做网站工作描述百度识图官网
项目主页:https://github.com/QwenLM/Qwen-VL
通义前问网页在线使用——(文本问答,图片理解,文档解析):https://tongyi.aliyun.com/qianwen/
论文v3. : 一个全能的视觉语言模型
23.10 Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
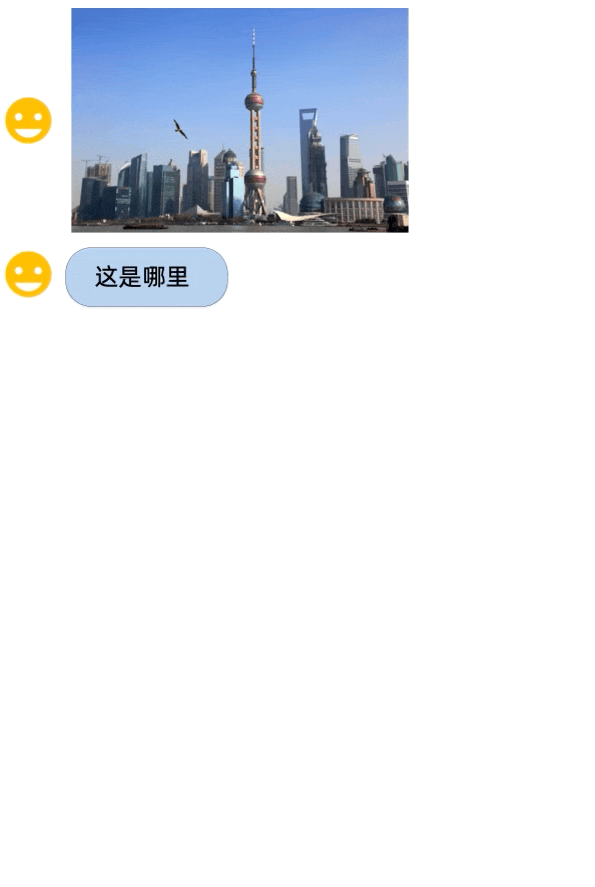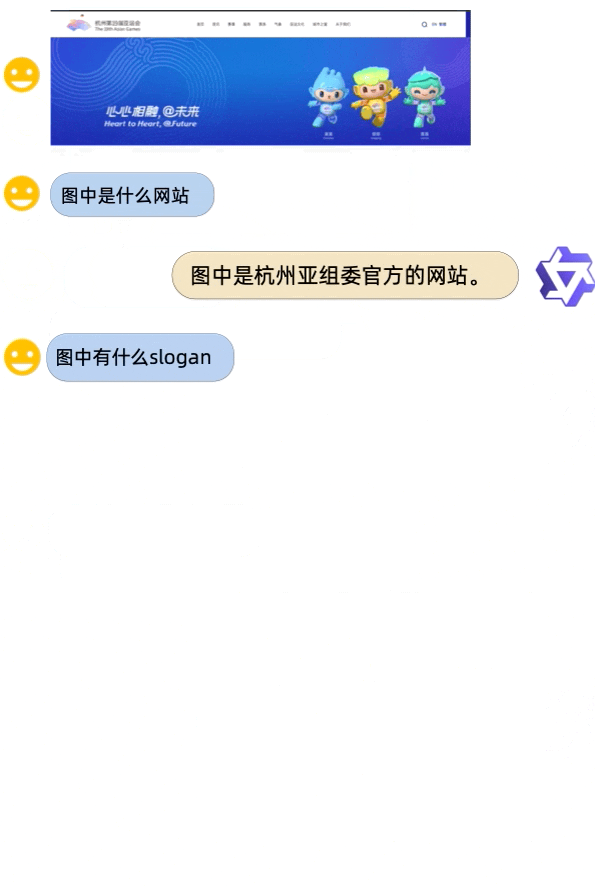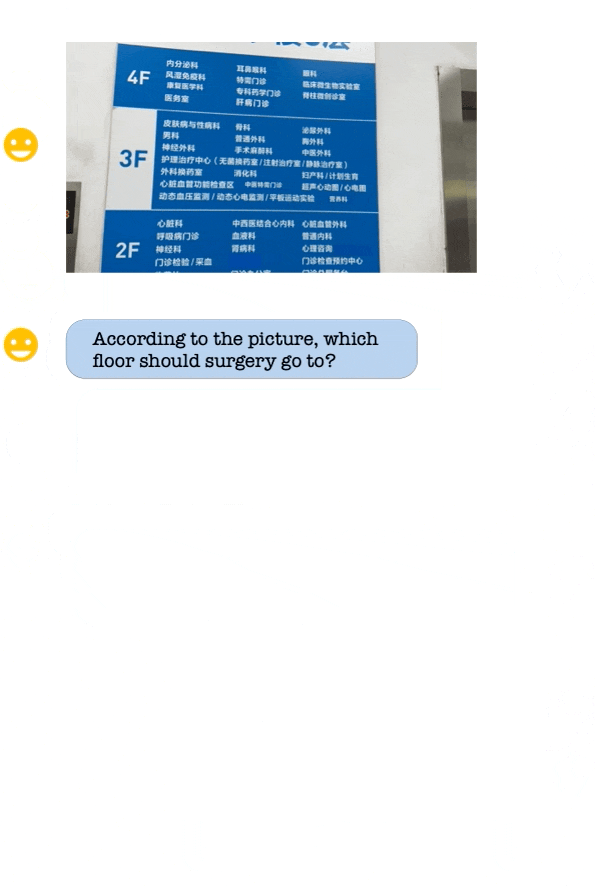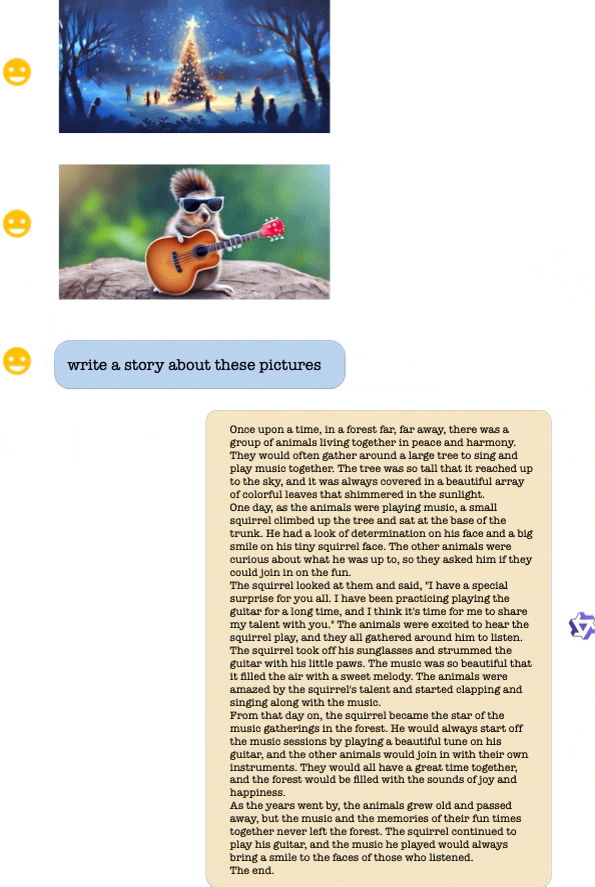
Qwen-VL-Chat 部分示例:支持多个图像输入、多轮对话、文本阅读、定位、细粒度识别和理解能力

一、Qwen-VL简介
Qwen-VL 是阿里基于语言模型Qwen-7B(LLMs),研发的大规模视觉语言模型(Large Vision Language Model, LVLM)
Qwen-VL = 大语言模型(Qwen-7B) + 视觉图片特征编码器(Openclip’s
ViT-bigG) + 位置感知视觉语言适配器(可训练Adapter)+约15亿训练数据+多轮训练
功能上:
- 支持多语言,特别是中英文对话
- 支持
多个图像输入 - 中英双语的长文本识别
- 对图片中物体定位 :能够确定与给定描述相对应的具体区域(也称 grounding)
- 相对其他视觉模型,进行对图片更多细节识别和理解
二、本地部署
下载项目到本地,也可手动下载
git clone https://github.com/QwenLM/Qwen-VL.git
2.1 基础环境安装
根据自己显卡驱动,在pytorch官方选择对应的版本: https://pytorch.org/get-started/previous-versions/
conda create -n qwen-vl python=3.10 -yconda activate qwen-vl
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia
2.1.1 其他依赖
conda activate qwen-vl
cd Qwen-VL
pip install -r requirements.txt
2.1.2 使用modelscope模型
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
pip install modelscope -U
2.2 实际测试 (运行后自动下载模型)
启动命令 --server-name 0.0.0.0 表示可局域网访问,输入ip
python web_demo_mm.py --server-name 0.0.0.0
2.2.1 下载模型界面 (约20G)
2.2.2 启动测试界面
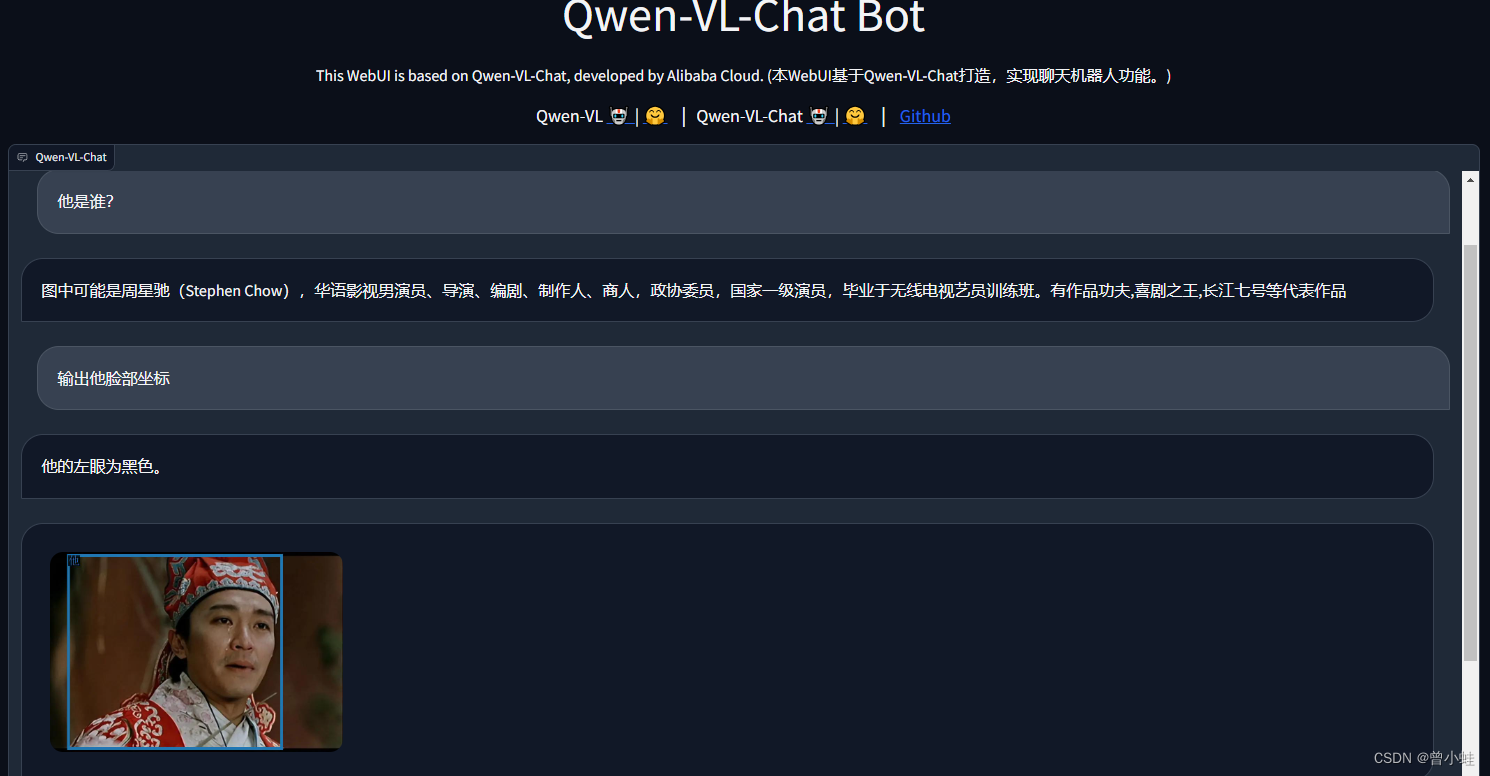
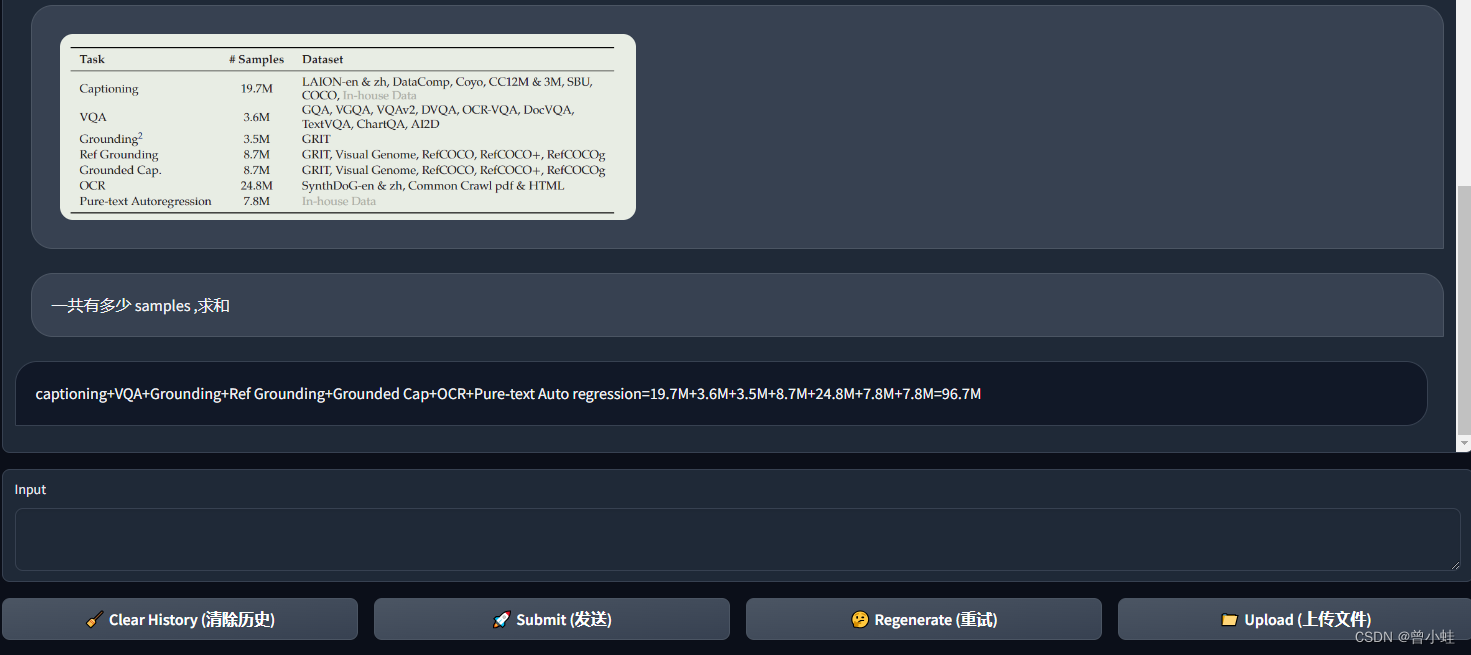
2.2.3 实测,对图表理解并求和
求和上传图中某一列。
三、如何训练?
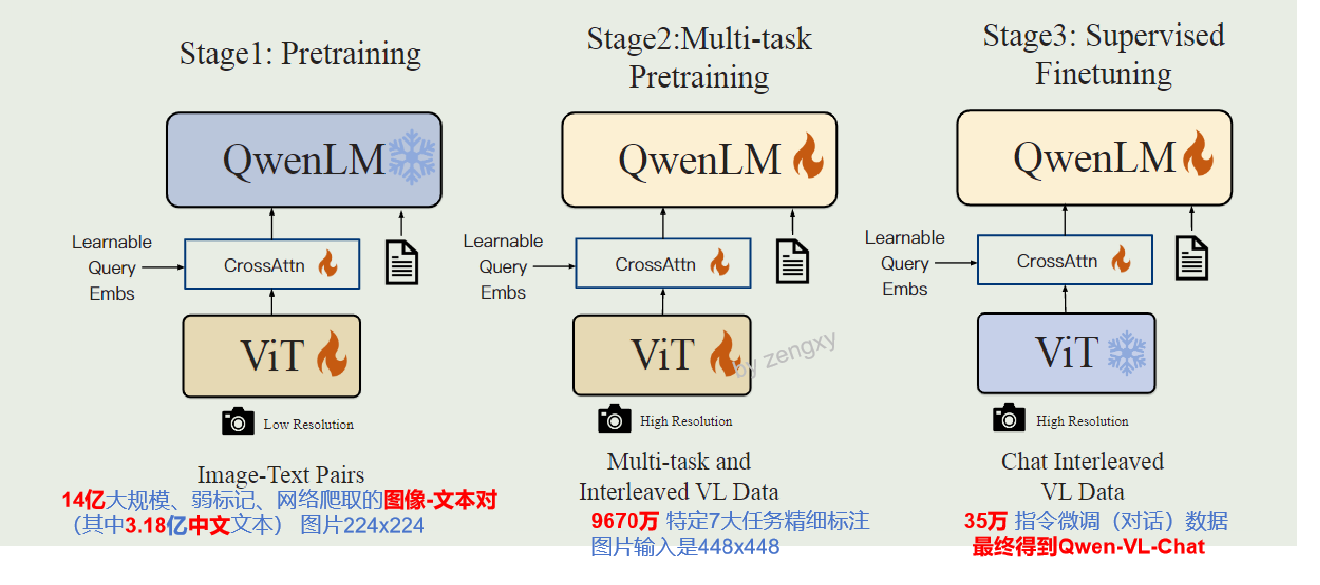
阶段一:普通预训练 (pretraining)
14亿大规模、弱标记、网络爬取的图像-文本对(其中3.18亿**中文**文本)
阶段二: 多任务任务微调 (得到Qwen-VL)
约1亿数据,7大任务,图片题词,视觉问答,位置标注、OCR等任务
阶段三: 指令微调(增强对话能力) (训练后得到Qwen-VL-Chat)
将简单的文本图像对,通过手动注释、模型生成和策略串联构建**35W**对话数据。
训练过程中混合了多模态和纯文本对话数据,以确保模型在对话能力方面的通用性
预训练阶段(Pre-training)
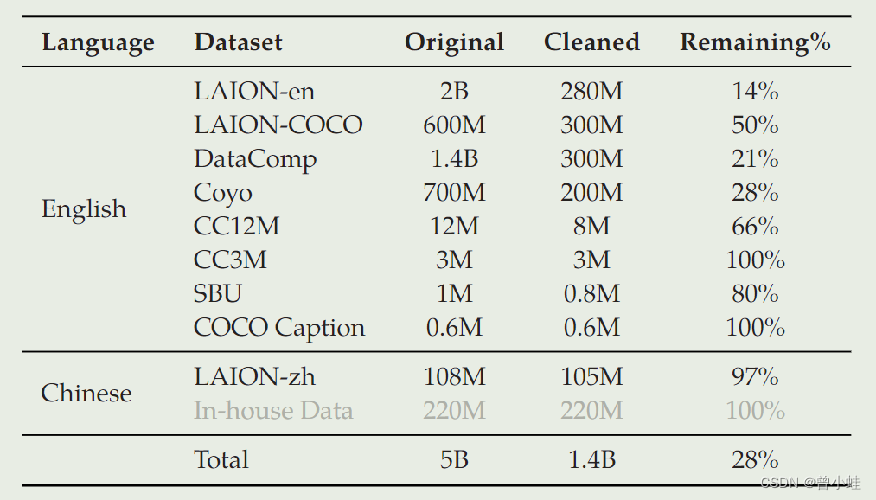
数据集从50亿数据中清洗得到14亿数据,其中中文约22.7%,3亿左右
数据集清理标注
- 删除纵横比过大的对
- 删除图像太小的对
- 删除剪辑分数过苛刻的对(特定于数据集)
- 删除包含非英语或非汉字的文本对
- 删除包含表情符号字符的文本对
- 删除文本长度过短或太长的对
- 清理文本的 HTML 标记部分
- 用某些不规则模式清理文本
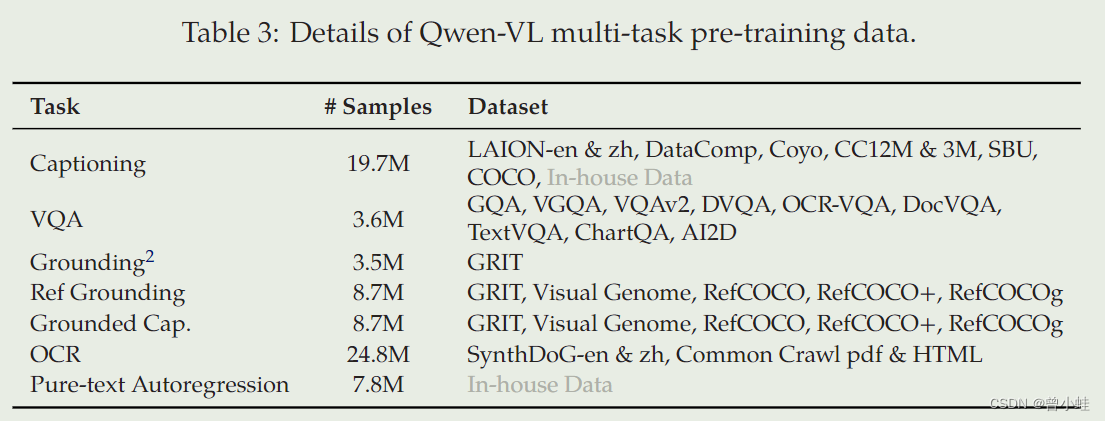
多任务预训练 (Multi-task Pre-training)
约1亿数据,7大任务,图片题词,视觉问答,位置标注、OCR等任务
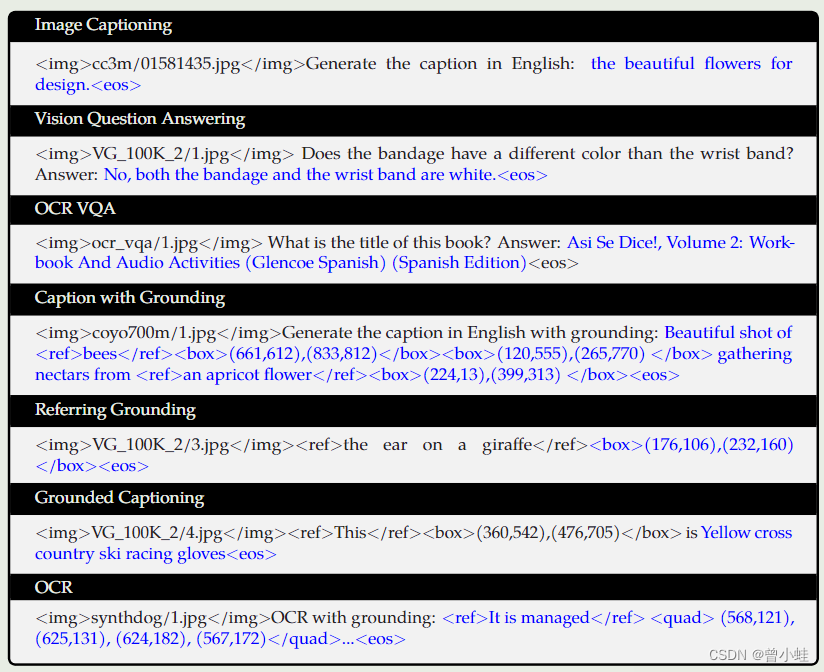
训练数据格式 (Data Format of Multi-Task Pre-training)
训练时,黑色文本作为前缀序列,没有损失,蓝色文本作为带有损失的地面真实标签。
指令微调
训练数据格式
为了更好地适应多图像对话和多个图像输入,我们在不同的图像之前添加了字符串“Picture id:”,其中 id 对应于图像输入对话的顺序。在对话格式方面,我们使用 ChatML (Openai) 格式构建我们的指令调优数据集,其中每个交互的语句都标有两个特殊标记(<im_start> 和<im_end>)以促进对话终止。

附录
有哪些版本?(商业版本)
| 模型名 | 模型简介 |
|---|---|
| Qwen-VL-Plus | 通义千问大规模视觉语言模型增强版。大幅提升细节识别能力和文字识别能力,支持超百万像素分辨率和任意长宽比规格的图像。在广泛的视觉任务上提供卓越的性能。 |
| Qwen-VL-Max | 通义千问超大规模视觉语言模型。相比增强版,再次提升视觉推理能力和指令遵循能力,提供更高的视觉感知和认知水平。在更多复杂任务上提供最佳的性能。 |