县区社保经办网站建设360官方网站网址
前言:
浏览某乎网站时发现了一个分享各种图片的博主,于是我顺手就保存了一些。但是一张一张的保存实在太麻烦了,于是我就想要某虫的手段来处理。这样保存的确是很快,但是他不识图片内容,最近又看了 mobileNet 的预训练模型,想着能让程序自己对图片分类,以下就通过例子从内容采集到分类的过程。
内容和资源的采集,反手就是某虫了。在网络上,经过近几年的营销渲染,可能首选是用 Python 做脚本。而这次是用 PHP 的 QueryList 来做采集,下面也就是采集的编码过程和踩坑解决方法,最后再对采集图片进行标注和训练。
环境:
PHP7.4
QueryList4.0
QueryList-CurlMulti
编码:
以下例子是基于 TP5.1,所以只需要安装上面两个依赖包。采集启动通过自定义命令实现,接下来分别以普通采集和多线程采集两种方式展示。
1. 普通采集
<?php/*** @Notes: 公众号:ZERO开发* @Interface getCondition* @Return mixed* @Author: bqs* @Time: 2021/4/19 15:28*/namespaceapp\common\command;usethink\console\Command;
usethink\console\Input;
usethink\console\Output;
usethink\console\input\Argument;
usethink\console\input\Option;
usethink\Db;
usethink\facade\Hook;
usethink\facade\Log;
useQL\QueryList;classQueryListSpiderSingleextendsCommand{protectedfunctionconfigure(){$this->setName('querylist:single')->setDescription('采集');}protectedfunctionexecute(Input $input, Output $output){ini_set('memory_limit', '512M');$output->writeln("=========date:" . date('Y-m-d H:i:s') . "===============");// 北桥苏奥特曼//$slImgsUrl = "https://zhuanlan.zhihu.com/p/377571373";$slImgsUrl = "https://zhuanlan.zhihu.com/p/344680014";// 原生query_list$list = QueryList::get($slImgsUrl)->find('.RichText')->find('noscript')->find('img')->attrs('src');$path = 'E:\2setsoft\1dev\phpstudy_pro\WWW\4test\tensorflowJs\js-ml-code\t7\动漫分类\train\奥特曼\\';foreach($list as $key => $value) {$index = $key + 1 + 42;$filename = $index < 10 ? str_pad($index, 2, "0", STR_PAD_LEFT) : $index;$filend = pathinfo($value, PATHINFO_EXTENSION);$file = file_get_contents($value);file_put_contents($path . $filename . "." . $filend, $file);$output->writeln($index . "--" . $value . "已保存--");}$output->writeln("============date:" .date("Y-m-d H:i:s") . "采集完成==============");}}2. 多线程采集
<?php/*** @Notes: 文件描述* @Interface getCondition* @Return mixed* @Author: bqs* @Time: 2021/4/19 15:28*/namespaceapp\common\command;usethink\console\Command;
usethink\console\Input;
usethink\console\Output;
usethink\console\input\Argument;
usethink\console\input\Option;
usethink\Db;
usethink\facade\Hook;
usethink\facade\Log;
useQL\QueryList;
useQL\Ext\CurlMulti;classQueryListSpiderextendsCommand{protectedfunctionconfigure(){$this->setName('query:list')->setDescription('采集');}protectedfunctionexecute(Input $input, Output $output){ini_set('memory_limit', '512M');$output->writeln("=========date:" . date('Y-m-d H:i:s') . "===============");// 地址与目录映射$dirMap = ["假面骑士" => "https://zhuanlan.zhihu.com/p/376119915","龙珠" => "https://zhuanlan.zhihu.com/p/340048917","火影忍者" => ["https://zhuanlan.zhihu.com/p/352717188", "https://zhuanlan.zhihu.com/p/393213201", "https://zhuanlan.zhihu.com/p/358228745"],"海贼王" => ["https://zhuanlan.zhihu.com/p/357683518", "https://zhuanlan.zhihu.com/p/338160632"]];// 采集地址$multiArr = [];$multiArr = array_reduce(array_values($dirMap), function($res, $value){$res = array_merge($res, (array)$value);return $res;}, []);// 采集映射$multiMap = [];foreach($dirMap as $key => $value) {if (!is_array($value)) {$multiMap[$value] = $key;} else {$temp = array_fill_keys($value, $key);$multiMap = array_merge($multiMap, $temp);}}// 开始使用多线程采集$ql = QueryList::use (CurlMulti::class);$ql->curlMulti($multiArr)->success(function(QueryList $ql, CurlMulti $curl, $r)use($multiMap){$path = 'E:\2setsoft\1dev\phpstudy_pro\WWW\4test\tensorflowJs\js-ml-code\t7\动漫分类\train\\';$queryUrl = $r['info']['url'];$className = $multiMap[$queryUrl] ?? "";$targetDir = $path . $className;$path = $targetDir . '\\';$endFileIndex = 0;$existFileList = $this->scanFile($targetDir);if ($existFileList) {// 取出所有数字文件名最大值$endFileName = max($existFileList);$endFileIndex = explode(".", $endFileName)[0];}$data = $ql->find('.RichText')->find('noscript')->find('img')->attrs('src');foreach($data as $key => $value) {$index = $key + 1 + $endFileIndex;$filename = $index < 10 ? str_pad($index, 2, "0", STR_PAD_LEFT) : $index;$filend = pathinfo($value, PATHINFO_EXTENSION);$file = file_get_contents($value);file_put_contents($path . $filename . "." . $filend, $file);}})// 每个任务失败回调->error(function($errorInfo, CurlMulti $curl){echo"Current url:{$errorInfo['info']['url']} \r\n";print_r($errorInfo['error']);})->start([// 最大并发数'maxThread' => 10,// 错误重试次数'maxTry' => 5,]);$output->writeln("============date:" . date("Y-m-d H:i:s") . "采集完成==============");}// 扫描目录下所有文件protectedfunctionscanFile($path){$result = [];$files = scandir($path);foreach ($files as $file) {if ($file != '.' && $file != '..') {if (is_dir($path . '/' . $file)) {$this->scanFile($path . '/' . $file);} else {$result[] = basename($file);}}}return $result;}}问题解决:
由于普通采集的请求使用 GuzzleHttp 客户端,而多线程采集是 CURL,所以运行时报 curl 状态码 60 错误。
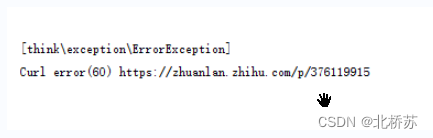
1. 解决方法:
(1). 下载 cacert
下载地址:https://curl.haxx.se/ca/cacert.pem
(2). 修改 php.ini , 并重启
在 php.ini 中找到 curl.cainfo 改为文件的绝对路径如:curl.cainfo =E:\2setsoft\1dev\phpstudy_pro\Extensions\php\php7.4.3nts\cacert.pem
图片训练:
以上的图片已经采集的差不多了,因为博主的图片有限,我也没有再去其他地方找,整个文件夹下的图片在 200 张左右。按理说图片当然是越多越好,但是整个分类标注起来耗时(看文章的配图,应该已经知道有哪几类了吧),所以就这样了。最后就是读取图片转换 Tensor 进行训练,后一篇再具体介绍吧,提醒一下。下一篇需要提前安装 Node, Http-Server,Parcel 工具。