什么网站做b2b免费网站制作app
一、带富文本标签的框选是什么
UGUI的InputField提供了selectionAnchorPosition和selectionFocusPosition,开始选择时的光标下标和当前光标下标
对于未添加富文本标签时,直接通过以上两个值,判断一下框选方向(前向后/后向前),进而对inputfield的text内容进行字符串拆分即可
相关基础内容可以看一些参考博客
https://blog.51cto.com/u_15296378/7884559
但是对于有富文本标签的inputfield,这两个值,返回的只是表面看起来的索引,并没有包含富文本标签。
举个栗子:
对于一段普通文本(未添加富文本):今天没有下雨
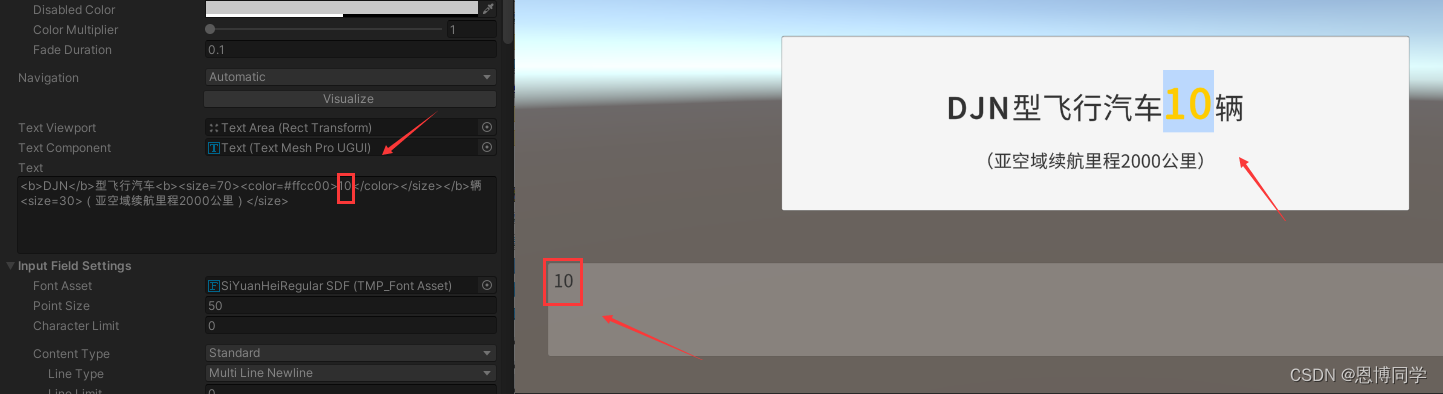
你想选择“没有下”,那么索引应该是,2和4
但是对于一段富文本内容:今天<b>没有</b>下雨
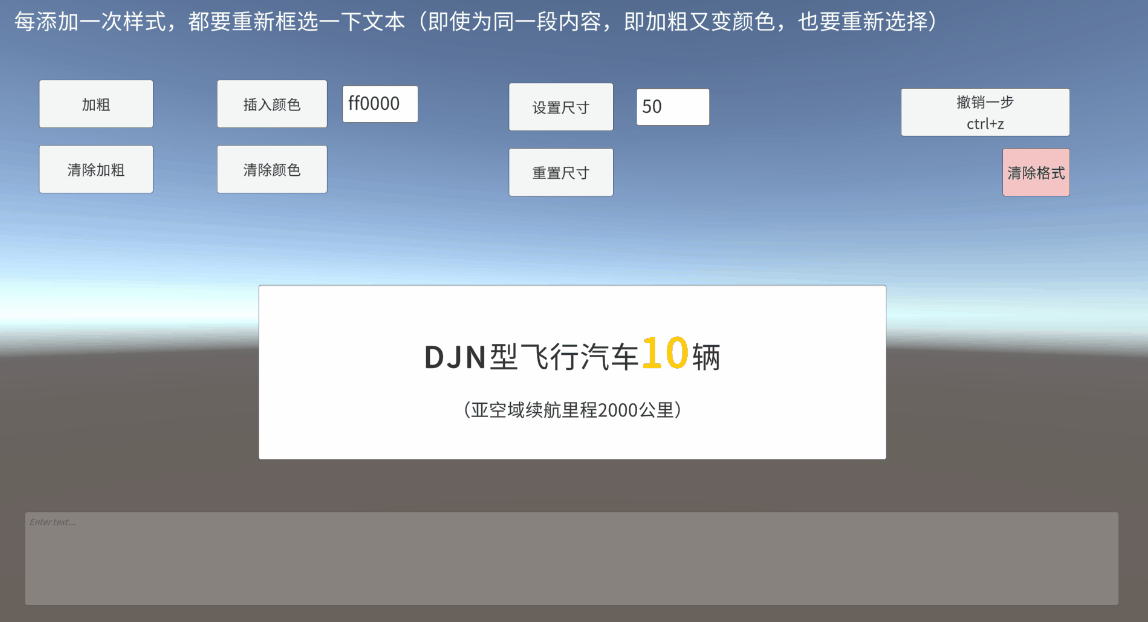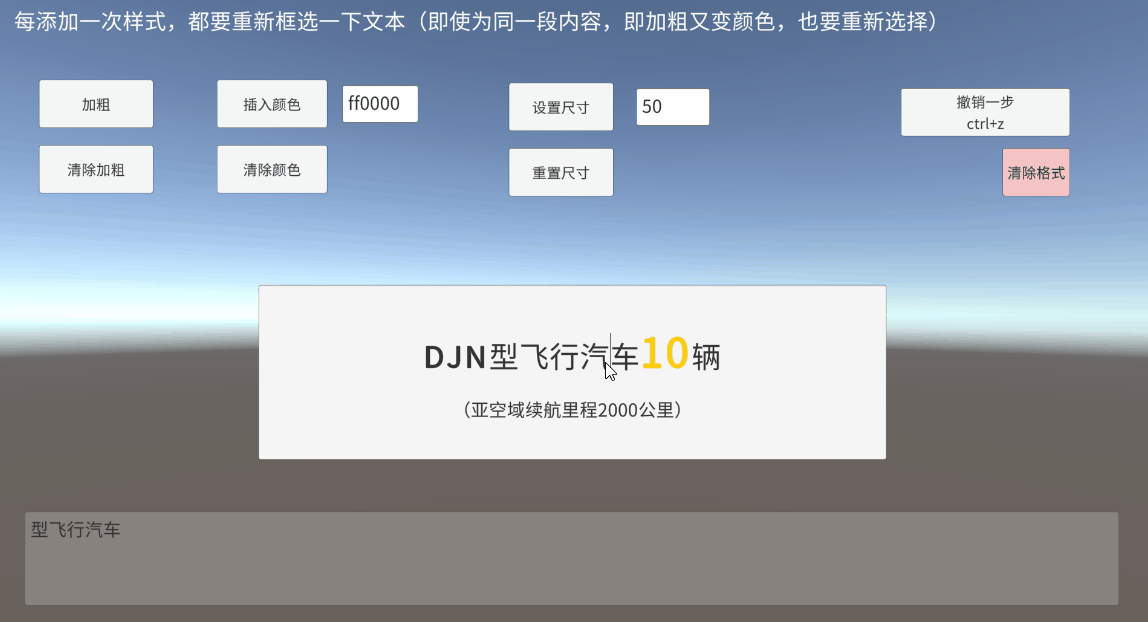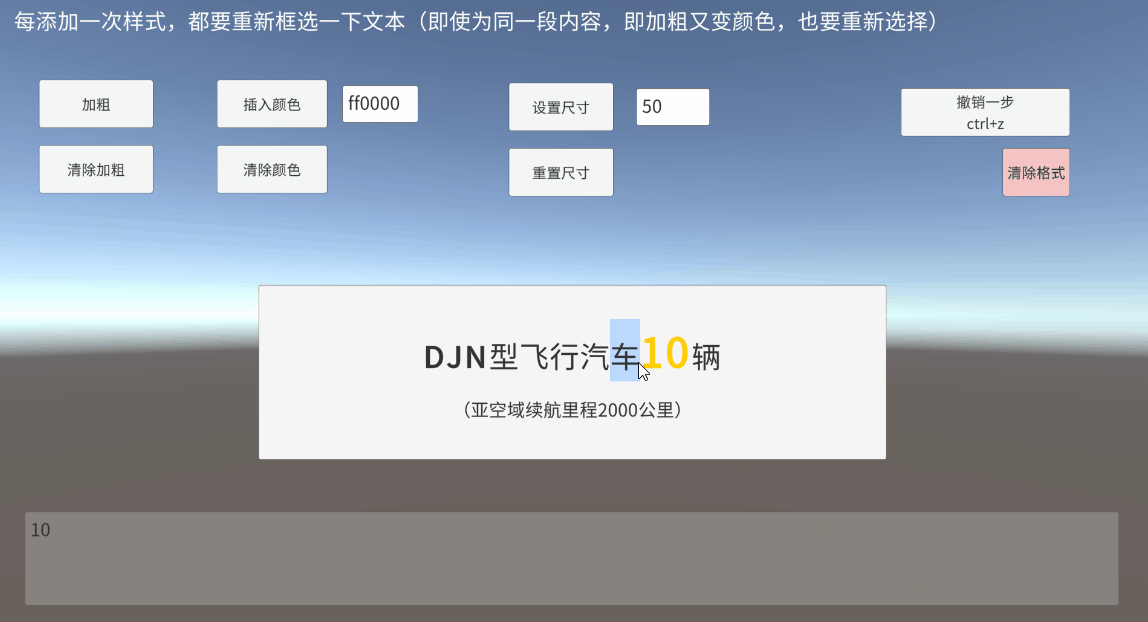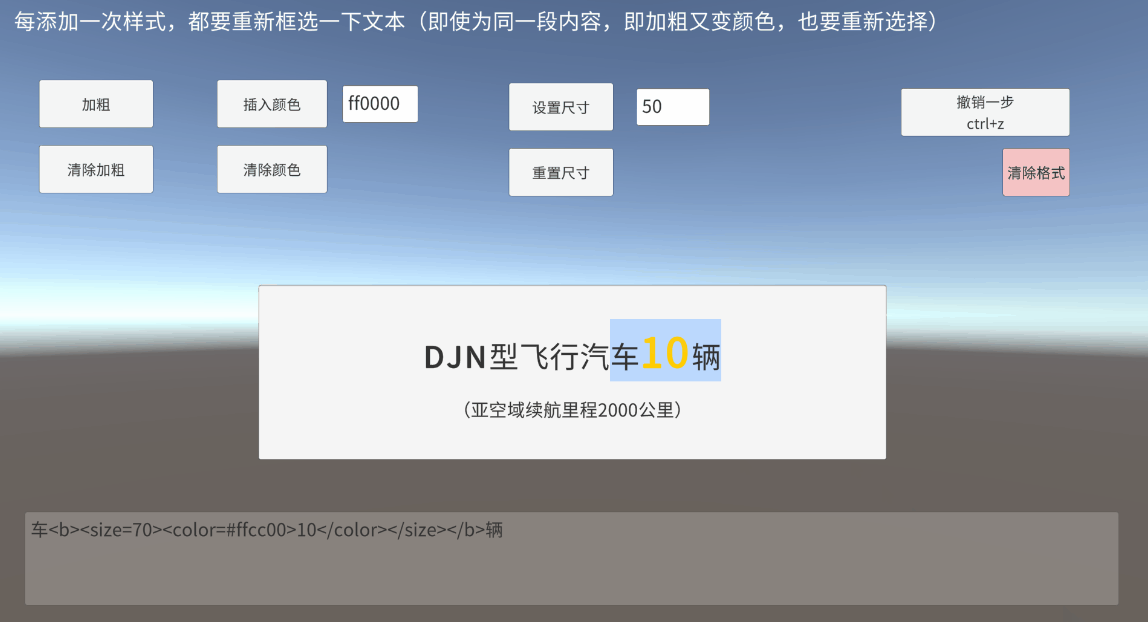
你想选择“没有下”,那么真实索引应该是,5和12,
那么根据实际索引,拆分后的字符串是这样“没有</b>下”
然而你再使用selectionAnchorPosition和selectionFocusPosition尝试获取时,依然得到的是2和4,
那么根据原索引,拆分后的字符串是这样“<b>”,就完全被富文本标签干扰了
截止目前还没有或者我没找到官方直接可以使用的,支持带有富文本标签的,框选或选中内容定位获取接口。因此只能自己计算
二、获取真实富文本标签定位的大致思路
为了获取真实定位,这里我们先不考虑框选,先只考虑一个字符的位置。
还是以今天<b>没有</b>下雨为例
我想获取“没”的真实定位,只需要在原索引加上其前面富文本标签“<b>”的长度即可
那么2就变成了5
进而扩展一下,今天<b><i><color=yellow>没有</color></i></b>下雨 ,对于这个文本
想获取“没”的真实定位,就需要将“没”前面所有富文本标签的长度都加上
那么写一个方法,去除目标索引前的第一个富文本标签,并记录去除后的字符串和被去除标签的字符数量,然后递归调用自己,直到没有富文本标签之后结束
计算框选时第二个字的定位时,也是同理(这里后面框选时,计算的调节稍有不同,下文讲)
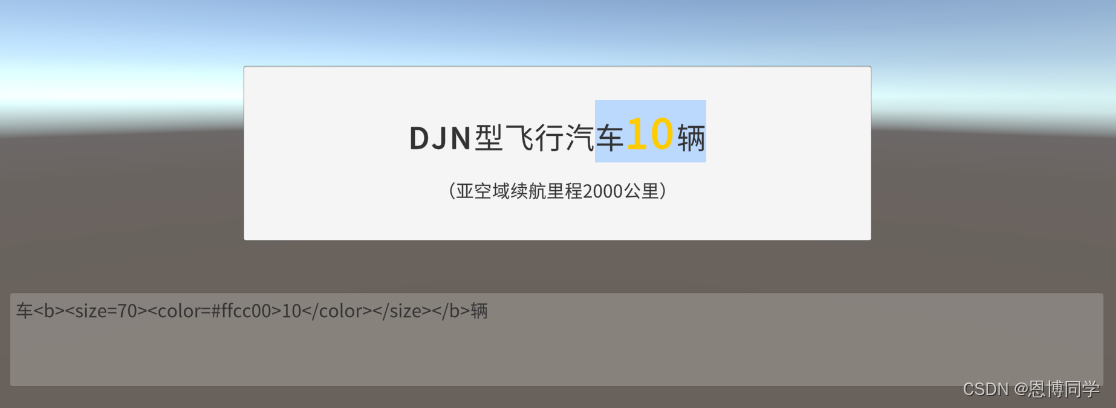
如果想要返回的内容中,不包含富文本标签,类似上图中的打印结果,只要“车10辆”三个字,那么使用一个正则字符串替换即可
//移除选定部分,所有富文本标签public string RemoveRichTextTags(string text) {return System.Text.RegularExpressions.Regex.Replace(text, "<.*?>", string.Empty);}三、代码实现
在unity创建RichTextTagHandler类
这里先假定,只有一个InputField被编辑,无切换
先创建一个全局变量,用来保存某次计算的真实索引
private int total = 0;创建RemoveFrontRichTag方法,用于移除,指定字符串,目标索引前,第一个富文本标签
/// <summary>
/// 从前往后,移除第一个富文本标签,计数标签字符数量,并将移除后的字符串返回
/// </summary>
/// <param name="aimString">待移除富文本标签的目标字符串</param>
/// <param name="surfaceIndex">原定位</param>
/// <param name="count">用来计数用的, 标记已经移除的富文本标签字符长度</param>
/// <returns>阶段性返回当前移除的富文本标签字符数量,递归后最终返回所有符合要求的富文本标签字符总数量</returns>
private string RemoveFrontRichTag(string aimString,int surfaceIndex, ref int count) {//先尝试定位'<'int meet = aimString.IndexOf('<');//如果定位不到,或者定位超过了原支付长度,说明标签在我们所选字符后面或者无富文本标签了,方法直接返回,并将数量count设置为0if (meet == -1 || meet > surfaceIndex) {count = 0;return aimString;}//成功定位到‘<’后,继续定位‘>’int leave = aimString.IndexOf('>');//将字符串拆分成去掉<>及其内部内容string newString = aimString.Substring(0, meet) + aimString.Substring(leave + 1, aimString.Length - leave - 1);//计算去掉部分的字符数量int length = leave - meet + 1;count += length;//Debug.Log(newString + " meet=" + meet + " leave=" + leave + " length=" + length);//把去掉已计数的标签后的字符串,返回return newString;
}创建TryGetRealIndex方法,用于递归调用,移除目标索引前的所有富文本标签
/// <summary>
/// 尝试获取真实索引,递归方法,
/// </summary>
/// <param name="richText"></param>
/// <param name="surfaceIndex"></param>
/// <param name="isEndPoint"></param>
/// <returns></returns>
private int TryGetRealIndex(string richText, int surfaceIndex,bool isEndPoint) {string newString = richText;int count = 0;//先尝试定位‘<’,并获取它的定位int mark = newString.IndexOf('<');//-1是没找到,没找到或大于,原本的定位,那么代表,原本定位之前已经没有'<'了,直接返回结束if ((isEndPoint && (mark == -1 || mark >= surfaceIndex)) || //如果是结尾的点,那么判断mark时添加等号,防止后侧遗留标签整体(!isEndPoint && (mark == -1 || mark > surfaceIndex))) {//如果不是结尾的点,那么判断mark时不加等号,判断前侧遗留标签整体return total;}//如果在原定位前,找到了'<',那么走一遍清除最前的富文本标签并计数的方法else {//清除一次标签,并将清除后的字符串保存newString = RemoveFrontRichTag(newString, surfaceIndex, ref count);//加入计数total += count;//回调,继续判断,原本定位前,是否有富文本标记TryGetRealIndex(newString, surfaceIndex, isEndPoint);}//递归完成后,返回最终的富文本标签字符总数return total;
}最后创建GetRealIndex,用于获取最终索引,并返回
/// <summary>
/// 获取选定部分,排除富文本标签后(富文本标签也算作数量),字符的真实位置
/// </summary>
/// <param name="inputField"></param>
/// <param name="surfaceIndex"></param>
/// <param name="isEndPoint">
/// 默认为false,从选定位置往前,所有富文本标签<>全部排除(通常为选定部分的“前面”点)
/// 传入true后,从选定位置开始,不仅往前,而且往后,所有富文本标签<>全部排除(通常为选定部分“后面”点)
/// 注意:选定时,从前往后选和从后往前选,“前面”和“后面”的点要判断一下
/// 扩展:如果“前面”点传入true,而“后面”点传入false,那么可以获取选定区域开始,前后所有的富文本标签都会被选定(默认是清除前后所有富文本标签)
/// </param>
/// <returns></returns>
public int GetRealIndex(TMP_InputField inputField, int surfaceIndex,bool isEndPoint=false) {//string richText = inputField.text;//所有,surfaceIndex前,富文本标签所占的字符总数int allRichTagCharCount = 0;total = 0;//每次开始前,重置total为0//递归获取富文本标签所占的字符总数allRichTagCharCount = TryGetRealIndex(richText, surfaceIndex,isEndPoint);//最终实际的定位是,富文本字符总数与surfaceIndex表定位的合return allRichTagCharCount + surfaceIndex;
}完整的脚本长这样
using System.Collections;
using System.Collections.Generic;
using System.Drawing;
using System.Linq;
using TMPro;
using UnityEngine;
using UnityEngine.UI;public class RichTextTagHandler {private int total = 0;/// <summary>/// 获取选定部分,排除富文本标签后(富文本标签也算作数量),字符的真实位置/// </summary>/// <param name="inputField"></param>/// <param name="surfaceIndex"></param>/// <param name="isEndPoint">/// 默认为false,从选定位置往前,所有富文本标签<>全部排除(通常为选定部分的“前面”点)/// 传入true后,从选定位置开始,不仅往前,而且往后,所有富文本标签<>全部排除(通常为选定部分“后面”点)/// 注意:选定时,从前往后选和从后往前选,“前面”和“后面”的点要判断一下/// 扩展:如果“前面”点传入true,而“后面”点传入false,那么可以获取选定区域开始,前后所有的富文本标签都会被选定(默认是清除前后所有富文本标签)/// </param>/// <returns></returns>public int GetRealIndex(TMP_InputField inputField, int surfaceIndex,bool isEndPoint=false) {//string richText = inputField.text;//所有,surfaceIndex前,富文本标签所占的字符总数int allRichTagCharCount = 0;total = 0;//每次开始前,重置total为0//递归获取富文本标签所占的字符总数allRichTagCharCount = TryGetRealIndex(richText, surfaceIndex,isEndPoint);//最终实际的定位是,富文本字符总数与surfaceIndex表定位的合return allRichTagCharCount + surfaceIndex;}/// <summary>/// 尝试获取真实索引,递归方法,/// </summary>/// <param name="richText"></param>/// <param name="surfaceIndex"></param>/// <param name="isEndPoint"></param>/// <returns></returns>private int TryGetRealIndex(string richText, int surfaceIndex,bool isEndPoint) {string newString = richText;int count = 0;//先尝试定位‘<’,并获取它的定位int mark = newString.IndexOf('<');//-1是没找到,没找到或大于,原本的定位,那么代表,原本定位之前已经没有'<'了,直接返回结束if ((isEndPoint && (mark == -1 || mark >= surfaceIndex)) || //如果是结尾的点,那么判断mark时添加等号,防止后侧遗留标签整体(!isEndPoint && (mark == -1 || mark > surfaceIndex))) {//如果不是结尾的点,那么判断mark时不加等号,判断前侧遗留标签整体return total;}//如果在原定位前,找到了'<',那么走一遍清除最前的富文本标签并计数的方法else {//清除一次标签,并将清除后的字符串保存newString = RemoveFrontRichTag(newString, surfaceIndex, ref count);//加入计数total += count;//回调,继续判断,原本定位前,是否有富文本标记TryGetRealIndex(newString, surfaceIndex, isEndPoint);}//递归完成后,返回最终的富文本标签字符总数return total;}/// <summary>/// 从前往后,移除第一个富文本标签,计数标签字符数量,并将移除后的字符串返回/// </summary>/// <param name="aimString">待移除富文本标签的目标字符串</param>/// <param name="surfaceIndex">原定位</param>/// <param name="count">用来计数用的, 标记已经移除的富文本标签字符长度</param>/// <returns>阶段性返回当前移除的富文本标签字符数量,递归后最终返回所有符合要求的富文本标签字符总数量</returns>private string RemoveFrontRichTag(string aimString,int surfaceIndex, ref int count) {//先尝试定位'<'int meet = aimString.IndexOf('<');//如果定位不到,或者定位超过了原支付长度,说明标签在我们所选字符后面或者无富文本标签了,方法直接返回,并将数量count设置为0if (meet == -1 || meet > surfaceIndex) {count = 0;return aimString;}//成功定位到‘<’后,继续定位‘>’int leave = aimString.IndexOf('>');//将字符串拆分成去掉<>及其内部内容string newString = aimString.Substring(0, meet) + aimString.Substring(leave + 1, aimString.Length - leave - 1);//计算去掉部分的字符数量int length = leave - meet + 1;count += length;//Debug.Log(newString + " meet=" + meet + " leave=" + leave + " length=" + length);//把去掉已计数的标签后的字符串,返回return newString;}#region Utility//移除选定部分,所有富文本标签public string RemoveRichTextTags(string text) {return System.Text.RegularExpressions.Regex.Replace(text, "<.*?>", string.Empty);}//移除选定部分,所有颜色标签public string RemoveRichTextTags_color(string text) {return System.Text.RegularExpressions.Regex.Replace(text, "<color=.*?>|</color>", string.Empty);}//移除选定部分,所有加粗标签public string RemoveRichTextTags_B(string text) {return System.Text.RegularExpressions.Regex.Replace(text, "<b>|</b>", string.Empty);}//移除选定部分,所有Size标签public string RemoveRichTextTags_Size(string text) {return System.Text.RegularExpressions.Regex.Replace(text, "<size=.*?>|</size>", string.Empty);}#endregion
}
使用时,类似这样
private void Update() {if (Input.GetMouseButtonUp(0)) {OnMouseUpFromIpf();}}#region 主要代码private void OnMouseUpFromIpf() {if (EventSystem.current.currentSelectedGameObject == ipf.gameObject) {int startPos = ipf.selectionAnchorPosition;//起始选择的位置int endPos = ipf.selectionFocusPosition;//结束时的位置if (startPos == endPos) return;//如果起始结束相等,那么相当于就点了一下,没选择内容string selectedStr = "";if (startPos < endPos) {//正常从前往后选的情况// 获取可见文本的起始位置,从选定Index开始,排除前面所有富文本标签currentInsideBeginIndex = handler.GetRealIndex(ipf, startPos);//获取可见文本的结束位置,从选定Index开始,后面的所有富文本标签,也要排除currentInsideEndIndex = handler.GetRealIndex(ipf, endPos, true);//此处传入true,即可以排除index后面的所有富文本标签}else if (startPos > endPos) {//从后往前选的情况currentInsideBeginIndex = handler.GetRealIndex(ipf, endPos);//反选,endPos是“前面的点”currentInsideEndIndex = handler.GetRealIndex(ipf, startPos, true);//反选,startPos是“后面的点”}//获取选定部分的字符串,排除选定区域开始,前后所有的富文本标签//注意:如果需要,以选定区域为基准,获取区域前后部分的所有富文本标签(而不是排除),那么需要将BeginIndex的GetRealIndex中IsEndPoint传入true,而EndIndex的GetRealIndex中IsEndPoint传入false//类似一个加粗区域,<b>A</b>,目前选定A,那么获取到的是“A”,若是以下面的写法反向设置IsEndPoint,那么获取到的是“<b>A</b>”。后面这么获取,可以方便对标签进行判断和修改selectedStr = ipf.text.Substring(currentInsideBeginIndex, currentInsideEndIndex - currentInsideBeginIndex);Debug.Log(currentInsideBeginIndex + " " + currentInsideEndIndex + " " + selectedStr+" "+startPos+" "+endPos);ipf_console.text = selectedStr;}
}演示
其他扩展功能,只需要对字符串进行编辑即可