163邮箱官方注册入口seo关键词排名价格
背景
整合了一下 SpringCloudSleuth + Zipkin,本来是很简单的东西,但是最终导出依赖包时没注意,导致目标服务始终没有被纳入 Zipkin 的链路追踪中,本文记录这个过程及关键依赖包。
部署zipkin
官网下载最新的 zipkin 可执行包,重命名为 zipkin.jar ,然后编写一个启动脚本 start.sh ,内容如下:
nohup java -jar zipkin.jar >/dev/null 2>&1 &
以默认配置直接启动该组件。
整合过程
SpringCloud 项目中整合 Sleuth + Zipkin ,只需要添加两个依赖:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId><version>3.0.3</version>
</dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-zipkin</artifactId><version>3.0.3</version>
</dependency>
sleuth 直接用默认配置,然后为 zipkin 配置 base-url 属性:
spring:zipkin:sender:type: webbase-url: http://IP:9411/
关键依赖包
目标服务是通过抽取公共 jar 的方式部署的,对本地应用打包后导出的第三方 jar 包进行分析,找出 sleuth + zipkin 依赖的文件列表:
admin@MyPc libdep % ll |awk '{print $NF}'|grep -E "sleuth|zipkin"
spring-cloud-sleuth-api-3.0.3.jar
spring-cloud-sleuth-autoconfigure-3.0.3.jar
spring-cloud-sleuth-brave-3.0.3.jar
spring-cloud-sleuth-instrumentation-3.0.3.jar
spring-cloud-sleuth-zipkin-3.0.3.jar
spring-cloud-starter-sleuth-3.0.3.jar
zipkin-2.23.0.jar
zipkin-reporter-2.16.1.jar
zipkin-reporter-brave-2.16.1.jar
zipkin-reporter-metrics-micrometer-2.16.1.jar
zipkin-sender-activemq-client-2.16.1.jar
zipkin-sender-amqp-client-2.16.1.jar
zipkin-sender-kafka-2.16.1.jar
因为 Sleuth 整合只引入了这两个依赖,以为就只需要上面这些 jar 包,将其他微服务的依赖路径加上上面文件所在的路径后,Zipkin 里面一直没有想过链路信息。纠结了好一会儿!为什么呢?
本地 IDEA 运行的服务有链路追踪,目标服务只引入第三方 jar ,没有。网络上介绍的用法确实很简单,只加入依赖、什么都是默认配置,就可以了。猜想还是依赖包的问题,用 maven 打开依赖试图发现有一堆 brave- 开头的 jar :
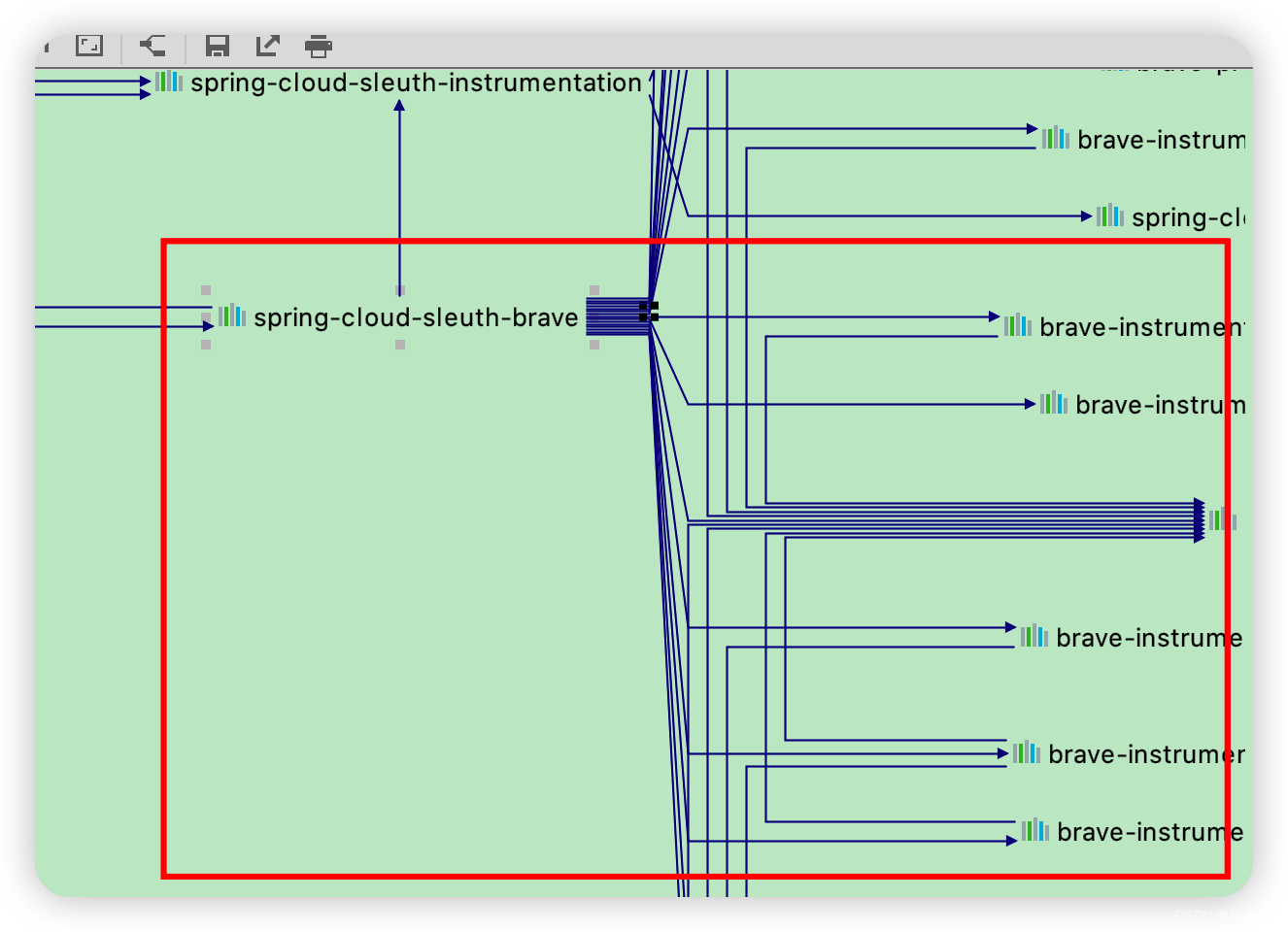
再用命令筛选出来:
admin@MyPc % ll |awk '{print $NF}'|grep -E "^brave-"
brave-5.13.2.jar
brave-context-slf4j-5.13.2.jar
brave-instrumentation-http-5.13.2.jar
brave-instrumentation-httpasyncclient-5.13.2.jar
brave-instrumentation-httpclient-5.13.2.jar
brave-instrumentation-jms-5.13.2.jar
brave-instrumentation-kafka-clients-5.13.2.jar
brave-instrumentation-kafka-streams-5.13.2.jar
brave-instrumentation-messaging-5.13.2.jar
brave-instrumentation-mongodb-5.13.2.jar
brave-instrumentation-rpc-5.13.2.jar
brave-instrumentation-spring-rabbit-5.13.2.jar
brave-propagation-aws-0.21.3.jar
看后缀,筛掉没有用到的,最终确认了六个必须的:
brave-5.13.2.jar
brave-context-slf4j-5.13.2.jar
brave-instrumentation-http-5.13.2.jar
brave-instrumentation-httpasyncclient-5.13.2.jar
brave-instrumentation-httpclient-5.13.2.jar
brave-propagation-aws-0.21.3.jar
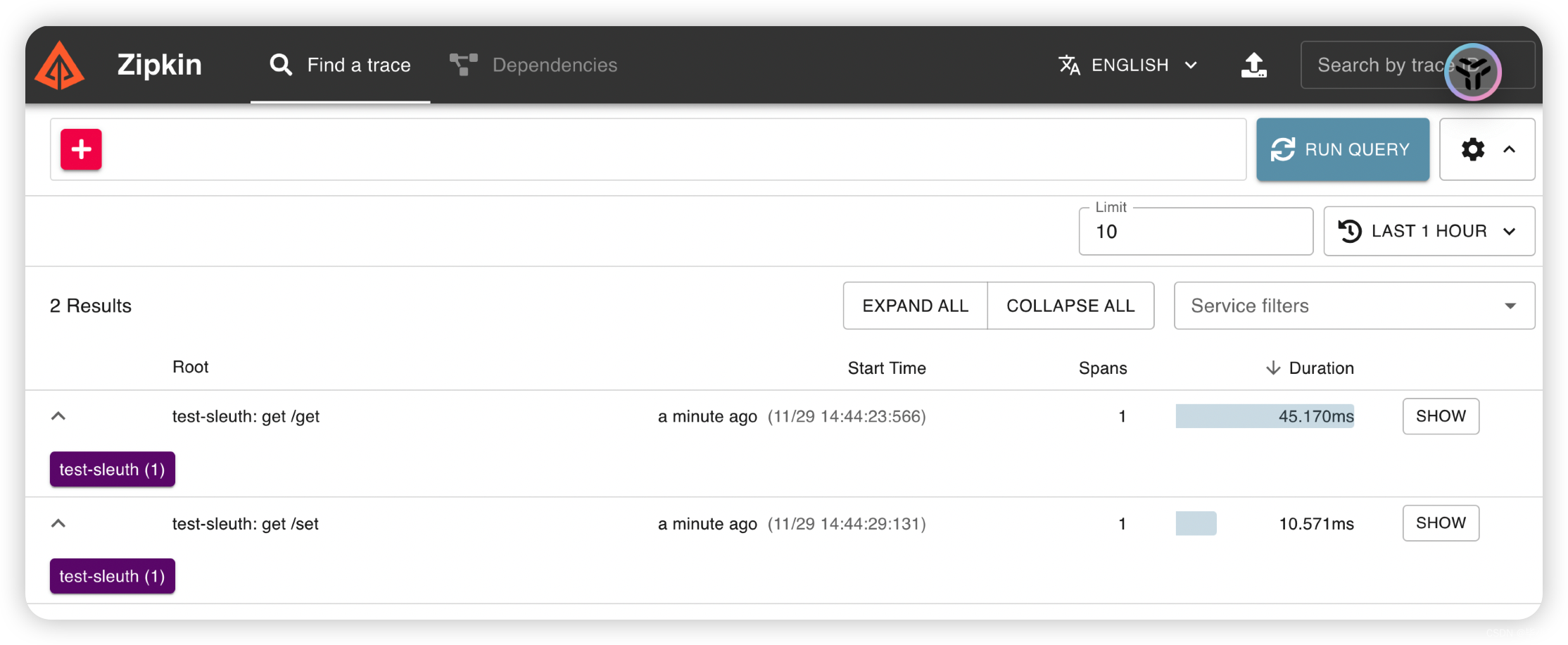
加上它们后目标服务都纳入了 Zipkin 管理了:
启示录
看似只加入两个依赖,其实还有很多其他依赖,没有细看导致很简单的一个整合问题,纠缠了好半天。
现用现学得玩了一下 Linux 命令,汇总如下
grep -rl 目标字符串 目标目录,l参数只输出文件名称。- 抽取 Sleuth 依赖包:
ll |awk '{print $NF}'|grep -E "sleuth|zipkin"|xargs -I 参数别名 mv 参数别名 目标目录。 - 批量编辑文件:
sed -i s/old/new/g 文件名称,特殊字符 . \ 等都需要转义。 if [ -z 变量 ]括号两边必须有空格脚本才会正确。- sleuth + zipkin 的核心包是 brave,我以为只是 sleuth 和 zipkin 的包呢。
最后还有一点,就是 Sleuth 之所以能跟踪链路,底层是 AOP 代理。有一个模块中使用了 @Scheduled 定时任务注解在一个 private 方法上导致启动报异常:
but cannot be delegated to target bean.Switch its visibility to package or protected.
解决办法是:
- 改为 public 、protected、package 修饰方法。
spring.sleuth.scheduled.enabled=false,禁用系统的处理逻辑,这样就追踪不到后台任务的服务调用链了。