result[i] = obj_sheet.row_values(i)return resultdef get_id_list(filepath, primary_key_column):print(str(datetime.datetime.now()) + " method get_id_list() invoked.")file_arrary = read_excel(filepath)data_row_num = len(file_arrary)id_list = []for i in range(1, data_row_num):id_list.append(file_arrary[i][ord(primary_key_column) - ord('A')])print(str(datetime.datetime.now()) + "file: " + filepath + ", id list:" + str(id_list))return id_listdef get_operation_list(yesterday_filepath, today_filepath,yesterday_primary_key_column,today_primary_key_column):yesterday_id_list = get_id_list(yesterday_filepath, yesterday_primary_key_column)today_id_list = get_id_list(today_filepath, today_primary_key_column)to_add = []to_del = []to_update = []operationList = [yesterday_id_list, today_id_list, to_add, to_del, to_update]for i in range(len(yesterday_id_list)):is_exist_in_today = 0curr_yesterday_id = yesterday_id_list[i]for j in range(len(today_id_list)):if curr_yesterday_id == today_id_list[j]:if curr_yesterday_id not in to_update:to_update.append(curr_yesterday_id)is_exist_in_today = 1breakif is_exist_in_today == 0:if curr_yesterday_id not in to_del:to_del.append(curr_yesterday_id)is_exist_in_today = 0 #reset statusfor i in range(len(today_id_list)):curr_today_id = today_id_list[i]if curr_today_id not in yesterday_id_list:if curr_today_id not in to_add:to_add.append(curr_today_id)print("operationList: \nyesterday_id_list," + str(operationList[0])+ ",\ntoday_id_list" + str(operationList[1])+ ",\nto_add" + str(operationList[2]) + ",\nto_del" + str(operationList[3]) + ",\nto_update" + str(operationList[4]))return operationListdef get_status_by_id(id, primary_key_column, status_column, total_result):for i in range(1, len(total_result)):if id == total_result[i][ord(primary_key_column) - ord('A')]:return total_result[i][ord(status_column) - ord('A')]return "N/A"def read_configurations(configuration_filepath):#configuration.txt内容例子# yesterday=F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\yesterday.xlsx# today=F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\today.xlsx# report=F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\report.csv# yesterday_primary_key_column=D# yesterday_status_column=E# today_primary_key_column=F# today_status_column=E# today_mapping_yesterday=C:B,D:C,F:D,E:E,H:F,I:G,J:H,K:I,L:J,M:Kprint("configuration filepath:" + configuration_filepath)configuration_file = open(configuration_filepath, mode='r')lines = configuration_file.readlines()configurations = {}for line in lines:entry = line.strip().split("=")if "," in entry[1]:# today_mapping_yesterdaymapping_entry_array = entry[1].split(",")today_mapping_yesterday = {}for mapping_entry in mapping_entry_array:mapping_key_value = mapping_entry.split(":")today_mapping_yesterday[mapping_key_value[0]] = mapping_key_value[1]configurations[entry[0]] = today_mapping_yesterdayelse :configurations[entry[0]] = entry[1]return configurationsdef generate_today_report(configuration_filepath):yesterday = "F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\yesterday.xlsx"# today = "F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\today.xlsx"# report = "F:\\projects\\daily_merge\\test_files\\scene1_no_diff\\report.csv"# yesterday_primary_key_column = 'D'# yesterday_status_column = 'E'# today_primary_key_column = 'F'# today_status_column = 'E'# today_mapping_yesterday = {'C':'B',# 'D':'C',# 'F':'D',# 'E':'E',# 'H':'F',# 'I':'G',# 'J':'H',# 'K':'I',# 'L':'J',# 'M':'K'}configurations = read_configurations(configuration_filepath)today = configurations['today']report = configurations['report']yesterday_primary_key_column = configurations['yesterday_primary_key_column']yesterday_status_column = configurations['yesterday_status_column']today_primary_key_column = configurations['today_primary_key_column']today_status_column = configurations['today_status_column']today_mapping_yesterday = configurations['today_mapping_yesterday']yesterday_result = read_excel(yesterday)today_result = read_excel(today)operation_list = get_operation_list(yesterday, today, yesterday_primary_key_column, today_primary_key_column)try:report_file = open(report, mode='w')#write titlefor i in range(len(yesterday_result[0])):report_file.write(yesterday_result[0][i]) report_file.write(",")report_file.write("Tag")report_file.write("\n")#write contentfor i in range(1, len(today_result)):id = operation_list[1][i - 1]if id in operation_list[2]:#add#extract for report according by column index mappingto_add_report_record = []for x in range(len(yesterday_result[0])):to_add_report_record.append("")for j in range(len(today_result[i])):current_today_column = chr(j + ord('A'))if current_today_column in today_mapping_yesterday:to_add_report_record[ord(today_mapping_yesterday[current_today_column]) - ord('A')] = today_result[i][j]#write to report for m in range(len(to_add_report_record)):report_file.write(str(to_add_report_record[m]))report_file.write(",")report_file.write("to add")report_file.write("\n")for i in range(1, len(yesterday_result)):id = operation_list[0][i - 1]if id in operation_list[3]:#deletefor j in range(len(yesterday_result[i])):report_file.write(str(yesterday_result[i][j]))report_file.write(",")report_file.write("to delete")else :#updatefor j in range(len(yesterday_result[i])):today_status = get_status_by_id(id, today_primary_key_column, today_status_column, today_result)if j == ord(yesterday_status_column) - ord('A'):report_file.write(today_status)else :report_file.write(str(yesterday_result[i][j]))report_file.write(",")report_file.write("to update")report_file.write("\n")except Exception as e:print("failed to generate report.")print(e)finally:report_file.close()print("generate report successfully.")return
print("==^^==^^==")
if len(sys.argv) <= 1:print("please input the configuration filepath when running this python file.")
else :generate_today_report(sys.argv[1])
print("==^^==^^==")
3 参考资料
解决python中XLRDError: Excel xlsx file; not supported
https://blog.csdn.net/qq_53464193/article/details/128407954
VSCode使用 - 搭建python运行调试环境
https://zhuanlan.zhihu.com/p/625844895?utm_id=0&wd=&eqid=b12208f700185aeb000000036498f302
Python读取Excel文件
https://blog.csdn.net/weixin_49895216/article/details/127812149
python操作Excel读写–使用xlrd
https://blog.csdn.net/qq_36396104/article/details/77875703