怎么对网站做seo优化外贸平台
我们在写sql的时候经常发现读取数据不多,但是代码运行时间异常长的情况,这通常是发生了数据倾斜现象。数据倾斜现象本质上是因为数据中的key分布不均匀,大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,从而拉慢了整个计算过程速度。
本文将介绍如何通过日志分析,判断数据中的哪个key分布不均,从而导致了数据倾斜问题。
任务是否发生了倾斜
hive判断

hive运行日志
当我们在hive作业运行日志中,发现reduce任务长时间卡在99%时,即可判断任务发生了数据倾斜。
其原理是这样的:

分布式处理逻辑
分布式处理实际上是按数据中的key将数据分摊到多个机器上运行,假如出现了数据倾斜问题,如上图。可以想象,当1min过去后,我们的任务完成率只有67%,并且在接下来的9min时间内,任务完成率将持续卡在67%上。因此,当我们发现任务完成率长时间卡在99%时,即判断发生了数据倾斜。
spark判断

spark UI界面
我们进入spark UI界面,发现第2个job的运行时间长达1.8h,而其他job运行时间不超过2min,判断该job有可能发生数据倾斜。

进一步分析job,可以看到该job只存在一个stage(9)

stage界面
进一步分析stage,发现不管是duration还是shuffle的数据量,max和median都有明显的差距,可以肯定是job(5)的stage(9)发生倾斜。
hive输出也可以帮助排查
hive数据倾斜表象:Table 0 has 10000 rows for join key [0,0]
有hive任务发生数据倾斜,reduce端一直99%,有一个reduce任务卡主了。
打开这个reduce任务的log日志,发现如下日志:
[INFO] org.apache.hadoop.hive.ql.exec.JoinOperator: Table 0 has 10000 rows for join key [0,0]
打开hive源码定为输入日志行:
if (sz == nextSz) {LOG.info("Table {} has {} rows for join key {}", alias, sz, keyObject);nextSz = getNextSize(nextSz);
}
输出的类是org.apache.hadoop.hive.ql.exec.JoinOperator,是hive中join运算符的实现类,具体运行机制尚不清楚。
查询资料得知,当一个key关联了超过1000行时,会输出一条该警告日志,此后每1000会输出一条。所以这条日志的目的在于警告可能存在的Join数据倾斜的风险。
寻找倾斜key
当我们发现任务倾斜了,自然而然就希望找到倾斜的key,从而修复数据倾斜的现象。当然,这部分我也会分为hive和spark两个部分进行介绍。
hive识别
step1:确认是哪个Job出现了严重的倾斜问题

hive运行日志
通过搜索tracking的方式,我们发现第3个job的reduce任务一直卡在99%上,判断其发生了倾斜问题。
step2:进入相应的Tracking URL,查看SUCCESSFUL REDUCE

很明显,其他的taske都在2min之内完成,只有000000_1需要耗费1个多小时的时间完成。
另外注意,这里面需要排除一种特殊情况。有时候,某个task执行的节点可能有问题,导致任务跑的特别慢。这个时候,mapreduce的推测执行,会重启一个任务。如果新的任务在很短时间内能完成,通常则是由于task执行节点问题导致的个别task慢。如果推测执行后的task执行任务也特别慢,那更能说明该task可能会有倾斜问题。
step3:进入log日志,查看syslog

hive的syslog日志
可以从log日志中看到,该job仅仅运行了file和group操作后,就将数据写入至hive表中。那么,我们可以确认的是,该job运行的是最后一个group by操作。
step4:对照运行sql

运行sql
我们可以看到,在group by阶段,count(distinct)的出现造成了数据倾斜。
spark识别
step1:找到该任务运行的stage

spark UI界面
我们看到该运行任务,可以发现第2个job运行时间长达1.8h,远大于其他job,可以判定倾斜发生在job(5)。
step2:点击SQL,查看Details for Query

Details for Query
可以从sort time total/peak memory total/spill size total看出来,左表的package_name分布不均匀,此时可以通过查看scan parquet了解具体是哪张表。
step3:对照运行sql

运行sql代码
查询package_name的分布情况
select package_name,count(1) as cnt from test1 where date=20220619 group by package_name order by cnt desc limit 10;
package_name的分布验证了我们的猜想,test1.package_name造成了数据倾斜
过滤掉倾斜数据
当少量key重复次数特别多,如果这种key不是业务需要的key,可以直接过滤掉。
比如一张埋点日志表ods.page_event_log,
需要和订单表dw.order_info_fact做join关联。
在执行Hive的过程中发现任务卡在map 100%、reduce 99%,最后的1%一直运行不完。考虑应该是在join的过程中出现了数据倾斜,下面进行排查。
对于ods.page_event_log表查看出现次数最多的key:
select cookieid,count(*) as numfrom ods.page_event_logwhere data_date = "20190101"
group by cookieid
distribute by cookieid
sort by num desc limit 10
同样的,对另一张join表也做对应的排查
select cookieid,count(*) as num
from dw.order_info_fact
group by cookieid
distribute by cookieid
sort by num desc limit 10
从sql统计的结果可以看出,日志表和订单表通过cookieid进行join,当cookieid为0的时候,join操作将会产生142286×142286条数据,数量如此庞大的节点系统无法处理过来。同样当cookieid为NULL值和空值时也会出现这种情况,而且cookieid为这3个值时并没有实际的业务意义。因此在对两个表做关联时,排除掉这3个值以后,就可以很快计算出结果了,所以做好前期的数据清洗对一个大数据平台是至关重要的,生产无小事。
引入随机数
当我们用sql对数据group by时,MR会将相同的key拉取到同一个节点上进行聚合,如果某组的数据量很大时,会出现当前节点任务负载过重,从而导致数据倾斜。这时候可以考虑引入随机数,将原来的一个key值拆分成多组进行聚合。
比如现在需要统计用户的订单量,sql如下:
select t1.user_id,t2.order_numfrom (select user_idfrom dim.user_info_fact # 用户维度表where data_date = "20190101" and user_status_id=1) t1 join ( select user_id,count(*) as order_num from dw.dw_order_fact # 订单表where site_id in (600, 900)and order_status_id in(1,2,3)group by user_id) t2 on t1.user_id = t2.user_id其中,用户维度表有2000w条数据,订单表有10亿条数据,任务在未优化前跑了一小时还没跑完,怀疑出现了数据倾斜。这里可以把key值加上一定的前缀转换成多个key,这样原本一个task上处理的key就会分发到其他多个task,然后去掉前缀再进行一次聚合得到最终结果。
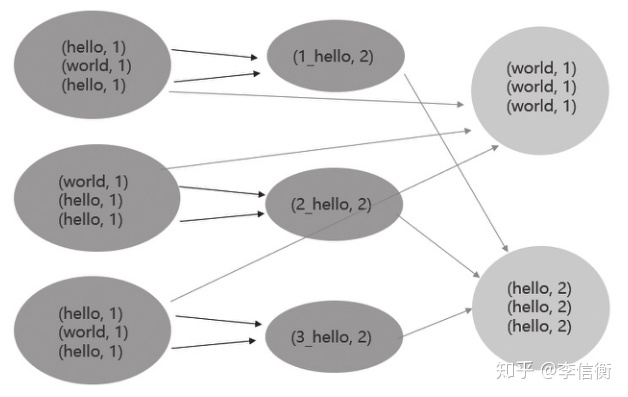
优化后的sql如下: 这里把原来可能1个task执行的任务并行成了1000个随机数task做聚合,再把聚合的结果通过user_id做sum,在集群的整体性能不受影响的情况下,可以有效提高整体的计算速度。
select t1.user_id,t2.order_numfrom (select user_idfrom dim_user_info_factwhere data_date = "20190101" ) t1 join ( select t.user_id,sum(t.order_num) as order_numfrom (select user_id,round(rand()*1000) as rnd,count(1) as order_num from dw.order_info_factwhere pay_status in (1,3)group by user_id,round(rand()*1000)) t group by t.user_id) t2 on t1.user_id = t2.user_id还有一种可能
可能仅仅是因为你给的资源太少了 ,适当增加map和reduce的内存和个数,以及小文件合并之类的