深圳积分商城网站建设百度退推广费是真的吗
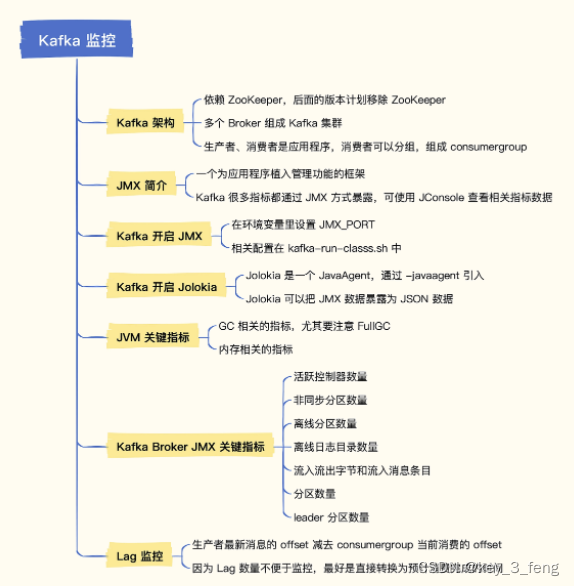
Kafka 架构

上面绿色部分 PRODUCER(生产者)和下面紫色部分 CONSUMER(消费者)是业务程序,通常由研发人员埋点解决监控问题,如果是 Java 客户端也会暴露 JMX 指标。组件运维监控层面着重关注蓝色部分的 BROKER(Kafka 节点)和红色部分的 ZOOKEEPER。
ZooKeeper 也是 Java 语言写的,监控相对简单,另外 ZooKeeper 支持 mntr 四字命令,可以获取 ZooKeeper 内部健康状况。新版 ZooKeeper 连四字命令都不需要了,直接内置暴露了 Prometheus 协议的 metrics 接口,直接抓取即可。
重点关注 Broker 节点的监控,也就是 Kafka 自身的监控,通常从四个方面着手。
- Kafka 进程所在机器的监控,重点关注 CPU、硬盘 I/O、网络 I/O。
- JVM 监控,Kafka 是个 Java 进程,所以需要常规的 JVM 监控,通过 JMX 方式暴露。
- Kafka 自身的指标、也是通过 JMX 方式暴露,比如消息数量、流量、分区、副本的数量等。
- 各个 consumer 的 lag 监控,即消息堆积量,是各类 MQ 都应该监控的指标。
JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架。Java 程序接入 JMX 框架之后,可以把一些类的属性和方法暴露出来,用户就可以使用 JMX 相关工具来读取或操作这些类。
Kafka 的配置文件在 config 目录,各种脚本在 bin 目录,要让 Kafka 开启 JMX,肯定是要修改某个配置项或者调整某个脚本的,具体调整哪里呢?我们在 Kafka 的部署目录搜索一下看看。
grep -i jmx -r config
grep -i jmx -r binJMX 数据分两类,一类是和 JVM 相关的,一类是和 Kafka 相关的。
ThreadCount 表示 JVM 里的线程数,类似的还有 DaemonThreadCount,表示后台线程数,PeakThreadCount 表示历史峰值线程数。JVM 要重点关注 GC 的情况和内存的情况。
GC 主要看次数和时间,分为 YongGC 和 FullGC,YongGC 很正常,频率也比较高,FullGC 正常情况下很少发生,如果经常发生,FullGC 程序的性能就会受影响。GC 次数的指标是 kafka_java_garbage_collector_CollectionCount,是一个 Counter 类型单调递增的值。GC 时间的指标是 kafka_java_garbage_collector_CollectionTime,也是一个 Counter 类型单调递增的值。
内存的指标是 kafka_java_memory_pool_Usage_used,单位是 byte。有个 name 标签标识了具体是哪个区域的内存大小,比如 Eden 区、Survivor 区、Old 区。
Kafka 指标
- 活跃控制器数量:MBean:broker kafka.controller:type=KafkaController,name=ActiveControllerCount。一个 Kafka 集群有多个 Broker,正常来讲其中一个 Broker 会是活跃控制器,且只能有一个。从整个集群角度来看,SUM 所有 Broker 的这个指标,结果应该为 1。如果
- 非同步分区数量:MBean:kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions。这个指标是对每个 Topic 的每个分区的统计,如果某个分区主从同步出现问题,对应的数值就会大于 0。
- 离线分区数量:MBean:kafka.controller:type=KafkaController,name=OfflinePartitionsCount。这个指标只有集群控制器才有,其他 Broker 这个指标的值是 0,表示集群里没有 leader 的分区数量。
- 离线日志目录数量:MBean:kafka.log:type=LogManager,name=OfflineLogDirectoryCount。Kafka 是把收到的消息存入 log 目录,如果 log 目录有问题,比如写满了,就会被置为 Offline,及时监控离线日志目录的数量显然非常有必要。
- 流入流出字节和流入消息:这是典型的吞吐指标,既有 Broker 粒度的,也有 Topic 粒度的,名字都一样,Topic 粒度的指标数据 MBean ObjectName 会多一个 topic=xx 的后缀。
- 流入字节:MBean:kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec。这个指标 Kafka 在使用 Yammer Metrics 埋点的时候,设置为了 Meter 类型,所以 Yammer 会自动计算出 Count、OneMinuteRate、FiveMinuteRate、FifteenMinuteRate、MeanRate 等指标,也就是 1 分钟、5 分钟、15 分钟内的平均流入速率,以及整体平均流入速率。
- 流出字节:MBean:kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec。和 BytesInPerSec 类似,表示出向流量。不过需要注意的是,流出字节除了普通消费者的消费流量,也包含了副本同步流量。
- 流入消息:MBean:kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSecBytesInPerSec 和 BytesOutPerSec 都是以 byte 为单位统计的,而 MessagesInPerSec 是以消息个数为单位统计的,也是 Meter 类型,相关属性都一样。
- 分区数量:MBean:kafka.server:type=ReplicaManager,name=PartitionCount这个指标表示某个 Broker 上面总共有多少个分区,包括 leader 分区和 follower 分区。如果多个 Broker 分区不均衡,可能会造成有些 Broker 消耗硬盘空间过快,这是需要注意的。
- leader 分区数量:MBean:kafka.server:type=ReplicaManager,name=LeaderCount这个指标表示某个 Broker 上面总共有多少个 leader 分区,leader 分区负责数据读写,承接流量,所以 leader 分区如果不均衡,会导致某些 Broker 过分繁忙而另一些 Broker 过分空闲,这种情况也是需要我们注意的。
此文章为8月Day8学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。