模仿网站怎么防止侵权临沂google推广
| 标题 | 详情 |
|---|---|
| 作者简介 | 愚公搬代码 |
| 头衔 | 华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,亚马逊技领云博主,51CTO博客专家等。 |
| 近期荣誉 | 2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主,2024年华为云十佳博主等。 |
| 博客内容 | .NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 |
| 欢迎 | 👍点赞、✍评论、⭐收藏 |
文章目录
- 🚀前言
- 🚀一、请求模块urllib3
- 🔎1. urllib3 简介
- 🔎2. 安装 urllib3
- 🔎3. 发送网络请求
- 🦋3.1 GET 请求
- 🦋3.2 POST 请求
- 🦋3.3 请求重试
- 🔎4. 处理响应内容
- 🦋4.1 获取响应头
- 🦋4.2 处理 JSON 响应
- 🦋4.3 处理二进制数据(如图片)
- 🔎5.复杂请求的发送
- 🦋5.1 设置请求头
- 🦋5.2 设置超时
- 🦋5.3 设置代理
- 🔎6.上传文件
🚀前言
在现代编程中,网络请求是一个不可或缺的环节,无论是数据抓取、API调用还是后端服务的交互,都会涉及到网络通讯。而在众多网络请求库中,urllib3因其强大的功能和易用性,成为了许多开发者的首选。它不仅提供了对HTTP协议的全面支持,还具备连接池、重试机制和SSL/TLS验证等多种实用特性。
在本文中,我们将深入探讨urllib3模块的基本用法,帮助你更好地理解如何利用这个库进行高效的网络请求。不论你是初学者还是有经验的开发者,掌握urllib3都将为你的项目带来极大的便利。
🚀一、请求模块urllib3
🔎1. urllib3 简介
- 定义:urllib3 是一个功能强大、结构清晰的 Python HTTP 客户端库,被许多原生 Python 系统采用。
- 核心特性:
- 线程安全
- 连接池管理
- 客户端 SSL/TLS 验证
- 多部分编码文件上传
- 请求重试与 HTTP 重定向处理
- 支持 gzip/deflate 编码
- 支持 HTTP/SOCKS 代理
- 100% 测试覆盖率
🔎2. 安装 urllib3
- 通过
pip安装(非 Anaconda 环境):pip install urllib3
🔎3. 发送网络请求
🦋3.1 GET 请求
- 步骤:
- 创建
PoolManager对象管理连接池。 - 调用
request()方法发送请求。
- 创建
- 语法:
request(method, url, fields=None, headers=None, urlopen_kw)method: 请求方法(如GET、POST)。url: 目标 URL。fields: 请求参数(字典形式)。headers: 请求头(字典形式)。
示例 1:基础 GET 请求
import urllib3 # 导入urllib3模块
url = "http://httpbin.org/get"
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request('GET',url) # 发送GET请求
print(r.status) # 打印请求状态码
示例 2:多服务器请求
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
jingdong_url = 'https://www.jd.com/' # 京东url地址
python_url = 'https://www.python.org/' # Python url地址
baidu_url = 'https://www.baidu.com/' # 百度url地址
http = urllib3.PoolManager() # 创建连接池管理对象
r1 = http.request('GET',jingdong_url) # 向京东地址发送GET请求
r2 = http.request('GET',python_url) # 向python地址发送GET请求
r3 = http.request('GET',baidu_url) # 向百度地址发送GET请求
print('京东请求状态码:',r1.status)
print('python请求状态码:',r2.status)
print('百度请求状态码:',r3.status)
🦋3.2 POST 请求
- 关键:设置
method='POST'并通过fields传递表单数据。
示例 3:发送 POST 请求
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/post' # post请求测试地址
params = {'name':'Jack','country':'中国','age':30} # 定义字典类型的请求参数
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request('POST',url,fields=params) # 发送POST请求
print('返回结果:',r.data.decode('utf-8'))
🦋3.3 请求重试
- 参数:
retries控制重试次数(默认 3 次,False禁用重试)。
示例 4:设置重试策略
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/get' # get请求测试地址
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request('GET',url) # 发送GET请求,默认重试请求
r1 = http.request('GET',url,retries=5) # 发送GET请求,设置5次重试请求
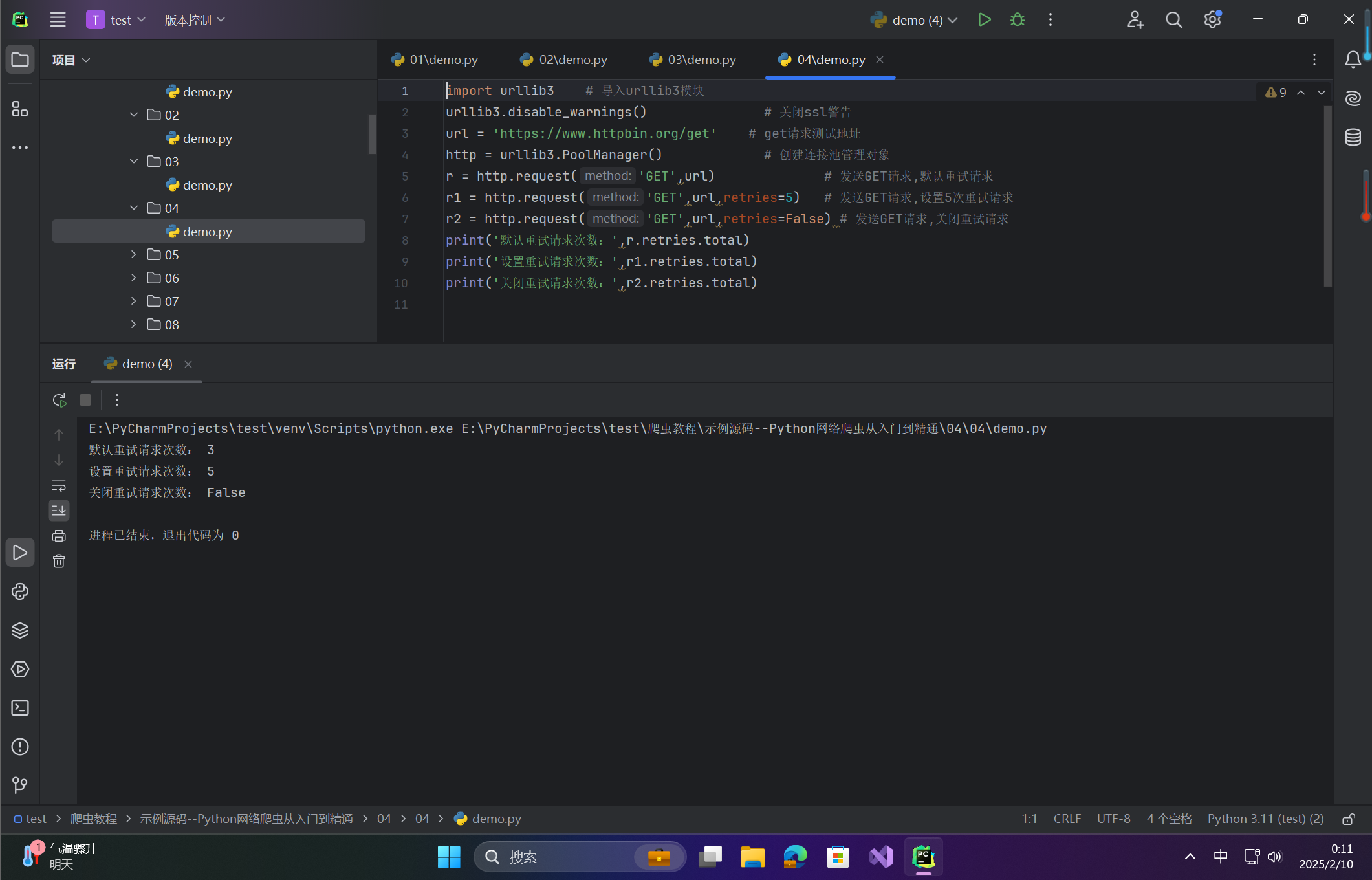
r2 = http.request('GET',url,retries=False) # 发送GET请求,关闭重试请求
print('默认重试请求次数:',r.retries.total)
print('设置重试请求次数:',r1.retries.total)
print('关闭重试请求次数:',r2.retries.total)
🔎4. 处理响应内容
🦋4.1 获取响应头
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/get' # get请求测试地址
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request('GET',url) # 发送GET请求,默认重试请求
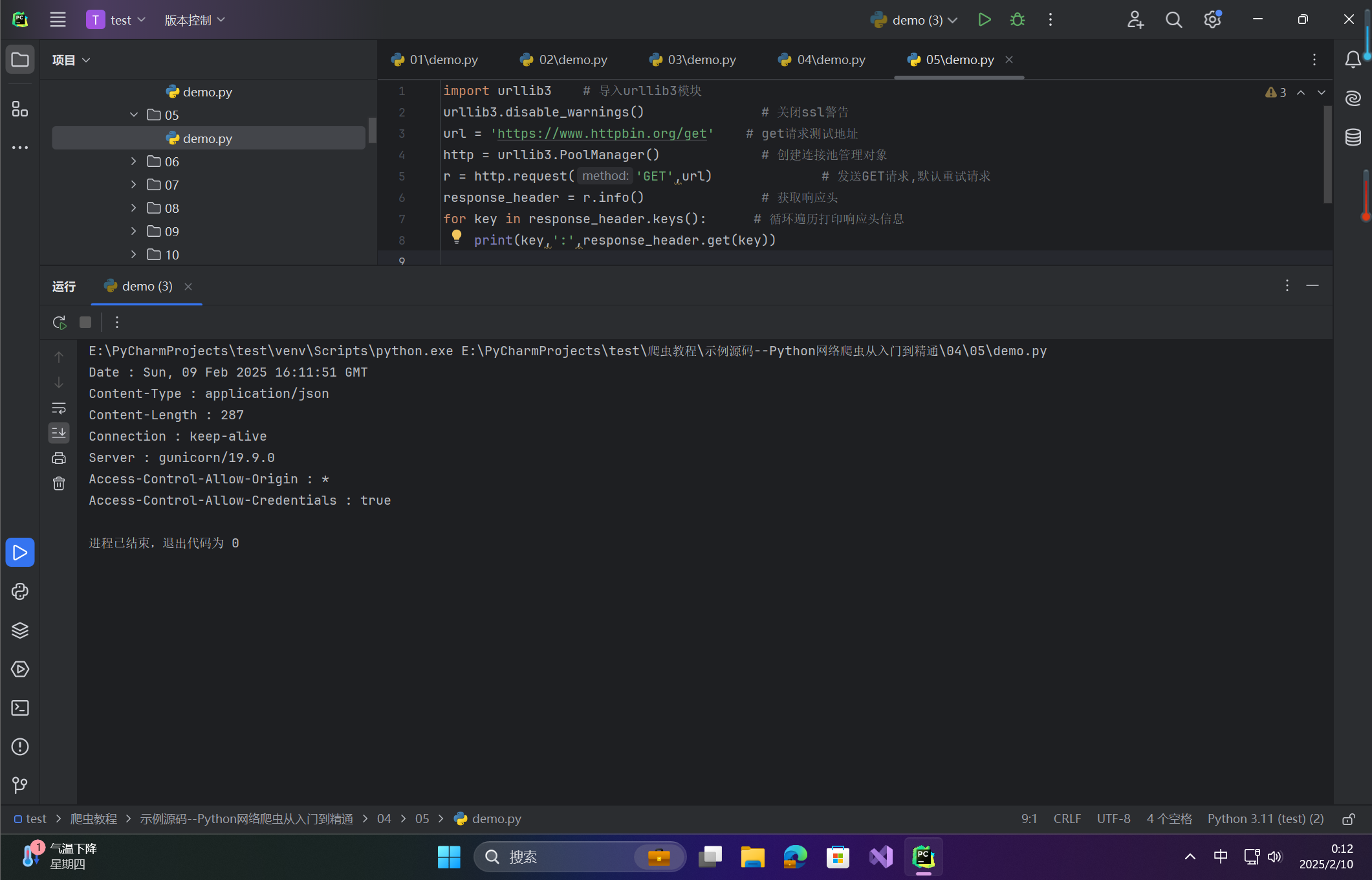
response_header = r.info() # 获取响应头
for key in response_header.keys(): # 循环遍历打印响应头信息print(key,':',response_header.get(key))
🦋4.2 处理 JSON 响应
import urllib3 # 导入urllib3模块
import json # 导入json模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/post' # post请求测试地址
params = {'name':'Jack','country':'中国','age':30} # 定义字典类型的请求参数
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request('POST',url,fields=params) # 发送POST请求
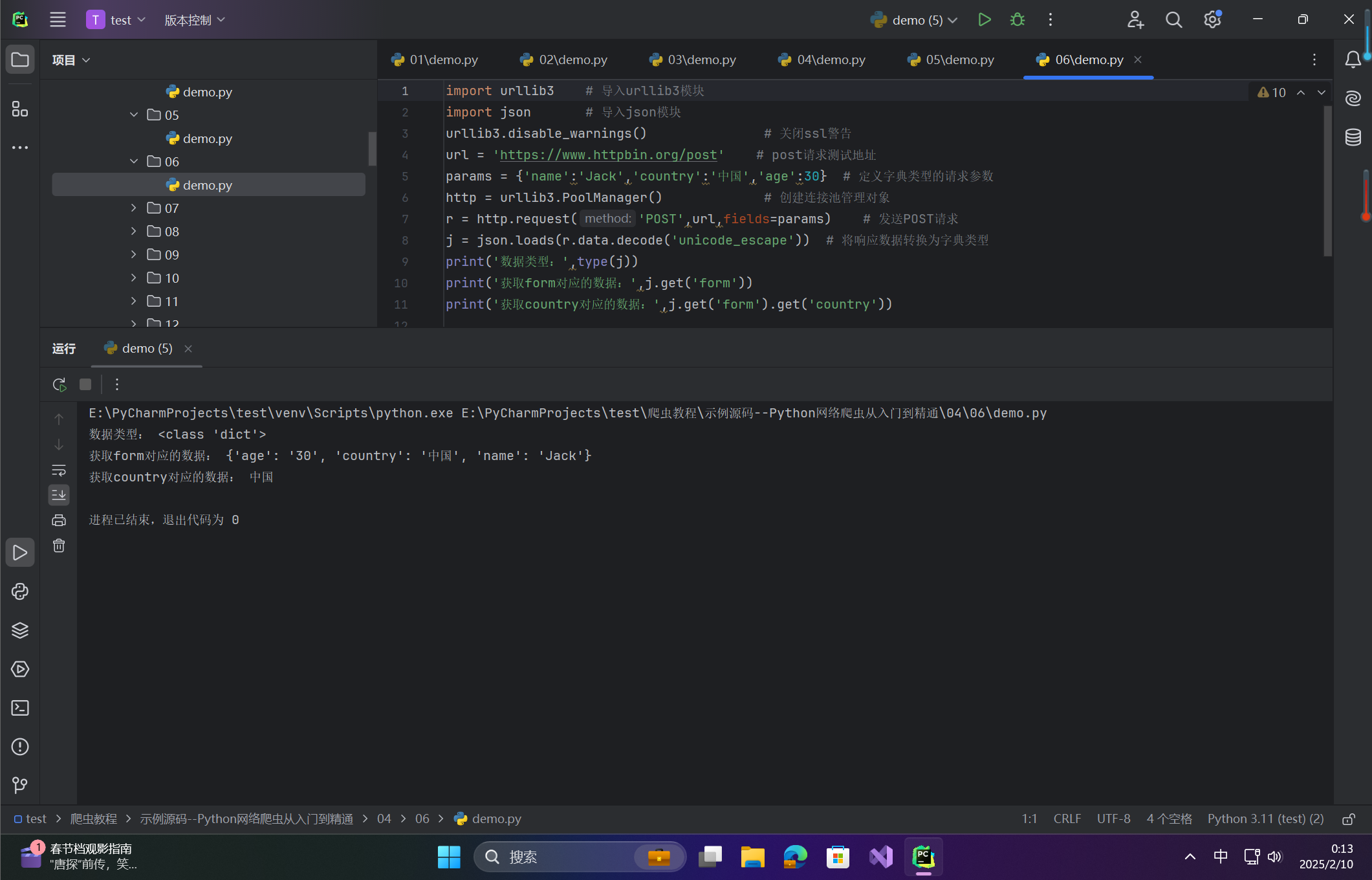
j = json.loads(r.data.decode('unicode_escape')) # 将响应数据转换为字典类型
print('数据类型:',type(j))
print('获取form对应的数据:',j.get('form'))
print('获取country对应的数据:',j.get('form').get('country'))
🦋4.3 处理二进制数据(如图片)
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
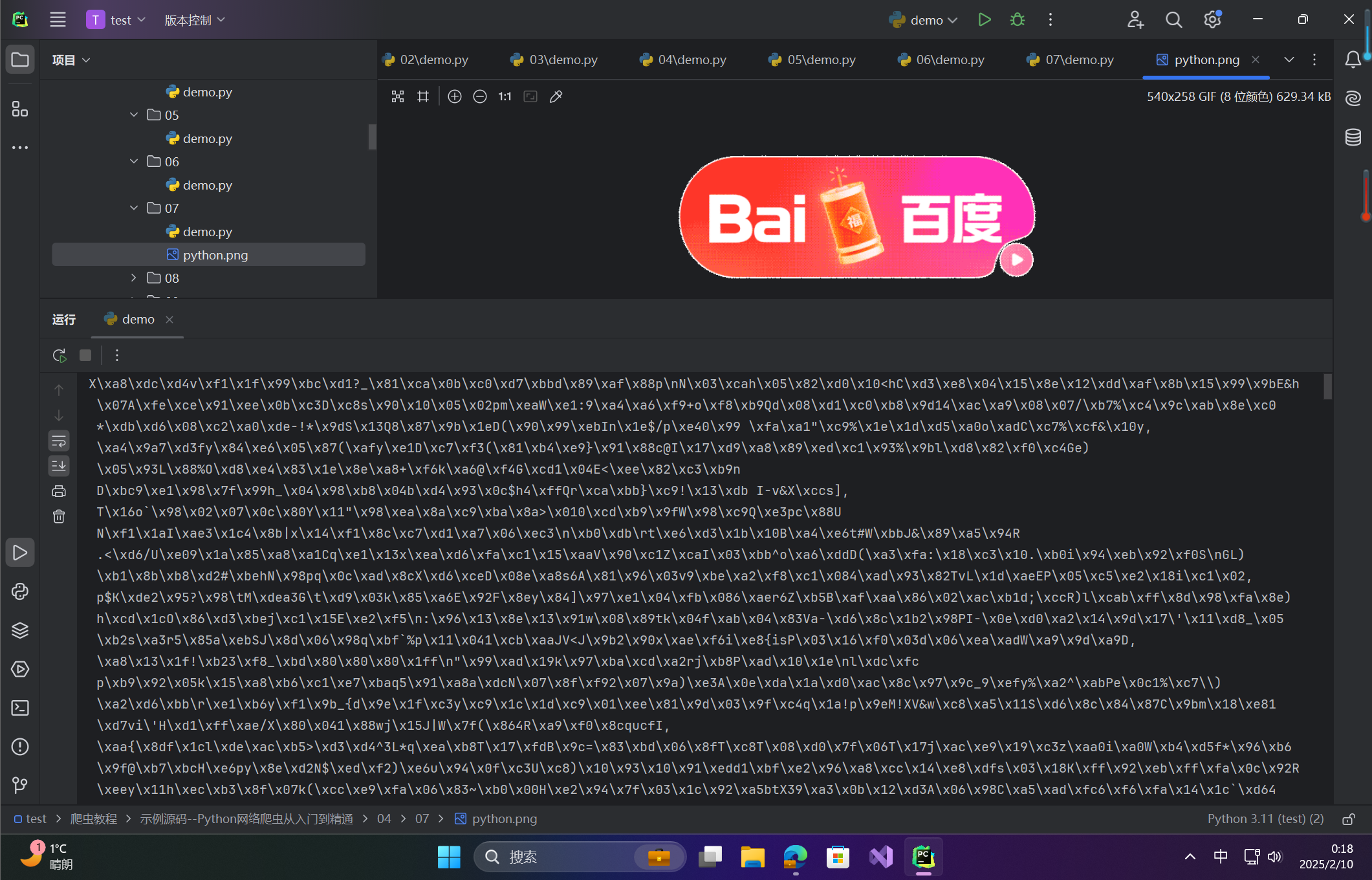
url = 'https://search-operate.cdn.bcebos.com/4466f881476a1ee804b4a32aee790675.gif' # 图片请求地址
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request('GET',url) # 发送网络请求
print(r.data) # 打印二进制数据
f = open('python.png','wb+') # 创建open对象
f.write(r.data) # 写入数据
f.close() # 关闭
🔎5.复杂请求的发送
🦋5.1 设置请求头
- 目的:模拟浏览器请求,避免被服务器识别为爬虫。
- 实现步骤:
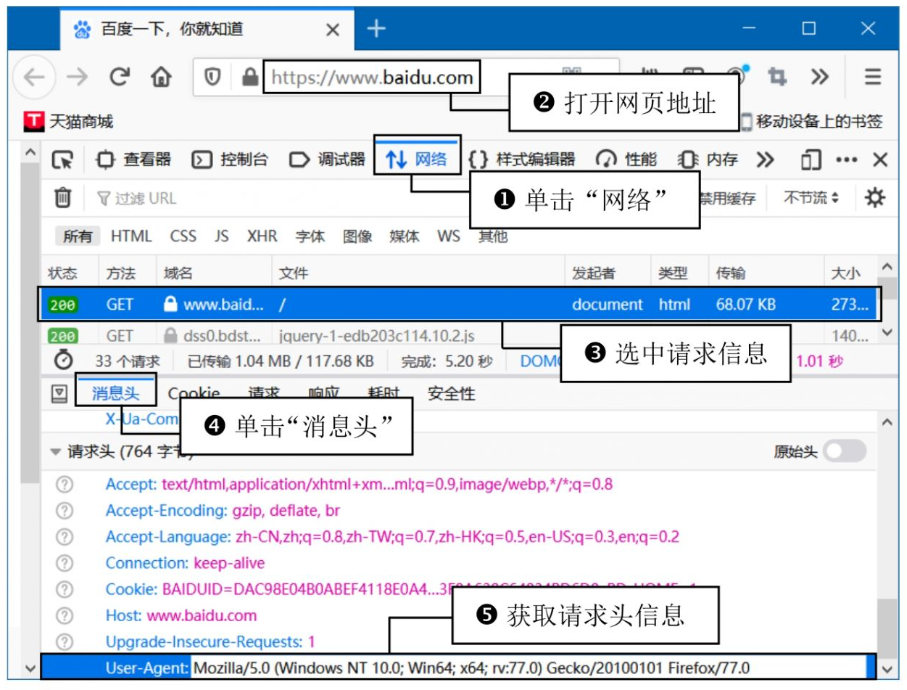
- 获取请求头信息:
- 在浏览器(如 Firefox)中按
F12打开开发者工具。 - 访问目标网页(如
https://www.baidu.com)。 - 在“网络”选项卡中选择一个请求,复制其
User-Agent值。
- 在浏览器(如 Firefox)中按
- 设置请求头:将
User-Agent作为字典键,浏览器信息作为值。
- 获取请求头信息:
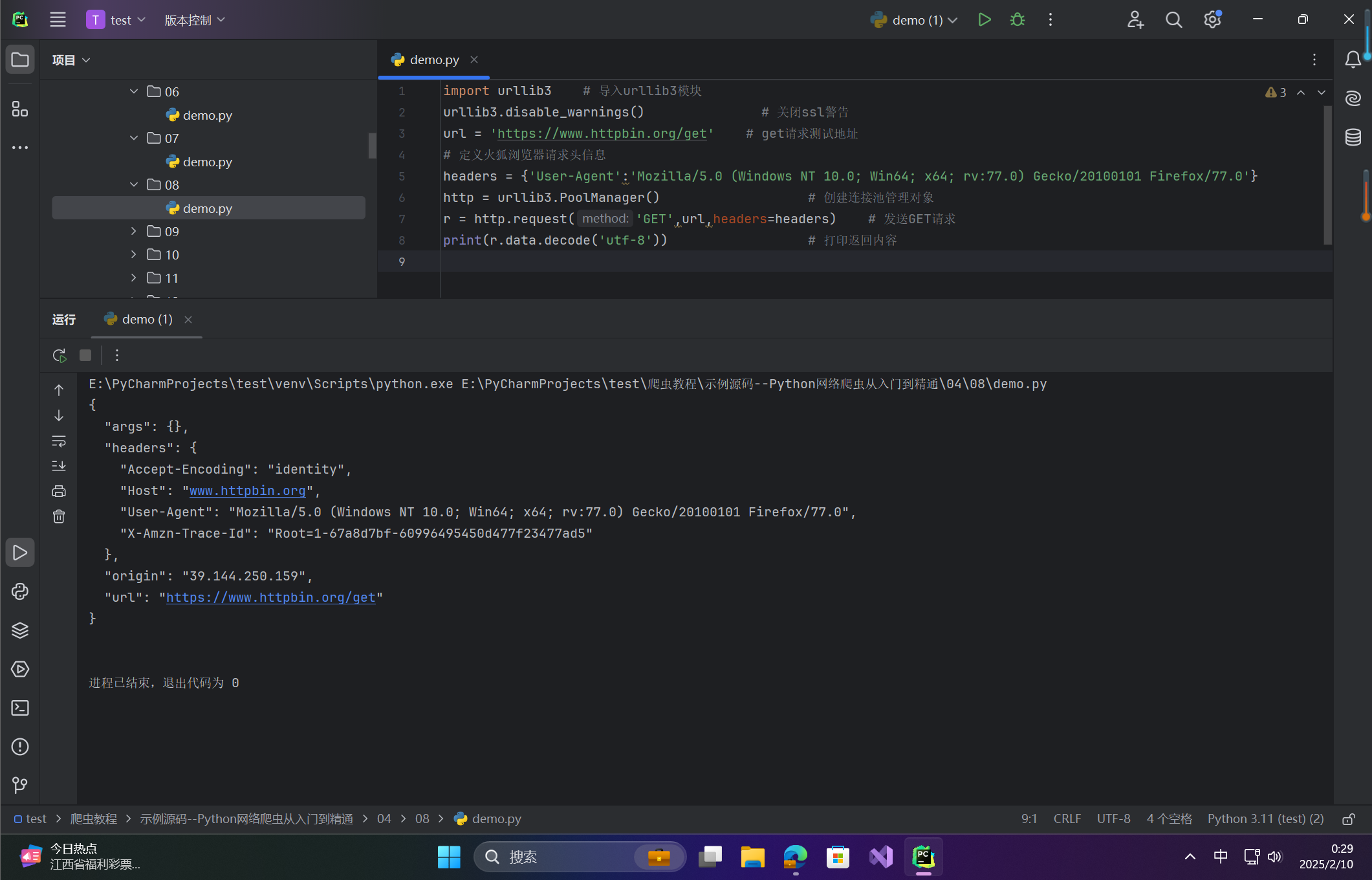
示例:设置请求头
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = 'https://www.httpbin.org/get' # get请求测试地址
# 定义火狐浏览器请求头信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0'}
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request('GET',url,headers=headers) # 发送GET请求
print(r.data.decode('utf-8')) # 打印返回内容
🦋5.2 设置超时
- 两种设置方式:
- 全局设置:在
PoolManager对象初始化时指定timeout。 - 单次请求设置:在
request()方法中直接传递timeout。
- 全局设置:在
- 精确控制:使用
Timeout类分别设置连接超时和读取超时。
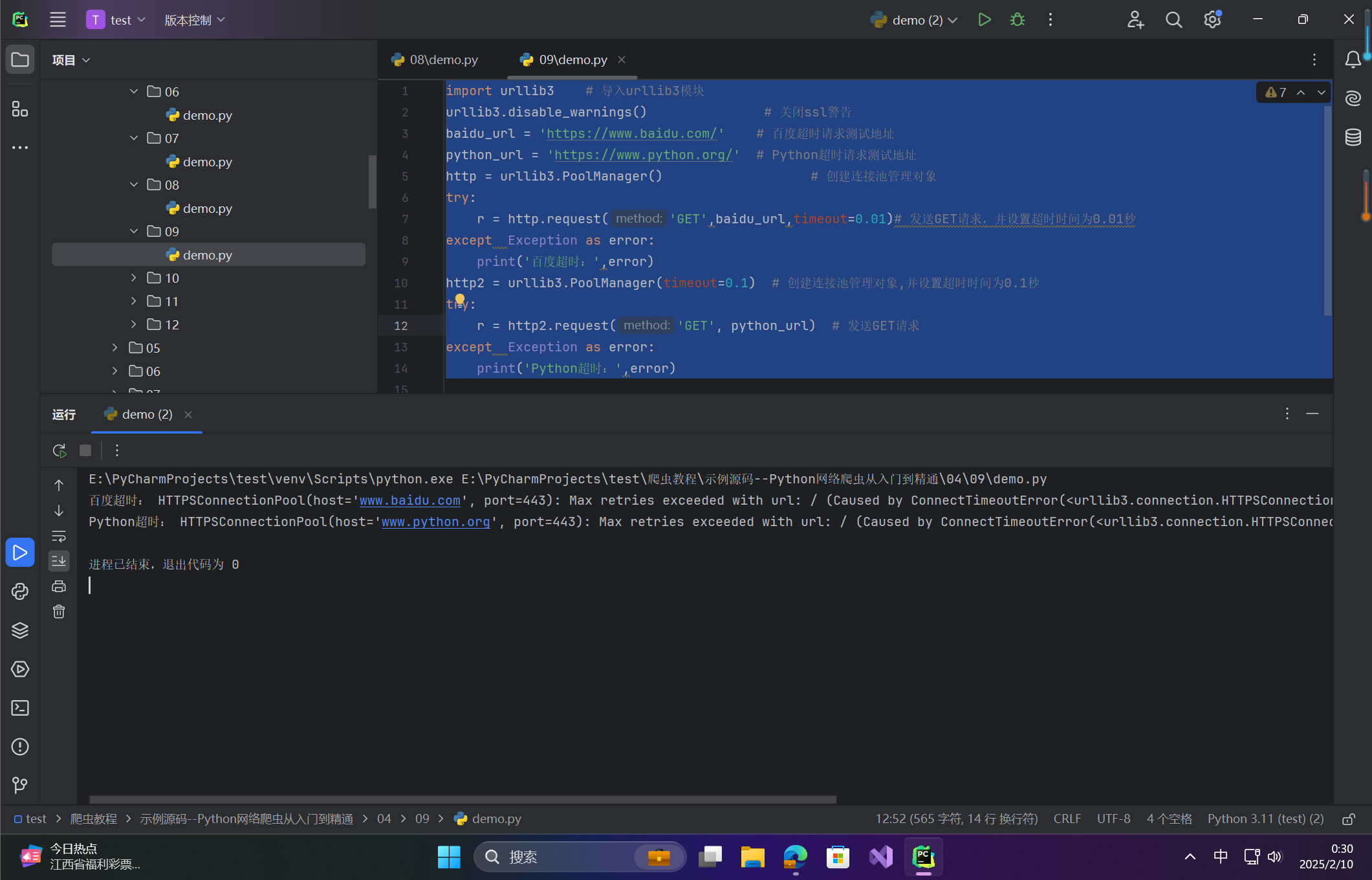
示例:基础超时设置
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
baidu_url = 'https://www.baidu.com/' # 百度超时请求测试地址
python_url = 'https://www.python.org/' # Python超时请求测试地址
http = urllib3.PoolManager() # 创建连接池管理对象
try:r = http.request('GET',baidu_url,timeout=0.01)# 发送GET请求,并设置超时时间为0.01秒
except Exception as error:print('百度超时:',error)
http2 = urllib3.PoolManager(timeout=0.1) # 创建连接池管理对象,并设置超时时间为0.1秒
try:r = http2.request('GET', python_url) # 发送GET请求
except Exception as error:print('Python超时:',error)
示例:精确超时控制
from urllib3 import Timeout
import urllib3 # 导入urllib3模块
urllib3.disable_warnings()
# 设置连接超时 0.5秒,读取超时 0.1秒
timeout = Timeout(connect=0.5, read=0.1)# 方式1:全局设置
http = urllib3.PoolManager(timeout=timeout)
http.request("GET", "https://www.python.org")# 方式2:单次请求设置
http = urllib3.PoolManager()
http.request("GET", "https://www.python.org", timeout=timeout)
🦋5.3 设置代理
- 核心类:
ProxyManager,需指定代理地址和请求头。 - 作用:隐藏真实 IP 或访问受限制资源。
示例:通过代理发送请求
import urllib3 # 导入urllib3模块
url = "http://httpbin.org/ip" # 代理IP请求测试地址
# 定义火狐浏览器请求头信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0'}
# 创建代理管理对象
proxy = urllib3.ProxyManager('http://120.27.110.143:80',headers = headers)
r = proxy.request('get',url,timeout=2.0) # 发送请求
print(r.data.decode()) # 打印返回结果
输出:
{"origin": "120.27.110.143"
}
🔎6.上传文件
- 两种方式:
- 文本文件:通过
fields参数以元组形式传递。 - 二进制文件:通过
body参数直接传递数据,并指定Content-Type。
- 文本文件:通过
示例:上传文本文件
import urllib3 # 导入urllib3模块
import json # 导入json模块
with open('test.txt') as f: # 打开文本文件data = f.read() # 读取文件
http = urllib3.PoolManager() # 创建连接池管理对象
# 发送网络请求
r = http.request( 'POST','http://httpbin.org/post',fields={'filefield': ('example.txt', data),})
files = json.loads(r.data.decode('utf-8'))['files'] # 获取上传文件内容
print(files) # 打印上传文本信息
输出:
{"filefield": "在学习中寻找快乐!"
}
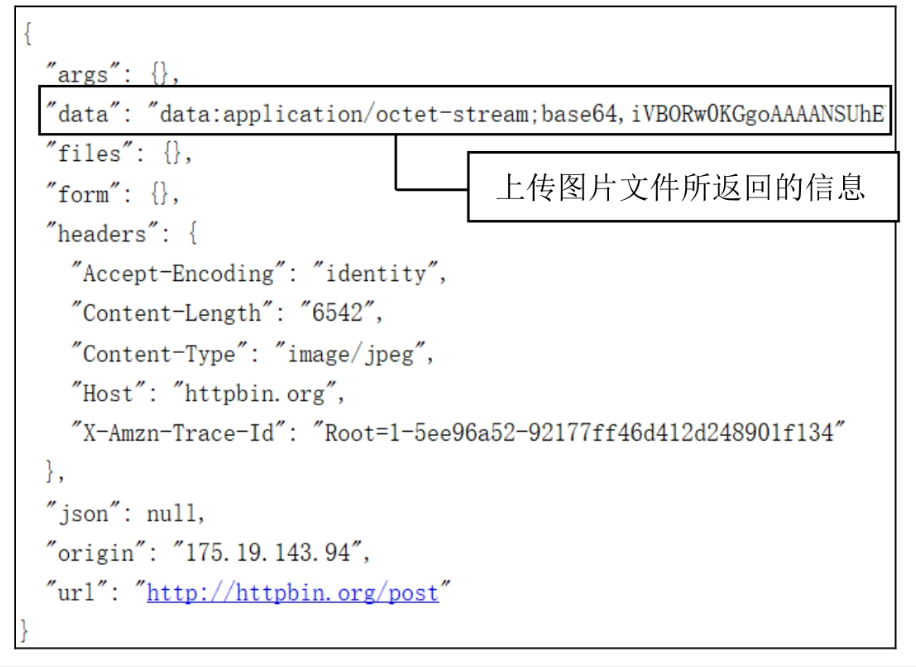
示例:上传图片文件
import urllib3 # 导入urllib3模块
with open('python.jpg','rb') as f: # 打开图片文件data = f.read() # 读取文件
http = urllib3.PoolManager() # 创建连接池管理对象
# 发送请求
r = http.request('POST','http://httpbin.org/post',body = data,headers={'Content-Type':'image/jpeg'})
print(r.data.decode()) # 打印返回结果