广州网站建设海珠信科中国最新消息
python – 批量读取多个文件,并将每个文件中相同变量累加
情况描述
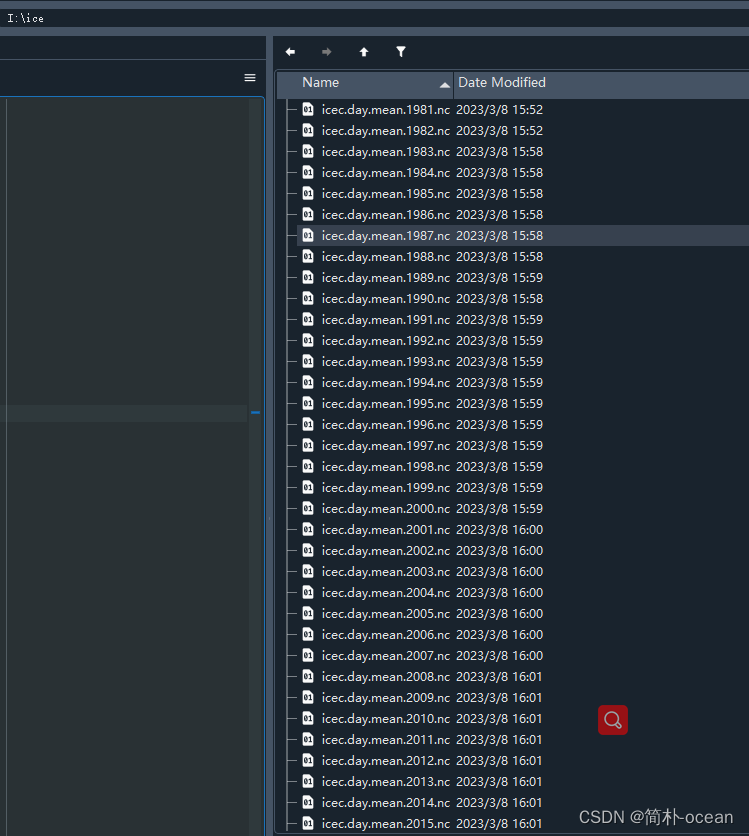
- 现有多个nc文件,位于同一个文件夹中,如下所示
- 每个文件中都有相同的变量,想要读取每个文件中的变量然后将其加起来
- 意思就是说:
文件1中的变量+文件2中的变量+文件3中的变量+....
解决思路
1、先将所有的文件名所包含的路径读取到一个list
2、对于list进行循环读取,读取每个文件中相同的变量
3、先打开第一个文件中的变量,将后续文件中的变量累加到第一个文件中命名的变量
4、将结果写入到新的nc文件中并进行保存
对于第一个步骤,读取一个目录下所有指定类型的文件,我们可以通过glob函数来完成
对于第二个步骤,读取nc文件可以通过netcdf、xarray(任选一个)来完成
对于第三个步骤,直接写个循环就完事了
最后一个步骤使用to_netcdf()函数来完成
下面给出一个手把手的代码示例:
代码示例 – 以xarray库读取
1、导入库
import xarray as xr
import glob
2、读取所有文件
path = 'file_locate_path'
这里的路径,改为你自己文件所在的路径,注意在python中路径直接应该是反斜线/
例如我这里文件都在I盘下的ice文件夹,关于批量读取文件的教程,可以看我之前分享的教程,非常详细了:
1、批量读取相同格式文件(多个文件夹/单个文件夹)—nc文件为例
2、批量处理nc文件-字符串拼接文件,有规律文件名
3、批量读取地转流速日资料绘制气候态年平均海表流场(填色为流速)
## 获得文件路径列表
path = r'I:/ice/'
file_list = glob.glob(path+'*nc')
读取完,如果你使用的是spyder这个编辑器的话,可以在变量栏中看到如下内容:
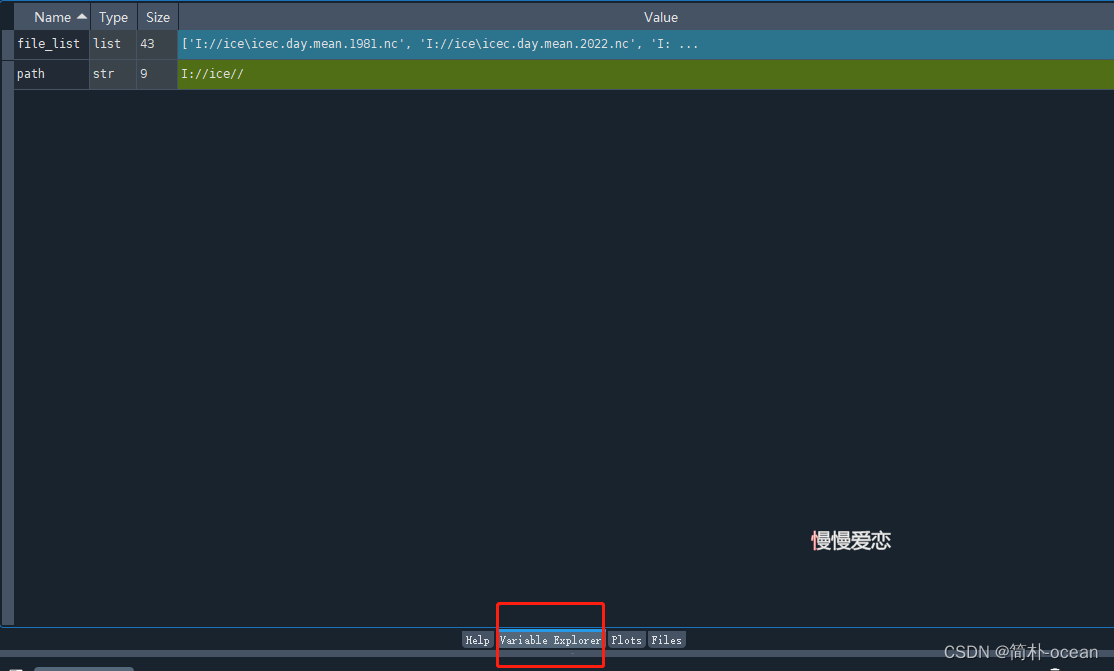

点开这个file_list,(或者使用命令行的话,可以在命令行中输入file_list),我这里,文件夹下一共有43个文件:
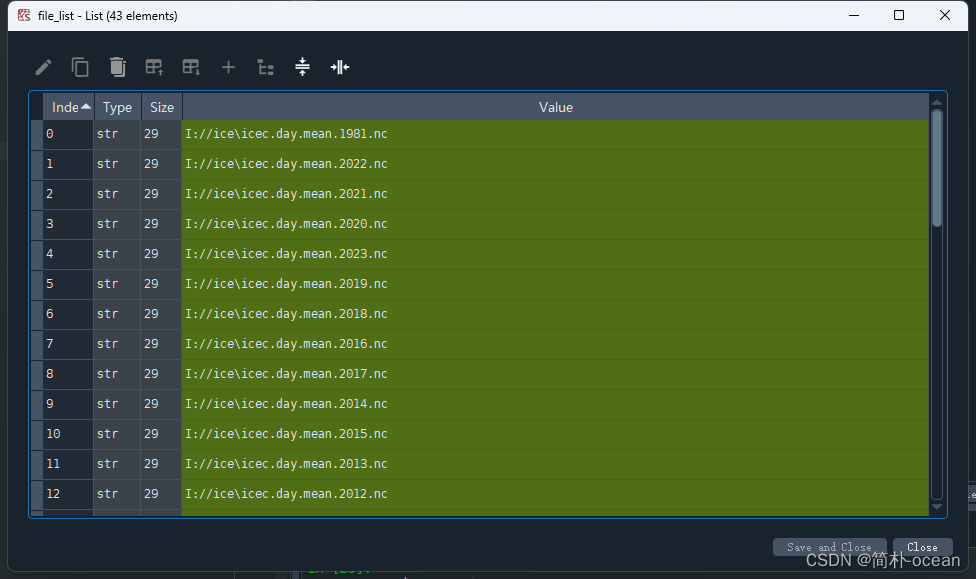
就是上面这一个样子,每个文件的路径加上文件的名称,这一步就没问题啦~~
读取第一个文件的变量
打开第一个文件并读取变量
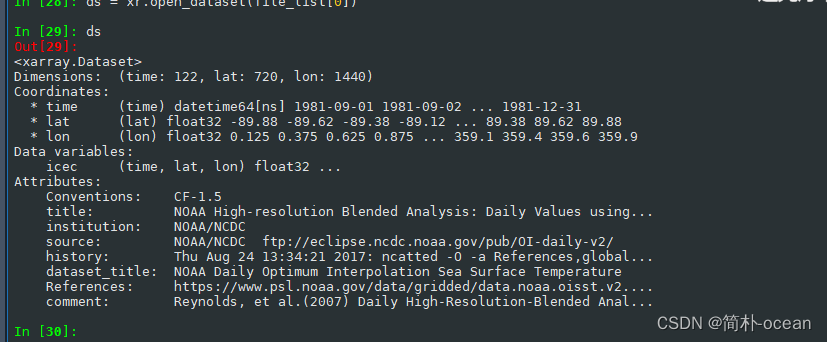
ds = xr.open_dataset(file_list[0])
可以简单看一下文件信息,以及变量名称,我们这里的变量名称为:icec,这个变量包含3个维度,时间(time)、纬度(lat)、经度(lon)。可以发现,每个变量都有122个time。还是挺大的。
对于上一步不熟悉的的,可以看看我之前的一个读取nc的教程:
手把手教你读取nc文件
ps:
为了节省计算时间,我这里仅做展示,取43个文件中的前10个文件,以及每个变量的第一个时刻进行累加。参考的朋友们这一步可以跳过
file_list = file_list[0:10] # 取文件前10个为例
# 打开第一个文件并读取变量
ds = xr.open_dataset(file_list[0])
var_name = 'icec'
# 取变量的第一个时刻
temp_sum = ds[var_name][0]循环打开剩余的文件进行累加
# 依次打开剩余文件并将temp变量累加到temp_sum中
for file in file_list[1:]:print(file)ds = xr.open_dataset(file)temp_sum += ds[var_name][0]
写入新的文件
# 将结果写入新的netCDF文件
temp_sum.to_netcdf('temp_sum.nc')
示例2-以netcdf库读取:
大致过程都类似,就不展示具体细节了,根据需要进行更改就行
import netCDF4 as ncpath = r'I:/ice/'
file_list = glob.glob(path+'*nc')
# 定义文件列表和变量名var_name = 'icec'# 打开第一个文件并读取变量
with nc.Dataset(file_list[0], 'r') as f:temp_sum = f.variables[var_name][:][0]# 依次打开剩余文件并将temp变量累加到temp_sum中
for file in file_list[1:]:with nc.Dataset(file, 'r') as f:temp_sum += f.variables[var_name][:][0]# 将结果写入新的netCDF文件
with nc.Dataset('temp_sum.nc', 'w') as f:# 创建一个新变量temp_sum_var = f.createVariable(var_name, temp_sum.dtype, ('time', 'lon', 'lat'))# 将累加结果写入变量temp_sum_var[:] = temp_sum
示例3–使用并行计算来加速计算过程
import dask.array as da
import dask.distributed as dd# 定义文件列表和变量名
## 获得文件路径列表
path = r'I:/ice/'
file_list = glob.glob(path+'*nc')file_list = file_list[0:10] # 取文件前10个为例# 创建Dask客户端
client = dd.Client()
var_name = 'icec'
# 使用Dask读取文件和变量
ds = xr.open_mfdataset(file_list, parallel=True)[var_name]# 将数据分块
chunks = {'time': len(ds.time)//40, 'lon': ds.lon.size, 'lat': ds.lat.size}
ds = ds.chunk(chunks)# 计算变量的累加和
temp_sum = da.sum(ds, axis=0)# 将结果写入新的netCDF文件
temp_sum.to_dataset(name=var_name).to_netcdf('temp_sum.nc')