如何做博客网站超级外链吧外链代发
开发的MES,往往都要做生产执行跟踪扫描,这样会产生大量的扫描数据,用关系型数据库,很容易造成查询冲突的问题。
生产跟踪扫描就发生的密度是非常高的,每个零部件的加工过程,都要被记录下来,特别是在大型工厂。写入密度高,但是每次写入的记录都很少,如果程序设计是实时往数据库写入记录,那基本是每次一条记录,且写入的频率很高,导致表锁时常发生,对查询扫描日志会带来很大的压力。
解决跟踪扫描的问题,最好的办法还是用缓存(Redis),而且要共享缓存,就是不同用户使用同一个缓存空间,防止相同的零部件扫描时候,不会出现相互冲突。实际生产过程中,扫描冲突是不应该发生的,但是偏偏就是会发生,例如操作员后补扫描。程序发起扫描请求时候,先去查询缓存是否存在扫描记录,如果有,则根据缓存中的数据进行扫描校验,例如是否存在扫描的编号、重复扫描、扫描次数限制等;如果缓存中没有数据,则表明零部件从来没有被扫描过,则从数据库中加载基础信息,例如零部件的信息、工序的信息、工作中心的信息等,然后这些信息也放到缓存中,基础信息不能存放太久,一般扫描也就毫秒级完成,算1秒吧,可以设置缓存超时清除,我这里是设置10分钟的绝对超时,10分钟后重新从数据库加载基础数据。
扫描数据一直保存在缓存中,根据生产周期,也可以设定一个延期超时,例如90天,每访问一次,就重置超时时间。扫描记录,可以全部存放到内存缓存中(MemoryCache),用一个定时器往数据库中写入扫描记录,不管扫描是否成功,日志都要写入数据库保存。如果出现数据库事务冲突或者超时,则后续继续往数据库中写入,直到写入成功后,才从内存缓存中移除扫描数据。
一般来说,程序设计查询扫描记录,从缓存中查询即可,数据结构采用Hash保存:
Key: Scan_零部件编号,注意,部件编号这里是全局唯一
HashKey 工序编号
Value 扫描数据json [ {'scanTime':'2024-01-01','operator':'001'}]
因为同一个工序,可能需要扫描2次或者以上的,所以value的设计是个集合
当查询的时候,只需要把key的所有数据一次性读取出来丢去前端即可,完全不需要查询数据库。不管是写入还是读取,都比数据库快很多,代码也很简洁。当然,之类最好把操作缓存的功能封装成一个工具类,毕竟设计到内存缓存和Redis。
在常规的需求中,以上功能已经完全满足日常生产需求,但是,如果超过了90天后,扫描缓存被清除了呢?那么,就需要在数据库中查询组织数据,并重新写入到缓存中。那么,使用clickhouse查询,那是完全优于使用关系数据库,例如oracle、sqlserver、mysql、postgresql。不仅仅是构造扫描缓存,可能还要做一些分析,这里只是用最简单的一个查询来说明clickhouse和关系数据库之间的一些差异。
第一,要把数据同步到clickhouse。前边也已经踩坑了,系统使用的mssql,开发语言是C#,研究了很久,没有现成的方案同步,或者说,还没弄明白。本来打算flink-cdc同步数据,结果弄出一堆问题来,还是没搞通,所以,这个事暂时耽搁下来,自己写了一个cdc的同步工具,也就2天时间,够用就好了,凑合着,后续再研究flink。flink官方没有现成的clickhouse-sink,哪位大神指点一二!
第二,涉及到的查询关键字。用到的关键字做一个简单的说明:
limit n by exp
根据字段取第n条记录,这个关键字不能和distinct同时使用,只取其一。例如扫描记录出现重复的扫描日志,要取最后一次,这样需要配合order by才能实现。limit在clickhouse中,不仅仅用于分页,例如记录中出现(key,value)= {a,1},{a,2},order by value limit 1 by key,则会得到{a,1},第二条记录会被过滤掉。
first_value(exp1) over(partition by exp2 order by exp3)
根据字段exp2分组,exp3的顺序,取第一条记录exp1的值。例如扫描记录有5个步骤,取第一个步骤的工序编号 first_value(processid) over(partition by partId order by scanTime)
groupArray(exp1) over(partition by exp2 order by exp3 Rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
加载分组中字段后的exp1字段的所有值,例如部件扫描了5个工序,这个查询构造出一个列表字段,返回扫描的所有工序编号 {001,002,003,004,005},同理,用相同的方法把扫描时间也查出来,放到另外一个字段,顺序是一样的
上述关键字,会对查询条件有限制的,出现在where中的字段,必须在select中出现,类似group by的要求,这个好办,最一个子查询就可以解决了:
with tb as (select ... from ... where ...)
select * from tb
这样就完全规避了查询限制
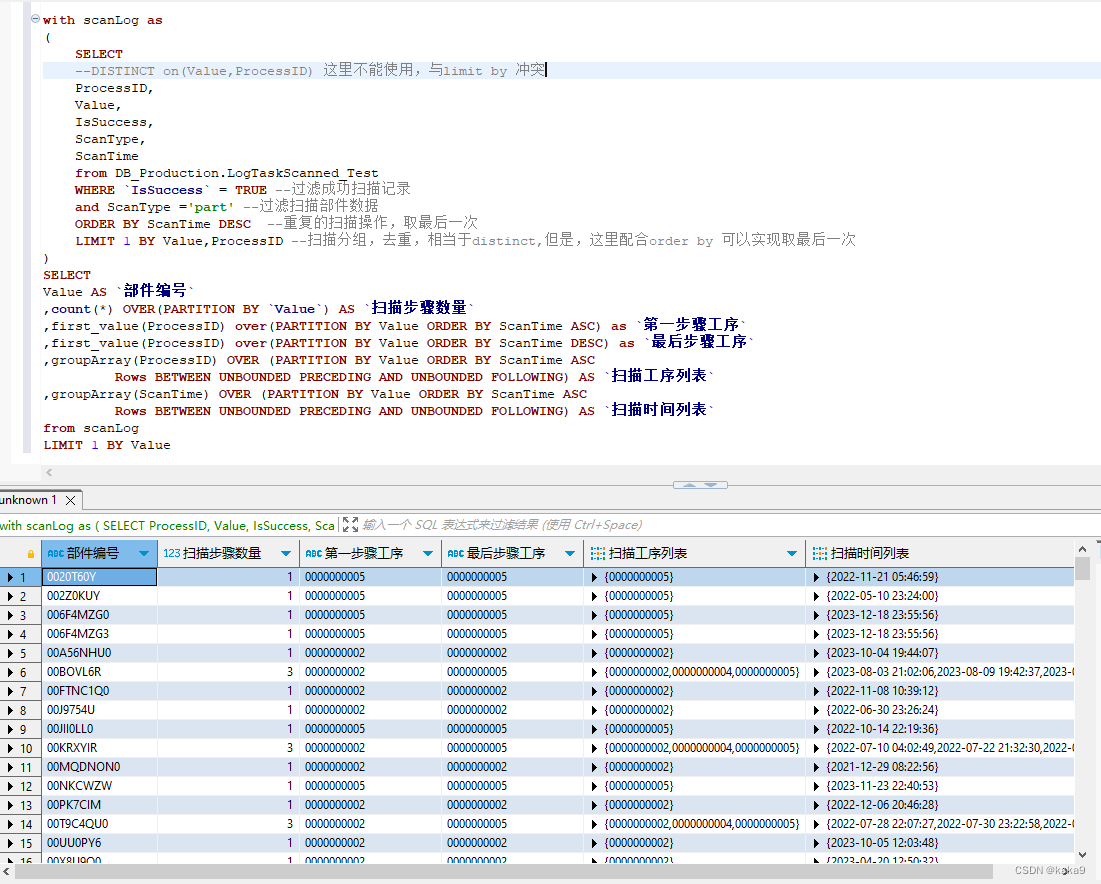
上个例子,一般的关系数据库是很难实现这样的分组查询,当然,用后端代码也能构造出这样的结构,就另说了。
在mes中,有很多复杂的查询,生产库使用mssql,查询库使用clickhouse,实现了读写分离。mssql通过cdc与clickhouse同步,开发的cdc同步组件,同时支持rabbitmq,可以把变更数据通过rabbitmq分发出去,让其他应用做实时数据统计和分析。
clickhouse驱动在开发语言中还是很丰富的,我使用的是clickhouse.client,在nuget中直接安装即可,使用起来和ado差不多,git中有比较完整的文档。这里报告一个bug,执行executeNonQuery返回整数时候,无论是否成功,都返回0,这个就很蛋疼了!
一开始的时候,读写分离用的是ssis同步到另外一台mssql,虽然这样很方便,但是也有不方便的时候,例如要修改目标数据库的内容,会导致ssis同步报错,关键是,当数据量上亿的时候,再怎么优化也很慢,占用的磁盘空间也大,clickhouse经过压缩后,压缩比例普遍在15~25%左右,可以节约大量的磁盘空间。只要设置好表的分区分片,性能那是杠杠的。