郑州做网站优化运营商最简短的培训心得
一. 为什么要使用Mybatis?
1.1 jdbc的使用步骤
首先,在pox.xml中引入MySQl驱动的依赖
第一步, Class.forName 注册驱动
第二步,获取一个Connection。
第三步,创建一个Statement对象。
第四步,execute()方法执行SQL。execute()方法返回一个ResultSet结果集。
第五步,通过ResultSet获取数据,给POJO的属性赋值。
最后,关闭数据库相关的资源,包括ResultSet,Statement,Connection
1.2 jdbc使用存在哪些问题?
重复代码
资源管理
结果集处理
SQL耦合(处理业务逻辑和处理数据的代码是耦合在一起的)
1.3 jdbc问题的解决
Apache在2003年Commons DbUtils工具类,简化对数据库的操作。
DbUtils提供了一个QueryRunner类,它对数据库的增删改查的方法进行了封装。

private static QueryRunner queryRunner;
在QueryRunner的构造函数里面,可以传入一个数据源,比如这里用Hikari,这样我们就不需要再去写各种创建和释放连接的代码了。
queryRunner = new QueryRunner(dataSource);
通过这个工具类,提供获取QueryRunner实例的方法。
方法封装解决了重复代码的问题,出入数据源解决了资源管理的问题。
怎么把结果集转换为对象呢?比如转换成POJO或者List或者Map? 肯定不能一个属性去set或者put .
我希望做到的是,只要指定一个类型,它就可以自动把结果集给我转换为这种类型。
为了避免给每种类型创建要给自动转换类,在DbUtils里面提供了一系列的支持泛型的ResultSetHandleer,比如:用来把结果集转换为JavaBean的,转换为List的,转换为Map的 等等。
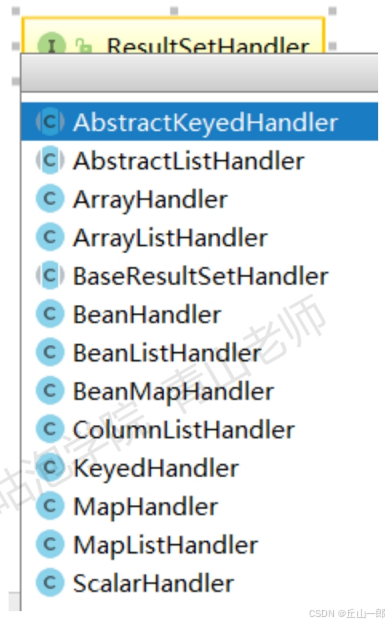
只要在DAO层调用QueryRunner封装好的查询方法,传入一个指定了类型的Handler,它就可以自动把结果集转换为实体类Bean或者List或者Map。
com.gupaoedu.dbutils.dao.BlogDao.java
比如:传入一个BeanHandler或者BeanListHandler;

com.gupaoedu.dbutils.QueryRunnerTest测试一下,结果:
BlogDto{bid=3,name=‘丘山一郎’,quthorId=‘null’}
实现的原理
return rs.next()?this.convert.toBean(rs,this.type):null;
最后到了populateBean():
通过for循环,把rs的值填充到了指定的类型属性中。
输出的结果中,authorId为什么是空的?
这种自动映射,要求数据库的字段跟对象的属性名称完全一致,才可以实现自动映射。


spring-jdbc
除了DbUtils之外,Spring也对原生的JDBC进行了封装。
1.代码重复——Spring提供了一个模板方法JdbcTemplate,里边封装了各种各样的execute,query,和update方法。
JDBCTemplate这个类(类的注释)
它是JDBC的核心包装类。简化了JDBC的使用,可以避免常见的异常。它封装了JDBC的核心流程,应用只要提供SQL,提取结果集就可以了。它是线程安全的。
初始化的时候可以设置数据源,所以资源管理的问题也可以解决。
public JdbcTemplate(DataSource dataSource){setDataSource(dataSource);afterPropertiesSet();
}
对于结果集的处理,Spring JDBC提供了一个RowMapper接口,可以把结果集转换为Java对象,它作为JdbcTemplate的参数使用。
比如:要把查询tbl_emp表得到的结果集转换为Employee对象,就可以针对一个Employee创建一个RowMapper对象,实现RowMapper接口,并且重写mapRow()方法。在mapRow()方法里面完成对结果集的处理。






DbUtils 和 Spring JDBC ,这两个对JDBC做了轻量级封装的框架,或者说 工具类里边,帮我们解决的问题:


ORM关系型数据库
什么是ORM?为什么叫ORM?
ORM的全称是Object Relaional Mapping,也就是对象与关系的映射,对象是程序里边的对象,关系是它与数据库里面的数据的关系。也就是说,ORM框架帮助我们解决的问题是程序对象和关系型数据库的相互映射的问题。
Hibernate是要给很流行的ORM框架,2001年的时候就出了第一个版本。在使用Hibernate的时候,我们需要为实体类建立一些hbm的xml映射文件。
然后通过Hibernate提供(session)的增删改查的方法来操作对象。
Session相关方法也可以通过继承JpaRepository活得,无需手动创建。

操作对象根操作数据库的数据一样。Hibernate的框架内会自动帮我们生成SQL语句(可以屏蔽数据库差异),自动进行映射。这样我们呢的代码变得简洁了,程序的可读性也提高了。
总结Hibernate的特性:
1,根据数据方言自动生成SQL,移植性好;
2,自动管理理解资源(支持数据源);
3,实现了对象和关系型数据库的完全映射,操作对象就像操作数据库记录一样;
4,提供了缓存功能机制。
存在的问题:
但是Hibernate在业务复杂的项目中使用也存在一些问题:
1,比如使用get(),update(),save()对象的这种方式,实际操作的是所有字段,没有办法指定部分字段,换句话说就是不够灵活。
2,自动生成SQL的方式,如果要基于SQL去做一些优化的话,是非常困难的,也就是说可能出现性能的问题。
3,不支持动态SQL,比如分表中的表名,条件,参数变化等,无法根据条件自动生成SQL。
因此我们需要一个更加灵活的框架。
Mybatis的核心特性解决了那些问题?
- 使用连接池对连接进行管理
- SQL和代码分离,集中管理
- 结果集映射
- 参数映射和动态SQL
- 重复SQL的提取
- 缓存管理
- 插件机制
Mybatis核心组件及其生命周期





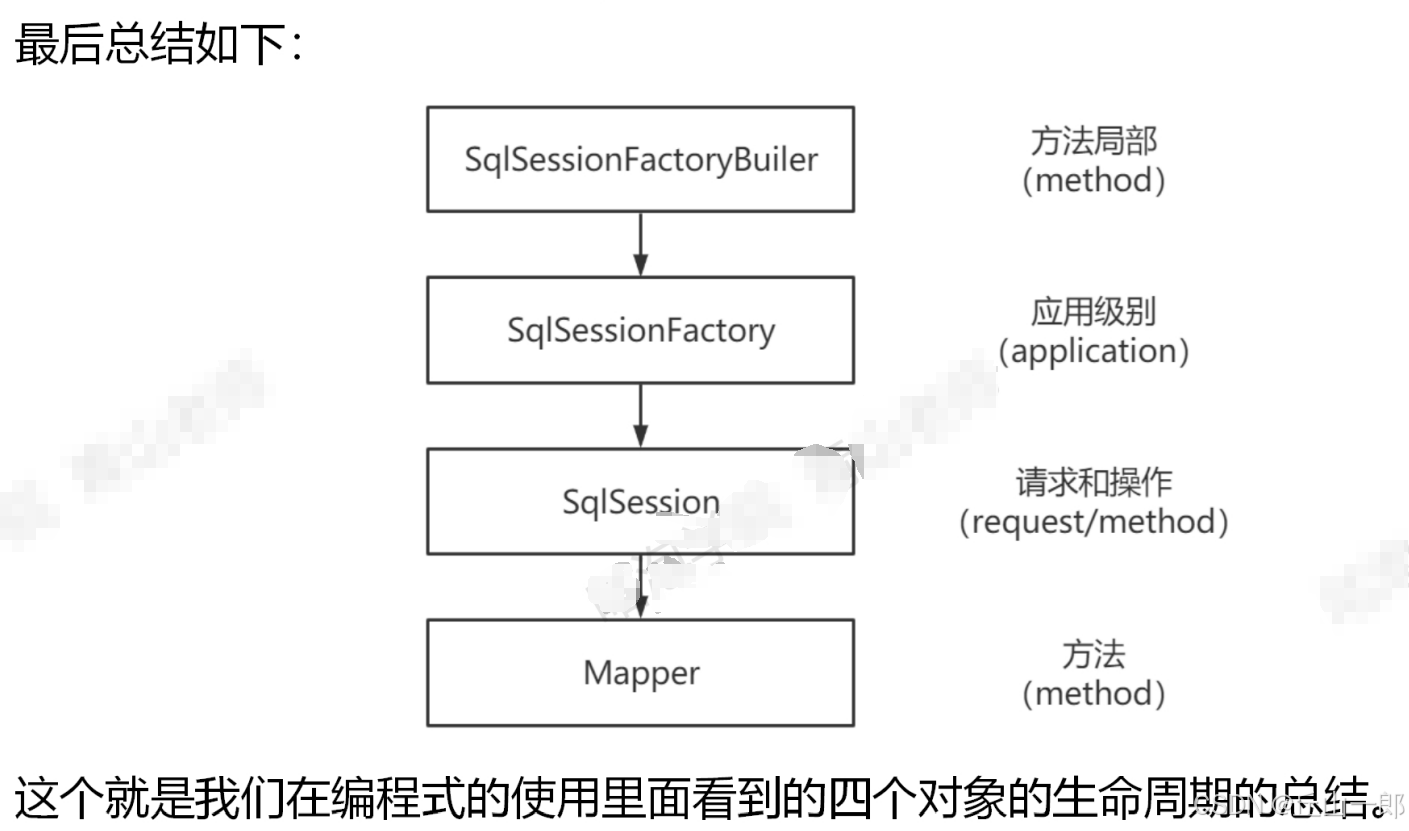
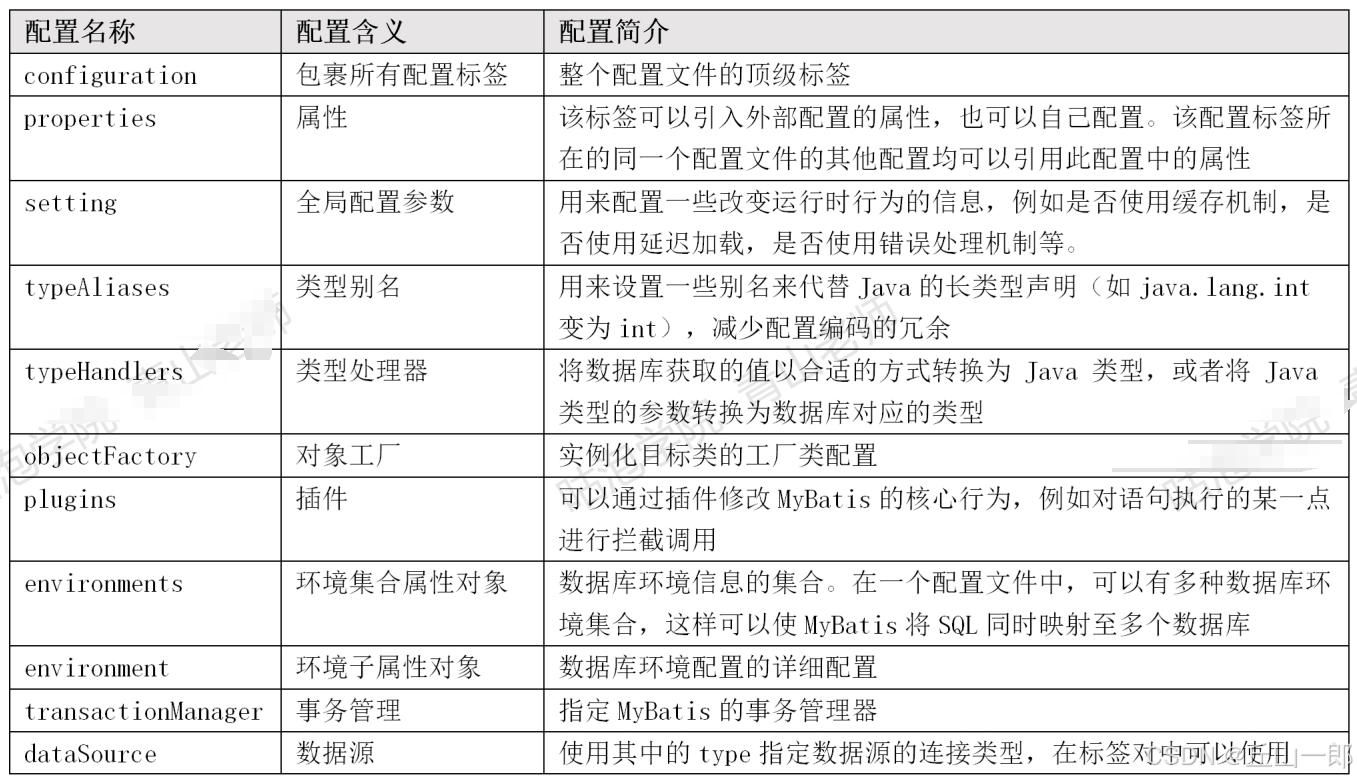
核心配置:
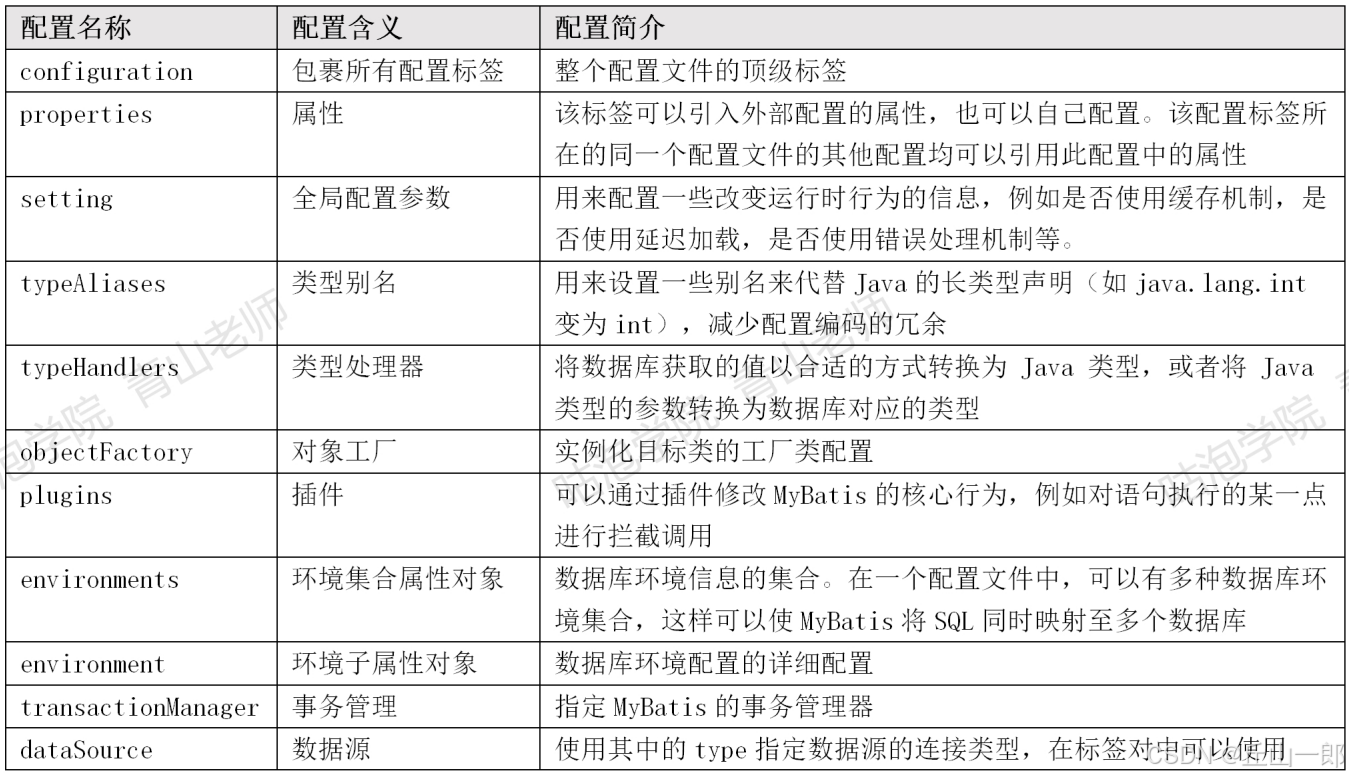

特殊的类型:typeHandlers






objectFactory
当我们把数据库返回的结果集转换为实体类的时候,需要创建对象的实例,由于我们不知道需要处理的类型是什么,右哪些属性,所以不能用new的方式去创建。只能通过反射来创建。

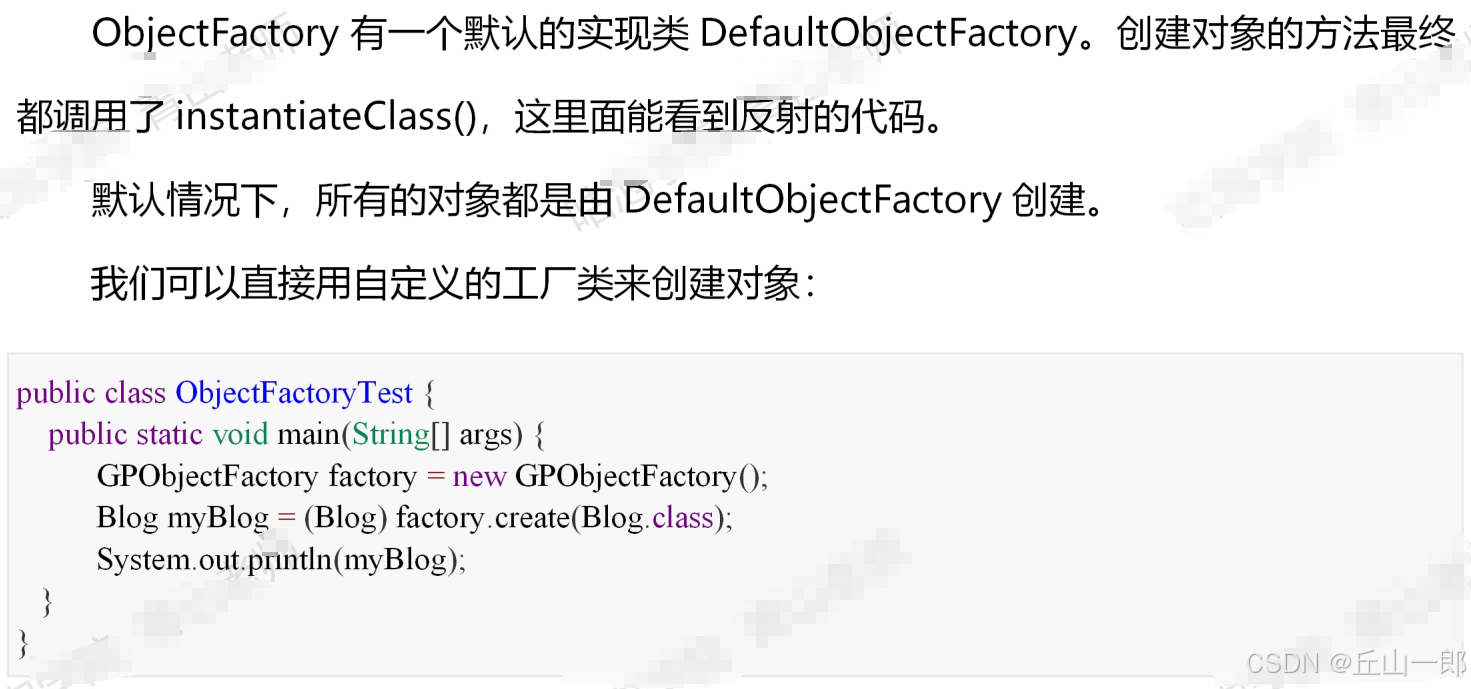
如果想要修改对象工厂在初始化实体类的时候的行为,就可以通过创建自己的对象工厂,继承DefaultObjectFactory来实现(不再需要实现ObjectFactory接口)。
例如:






plugins

二.