网站 成品下载seo关键词排行优化教程
文章目录
- 自定义InputFormat
- 1. 需求
- 2. 输入数据
- 3. 期望输出文件格式
- 4. 需求分析
- 5. 代码实现
- WholeFileInputformat
- WholeRecordReader☆☆
- SequenceFileMapper
- SequenceFileReducer
- ☆
自定义InputFormat
在企业开发中,Hadoop框架自带的InputFormat类型不能满足所有应用场景,需要自定义InputFormat来解决实际问题。
自定义InputFormat步骤如下
- 自定义一个类继承FileInputFormat。
- 改写RecordReader,实现一次读取一个完整文件封装为KV。
- 在输出时
使用SequenceFileOutPutFormat输出合并文件。无论HDFS还是MapReduce,在处理小文件时效率都非常低,但又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义InputFormat实现小文件的合并。
1. 需求
将多个小文件合并成一个SequenceFile文件(
SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为value。
2. 输入数据
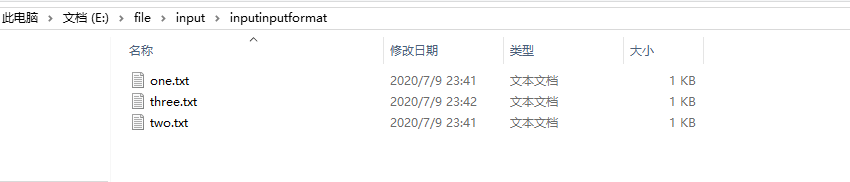
3. 期望输出文件格式
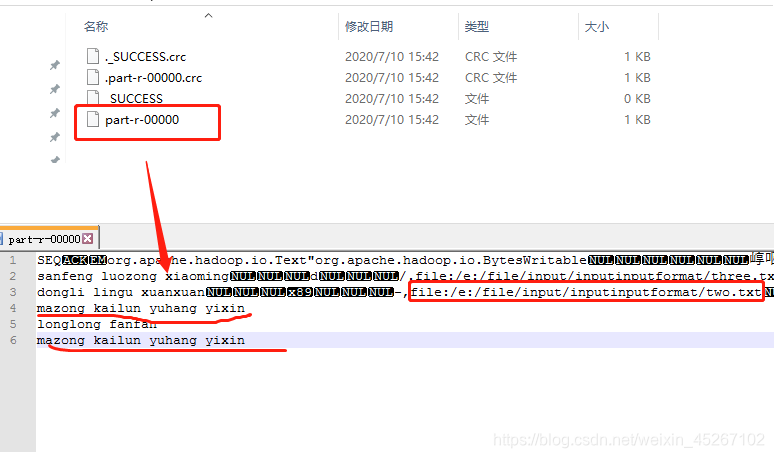
4. 需求分析

5. 代码实现
WholeFileInputformat
/*** @Date 2020/7/9 23:10* @Version 10.21* @Author DuanChaojie*/
public class WholeFileInputformat extends FileInputFormat<Text,BytesWritable> {@Overrideprotected boolean isSplitable(JobContext context, Path filename) {return false;}@Overridepublic RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {WholeRecordReader recordReader = new WholeRecordReader();recordReader.initialize(split,context);return recordReader;}
}
WholeRecordReader☆☆
/*** @Date 2020/7/9 23:23* @Version 10.21* @Author DuanChaojie*/
public class WholeRecordReader extends RecordReader {private Configuration conf;private FileSplit split;private boolean isProgress= true;private Text k = new Text();private BytesWritable v = new BytesWritable();@Overridepublic void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {this.split = (FileSplit)split;conf = context.getConfiguration();}/*** 核心逻辑* @return* @throws IOException* @throws InterruptedException*/@Overridepublic boolean nextKeyValue() throws IOException, InterruptedException {if (isProgress) {// 1.定义缓冲区byte[] contents = new byte[(int) split.getLength()];FileSystem fs = null;FSDataInputStream fis = null;try {// 2. 获取文件系统Path path = split.getPath();fs = path.getFileSystem(conf);// 3.读取数据fis = fs.open(path);// 4.读取文件内容IOUtils.readFully(fis, contents, 0, contents.length);// 5.输出文件内容v.set(contents,0,contents.length);// 6.获取文件路径及名称String name = split.getPath().toString();// 7,设置输出的key值k.set(name);} catch (Exception e) {e.printStackTrace();}finally {IOUtils.closeStream(fis);}isProgress = false;return true;}return false;}@Overridepublic Object getCurrentKey() throws IOException, InterruptedException {return k;}@Overridepublic Object getCurrentValue() throws IOException, InterruptedException {return v;}@Overridepublic float getProgress() throws IOException, InterruptedException {return 0;}@Overridepublic void close() throws IOException {}
}
SequenceFileMapper
/*** @Date 2020/7/9 23:36* @Version 10.21* @Author DuanChaojie*/
public class SequenceFileMapper extends Mapper<Text, BytesWritable, Text,BytesWritable> {@Overrideprotected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {context.write(key,value);}
}
SequenceFileReducer
public class SequenceFileReducer extends Reducer<Text, BytesWritable, Text,BytesWritable> {@Overrideprotected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException, InterruptedException {context.write(key,values.iterator().next());}
}
public class SequenceFileDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 输入输出路径需要根据自己电脑上实际的输入输出路径设置args = new String[] { "e:/file/input/inputinputformat", "e:/file/output2" };// 1 获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置jar包存储位置、关联自定义的mapper和reducerjob.setJarByClass(SequenceFileDriver.class);job.setMapperClass(SequenceFileMapper.class);job.setReducerClass(SequenceFileReducer.class);// 3 设置map输出端的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(BytesWritable.class);// 4 设置最终输出端的kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(BytesWritable.class);// 5 设置输入输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 6设置输入的inputFormatjob.setInputFormatClass(WholeFileInputformat.class);// 7设置输出的outputFormatjob.setOutputFormatClass(SequenceFileOutputFormat.class);// 8提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
完全与期望输出结果一致!