# Model grad buffer ranges.self.model_gbuf_ranges =[]for model_index, model inenumerate(self.models):self.model_gbuf_ranges.append(self.build_model_gbuf_range_map(model))
@classmethoddefbuild_model_gbuf_range_map(cls, model):"""Create param-to-grad-buffer mappings, for grad buffer data typeswithin a specific virtual model."""return{dtype : cls.build_model_gbuf_range(model, dtype)for dtype in model._grad_buffers}classRange:"""A range represents a start and end points for indexing a shardfrom a full tensor."""def__init__(self, start, end):self.start = startself.end = endself.size = end - startdefnormalize(self, start =0):return Range(start, start + self.size)def__str__(self):return"%d,%d [%d]"%(self.start, self.end, self.size)def__len__(self):return self.end - self.start
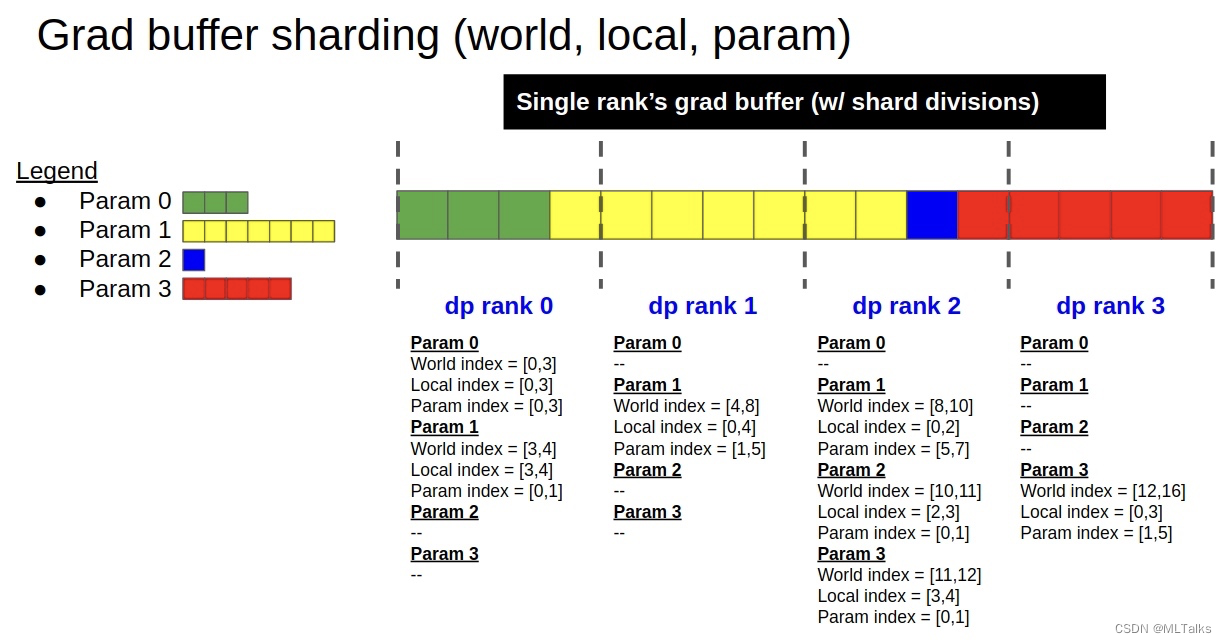
build_model_gbuf_range初始化range的流程如下:
获取DP的rank,计算单个Grad buffer切片的大小
保存当前rank的world range和local range, 分别对应world index和local index
计算param的range范围,对应param index
返回当前rank的相关range范围
@classmethoddefbuild_model_gbuf_range(cls, model, dtype):# 获取DP的rankdata_parallel_rank = mpu.get_data_parallel_rank()data_parallel_world_size = mpu.get_data_parallel_world_size()# 计算单个Grad buffer切片的大小grad_buffer = model._grad_buffers[dtype]gbuf_size = grad_buffer.numelmax_gbuf_range_size =int(math.ceil(gbuf_size / data_parallel_world_size))# 跟据DDP的rank总数,分别计算每个rank对应的全局rangegbuf_world_all_ranges =[]for r inrange(data_parallel_world_size):gbuf_world_start = r * max_gbuf_range_sizegbuf_world_end =min(gbuf_size, gbuf_world_start+max_gbuf_range_size)gbuf_world_range = Range(gbuf_world_start, gbuf_world_end)gbuf_world_all_ranges.append(gbuf_world_range)# 保存当前rank的world range和local range# Local DP's ranges.gbuf_world_range = gbuf_world_all_ranges[data_parallel_rank]gbuf_local_range = gbuf_world_range.normalize()# 计算param的range范围param_range_map = cls.build_model_gbuf_param_range_map(model,dtype,gbuf_world_range)# Group into dict.data ={"local": gbuf_local_range,"world": gbuf_world_range,"world_all": gbuf_world_all_ranges,"param_map": param_range_map,"max_range_size": max_gbuf_range_size,}return data
classDistributedOptimizer(MixedPrecisionOptimizer):def__init__(...):...self.model_param_gbuf_map = \self.build_model_param_gbuf_map(self.model_gbuf_ranges)...defbuild_model_param_gbuf_map(cls, model_gbuf_ranges):"""Create a reverse of the model_gbuf_ranges, for referencing inopposite direction."""param_gbuf_map ={}for model_index, model_gbuf_range_map inenumerate(model_gbuf_ranges):for dtype, gbuf_range_map in model_gbuf_range_map.items():for param, param_range_map in gbuf_range_map["param_map"].items():param_gbuf_map[param]=(model_index, dtype)return param_gbuf_map
在self.build_model_param_gbuf_map之后是初始化Optimizer对应的local group range,Optimizer原本有param_groups包括多个参数组,这里build_optimizer_group_ranges为了创建param参数到group_index的map映射,也就是<model_parameter:group_index>;self.build_model_param_gbuf_map最后对每个group_range中增加新的orig_group和orig_group_idx两个key,原来group_range初始化的时候只有params一个key
classDistributedOptimizer(MixedPrecisionOptimizer):def__init__(...):...# Optimizer ranges.self.model_param_group_index_map, self.opt_group_ranges = \self.build_optimizer_group_ranges(self.optimizer.param_groups,self.model_gbuf_ranges)...defbuild_optimizer_group_ranges(cls, param_groups, model_gbuf_ranges):# 获取param_groups中组的个数num_groups =len(param_groups)# 创建全局的参数到group_index的map映射,也就是<model_parameter:group_index>world_param_group_map ={}for group_index, group inenumerate(param_groups):for param in group["params"]:assert param.requires_gradworld_param_group_map[param]= group_index# 创建当前rank的local_param_group_map, local_param_group_map是param与(group_index, group_params_len)的映射, local_param_group_map虽然返回了但后面没用local_param_group_map ={}group_ranges =[{"params":[]}for _ in param_groups ]for model_gbuf_range_map in model_gbuf_ranges:for dtype, gbuf_range_map in model_gbuf_range_map.items():for param in gbuf_range_map["param_map"]:group_index = world_param_group_map[param]group_range = group_ranges[group_index]group_range["params"].append(param)local_param_group_map[param]= \(group_index,len(group_range["params"])-1)# Squeeze zero-size group ranges.for group_index, group_range inenumerate(group_ranges):group_range["orig_group"]= param_groups[group_index]group_range["orig_group_idx"]= param_groups[group_index]return local_param_group_map, group_ranges