浙江省城乡和建设厅网站网络整合营销策划书
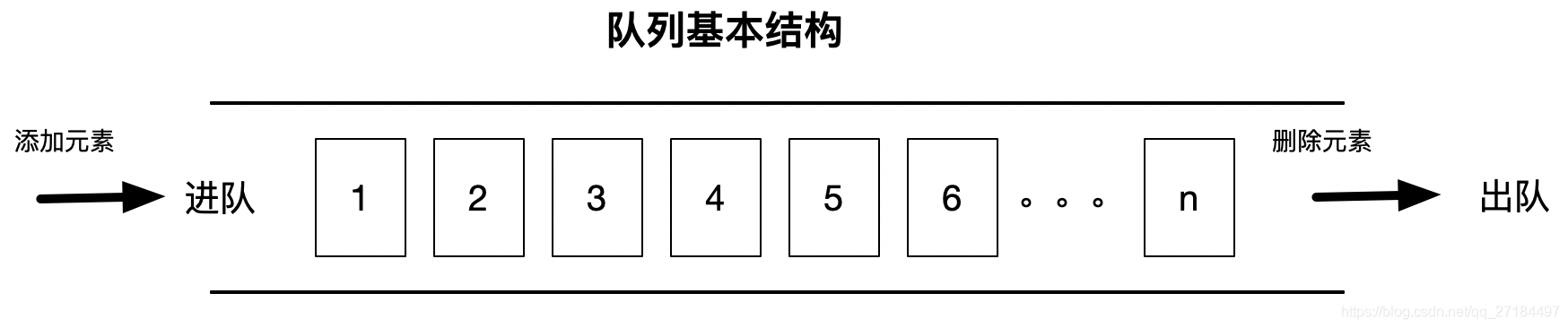
一、队列简介
队列是一种特殊的线性表,遵循先入先出、后入后出(FIFO)的基本原则,一般来说,它只允许在表的前端进行删除操作,而在表的后端进行插入操作,但是java的某些队列运行在任何地方插入删除;比如我们常用的 LinkedList 集合,它实现了Queue 接口,因此,我们可以理解为 LinkedList 就是一个队列;
二、Java队列分类
Java中队列主要分为阻塞和非阻塞,有界和无界、单向链表和双向链表之分;
2.1、阻塞和非阻塞
-
阻塞队列
入列(添加元素)时,如果元素数量超过队列总数,会进行等待(阻塞),待队列的中的元素出列后,元素数量未超过队列总数时,就会解除阻塞状态,进而可以继续入列;
出列(删除元素)时,如果队列为空的情况下,也会进行等待(阻塞),待队列有值的时候即会解除阻塞状态,进而继续出列;
阻塞队列的好处是可以防止队列容器溢出;只要满了就会进行阻塞等待;也就不存在溢出的情况;
只要是阻塞队列,都是线程安全的;;
-
非阻塞队列
不管出列还是入列,都不会进行阻塞
入列时,如果元素数量超过队列总数,则会抛出异常,
出列时,如果队列为空,则取出空值;
一般情况下,非阻塞式队列使用的比较少,一般都用阻塞式的对象比较多;阻塞和非阻塞队列在使用上的最大区别就是阻塞队列提供了以下2个方法:
-
出队阻塞方法 : take()
-
入队阻塞方法 : put()
2.2、有界和无界
-
有界:有界限,大小长度受限制
-
无界:无限大小,其实说是无限大小,其实是有界限的,只不过超过界限时就会进行扩容,就行ArrayList 一样,在内部动态扩容
2.3、单向链表和双向链表
单向链表 : 每个元素中除了元素本身之外,还存储一个指针,这个指针指向下一个元素;
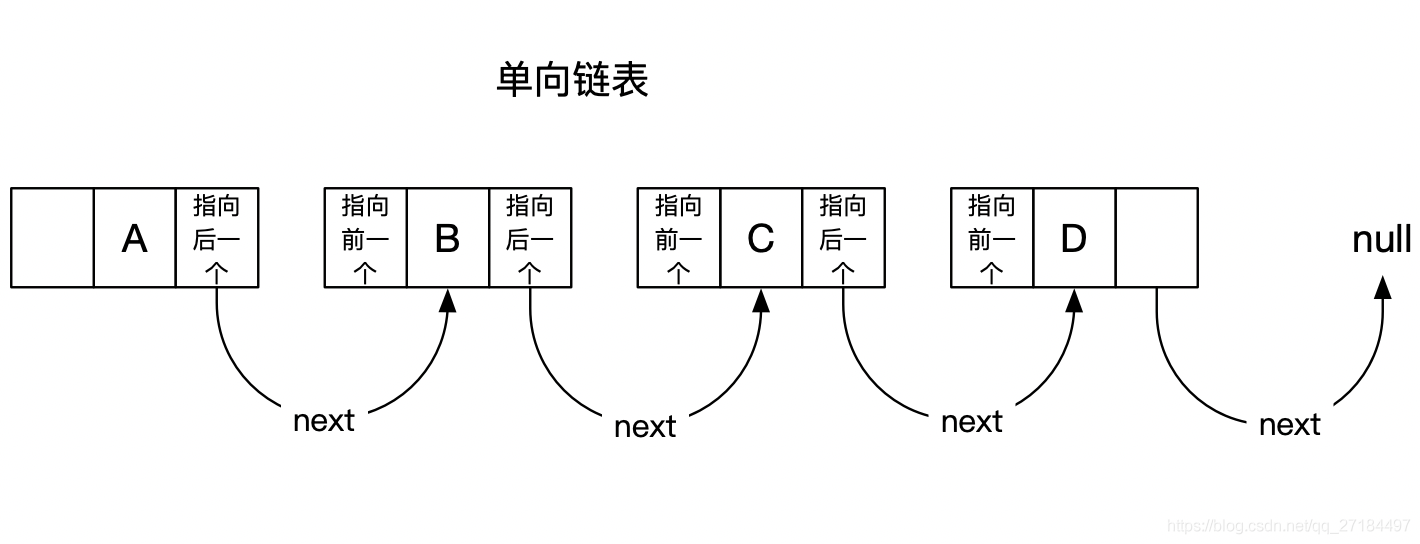
双向链表 :除了元素本身之外,还有两个指针,一个指针指向前一个元素的地址,另一个指针指向后一个元素的地址;

三、Java内置队列
3.1、Java 队列接口继承图

3.2、常见的Java线程安全的内置队列
| 队列 | 有界性 | 锁 | 数据结构 | 队列类型 |
|---|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加锁(ReentrantLock,读写同一把锁) | arraylist(数组) | 阻塞 |
| LinkedBlockingQueue | 可选 | 加锁(ReentrantLock,读写各自一把锁) | linkedlist(链表) | 阻塞 |
| ConcurrentLinkedQueue | 无界 | 无锁(CAS) | linkedlist(链表) | 非阻塞 |
| LinkedTransferQueue | 无界 | 无锁(CAS) | linkedlist(链表) | 阻塞 |
| PriorityBlockingQueue | 无界 | 加锁(ReentrantLock,读写同一把锁) | heap(堆) | 阻塞 |
| DelayQueue | 无界 | 加锁(ReentrantLock,读写同一把锁) | heap(堆) | 阻塞 |
-
ArrayBlockingQueue
一个用数组实现的有界阻塞队列,初始化时必须指定队列大小。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下采用非公平锁的方式实现,可以通过构造器传参控制是采用公平锁还是非公平锁实现
-
LinkedBlockingQueue
一个由链表结构组成的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序
-
LinkedTransferQueue
一个由链表结构组成的无界阻塞队列 -
ConcurrentLinkedQueue
一个通过CAS实现的线程安全的无界非阻塞队列
-
PriorityBlockingQueue
一个带优先级的无界队列,而不是先进先出队列。元素按优先级顺序被移除,而且它也是无界的,也就是没有容量上限,虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError 错误; -
DelayQueue
一个通过PriorityBlockingQueue实现延迟获取元素的无界队列无界阻塞队列,其中添加进该队列的元素必须实现Delayed接口(指定延迟时间),而且只有在延迟期满后才能从中提取元素。
如果要 实现 一个 线程安全的队列,有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法。
使用阻塞算法的队列可以用一个 锁 (入队和出队用同一把锁,ArrayBlockingQueue )或两个锁 (入队和出队 用不同的锁 ,LinkedBlockingQueue)等方式来 实现 。
非阻塞的实现 方式则 可以使用循环CAS 的方式来实现(ConcurrentLinkedQueue 。
3.3、队列常用方法
-
add:增加一个元索 如果队列已满,则抛出一个IIIegaISlabEepeplian异常
-
remove:移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
-
element:返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
-
offer:添加一个元素并返回true 如果队列已满,则返回false
-
poll:移除并返问队列头部的元素 如果队列为空,则返回null
-
peek:返回队列头部的元素 如果队列为空,则返回null
-
put:添加一个元素 如果队列满,则阻塞
-
take:移除并返回队列头部的元素 如果队列为空,则阻塞
-
drainTo(list):一次性取出队列所有元素
知识点: remove、element、offer 、poll、peek 其实是属于Queue接口。
四、高性能队列Disruptor
4.1、Disruptor简介
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题。与Kafka、RabbitMQ用于服务间的消息队列不同,disruptor一般用于线程间消息的传递。基于Disruptor开发的系统单线程能支撑每秒600万订单。 disruptor适用于多个线程之间的消息队列,作用与ArrayBlockingQueue有相似之处,但是disruptor从功能、性能都远好于ArrayBlockingQueue,当多个线程之间传递大量数据或对性能要求较高时,可以考虑使用disruptor作为ArrayBlockingQueue的替代者。 官方也对disruptor和ArrayBlockingQueue的性能在不同的应用场景下做了对比,目测性能只有有5~10倍左右的提升。
目前,包括Apache Storm、Camel、Log4j2等等知名的框架都在内部集成了Disruptor用来替代jdk的队列,以此来获得高性能。
Disruptor使用观察者模式, 主动将消息发送给消费者, 而不是等消费者从队列中取; 在无锁的情况下, 实现queue(环形, RingBuffer)的并发操作, 性能远高于BlockingQueue。
4.2、高性能原理
Disruptor为什么性能这么好呢,主要依赖于以下四个特性
无锁设计:CAS
采用CAS无锁方式,保证线程的安全性。多线程环境下,多个生产者通过do/while循环的条件CAS,来判断每次申请的空间是否已经被其他生产者占据。假如已经被占据,该函数会返回失败,While循环重新执行,申请写入空间。如果申请到之后,直接在该位置写入或者读取数据。
ArrayBlockingQueue用了重量级lock锁,在我们加锁过程中我们会把锁挂起,解锁后,又会把线程恢复,这一过程会有一定的开销,并且我们一旦没有获取锁,这个线程就只能一直等待,这个线程什么事也不能做。
CAS 更多知识见 Java 锁
RingBuffer : 环形数组
引入环形的数组结构:这种固定大小的环形队列的另外一个好处就是可以做到完全的内存复用。在系统的运行过程中,不会有新的空间需要分配或者老的空间需要回收,大大减少系统分配空间及回收空间的额外开销,避免频繁的GC;同时,数组对处理器的缓存机制更加友好。
[图片上传失败...(image-1650c4-1677132259413)]
-
元素位置的定位:
数组长度强制要求一定是 2^n ,这样可以通过位运算,加快定位的速度。通过sequence &(queueSize-1)就能立即定位到实际的元素位置index,这比取余(%)操作快得多(hashMap定位也是采用这种方式)。
下标采取递增的形式,不用担心index溢出的问题,index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
-
消除伪共享 : 通过添加额外的无用信息,避免伪共享问题
当CPU访问某一个变量时候,首先会去看CPU Cache内是否有该变量,如果有则直接从中获取,否者就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存拷贝到Cache(cache行是Cache与主内存进行数据交换的单位)。
由于存放到Cache行的的是内存块而不是单个变量,所以可能会把多个变量存放到了一个cache行。当多个线程同时修改一个缓存行里面的多个变量时候,由于同时只能有一个线程操作缓存行,所以相比每个变量放到一个缓存行性能会有所下降,这就是伪共享。
总之伪共享的产生是因为多个变量被放入了一个缓存行,并且多个线程同时去写入缓存行中不同变量,解决伪共享最直接的方法就是填充,通过添加额外的无用信息,避免伪共享问题。
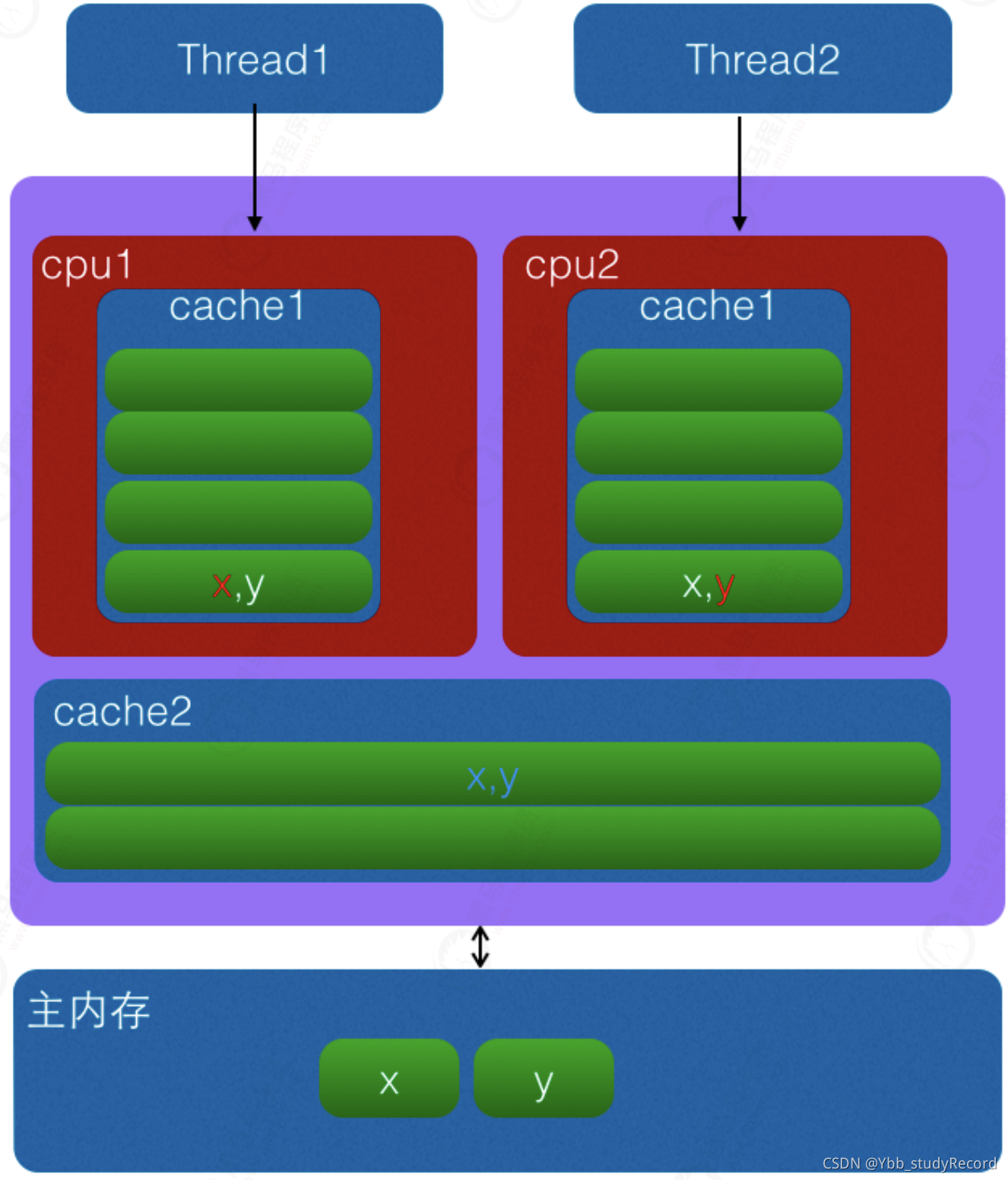
如上图变量x,y同时被放到了CPU的一级和二级缓存,当线程1使用CPU1对变量x进行更新时候,首先会修改cpu1的一级缓存变量x所在缓存行,这时候缓存一致性协议会导致cpu2中变量x对应的缓存行失效,那么线程2写入变量x的时候就只能去二级缓存去查找,这就破坏了一级缓存,而一级缓存比二级缓存更快。更坏的情况下如果cpu只有一级缓存,那么会导致频繁的直接访问主内存。我们的缓存都是以缓存行作为一个单位来处理的,所以失效x的缓存的同时,也会把y失效,反之亦然。
4.3、Disruptor应用场景
参考使用到disruptor的一些框架.
- log4j2
Log4j 2相对于Log4j 1最大的优势在于多线程并发场景下性能更优。该特性源自于Log4j 2的异步模式采用了Disruptor来处理。
-
Jstorm 在流处理中不同线程中数据交换,数据计算可能蛮多内存中计算, 流计算快进快出,disruptor应该不错的选择。
-
百度uid-generator 部分使用ring buffer和去伪共享等思路缓存已生成的uid,也部分参考了disruptor
经过测试,Disruptor的速度比LinkedBlockingQueue提高了七倍。所以,当你在使用LinkedBlockingQueue出现性能瓶颈的时候,你就可以考虑采用Disruptor的代替。