做网站需要多少钱西安网络营销的优势
大家好,如果你对数据科学感兴趣,那么数据清洗可能对你来说是一个熟悉的术语,本文将向你介绍使用Pandas进行数据清洗的过程。我们的数据通常来自多个资源,而且并不干净,它可能包含缺失值、重复值、错误或不需要的格式等,在这种混乱的数据上运行实验会导致错误的结果。因此,在将数据输入模型之前,有必要对数据进行准备,这种通过识别和解决潜在的错误、不准确性和不一致性来准备数据的做法被称为数据清洗。
本文将使用著名的鸢尾花数据集进行操作。鸢尾花数据集包含三个品种的鸢尾花的四个特征测量值:萼片长度、萼片宽度、花瓣长度和花瓣宽度。本文将使用以下库:
-
Pandas:用于数据处理和分析的强大库
-
Scikit-learn:提供数据预处理和机器学习的工具
1. 加载数据集
使用Pandas的read_csv()函数加载鸢尾花数据集:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)
iris_data.head()
输出:
| id | sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
参数header=0表示CSV文件的第一行包含列名(标题)。
2. 探索数据集
为了深入了解数据集的基本信息,本文将使用pandas的内置函数打印一些基本信息:
print(iris_data.info())
print(iris_data.describe())
输出:
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):# 列名 非空计数 类型
--- ------ -------------- ----- 0 id 150 non-null int64 1 sepal_length 150 non-null float642 sepal_width 150 non-null float643 petal_length 150 non-null float644 petal_width 150 non-null float645 species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
None
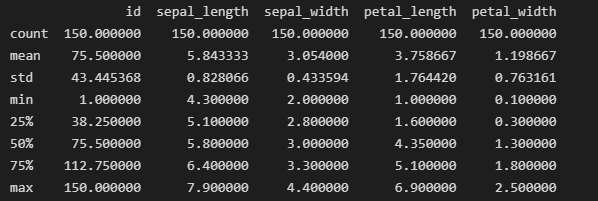
iris_data.describe()的输出结果
info()函数有助于了解数据帧的整体结构、每列中非空值的数量以及内存使用情况,而汇总统计信息则提供了数据集中数值特征的概览。
3. 检查类别分布
这是了解分类列中类别分布情况的重要步骤,对于分类任务来说非常重要,可以使用Pandas中的value_counts()函数来执行此步骤。
print(iris_data['species'].value_counts())
输出:
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: species, dtype: int64
输出的结果显示,数据集是平衡的,每个品种的代表数量相等,这为所有3个类别进行公平评估和比较奠定了基础。
4. 删除缺失值
由于从info()方法明显可见本文的数据中有5列没有缺失值,因此本文将跳过此步骤。但如果遇到任何缺失值,可以使用以下命令处理它们:
iris_data.dropna(inplace=True)
5. 删除重复值
重复值可能会扭曲我们的分析结果,因此本文会从数据集中删除它们。首先使用下面的命令检查是否存在重复值:
duplicate_rows = iris_data.duplicated()
print("Number of duplicate rows:", duplicate_rows.sum())
输出:
Number of duplicate rows: 0
本文的数据集中没有重复值。不过,如果有重复值,可以使用drop_duplicates()函数将其删除:
iris_data.drop_duplicates(inplace=True)
6. 独热编码
对于分类分析,本文将对品种列进行独热编码。由于机器学习算法更适合处理数值数据,所以本文进行独热编码这一步骤。独热编码过程将分类变量转换为二进制(0或1)格式。
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')
iris_data = pd.concat([iris_data, encoded_species], axis=1)
iris_data.drop(columns=['species'], inplace=True)

7. 浮点数列的归一化
归一化是将数值特征缩放为均值为0、标准差为1的过程,这一过程旨在确保各特征对分析的贡献相等。本文将对浮点数列进行归一化,以便进行一致的缩放。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
scaled_data = scaler.fit(iris_data[cols_to_normalize])
iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize])
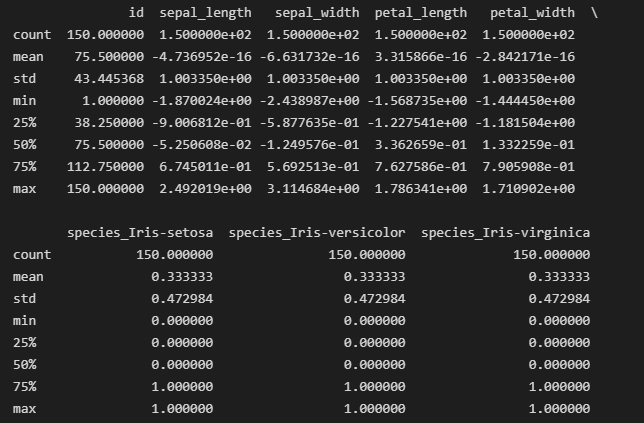
归一化后的iris_data.describe()输出结果
8. 保存清洗后的数据集
将清洗后的数据集保存到新的CSV文件中。
iris_data.to_csv('cleaned_iris.csv', index=False)
如果完成上述步骤,你已成功使用Pandas清洗了第一个数据集。在处理复杂数据集时,可能会遇到其他挑战,然而本文介绍的基本技术将帮助你入门,并为开始数据分析做好准备。